 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Source Separation Using Latent Variational Block-Wise Disentanglement
Feb 08, 2024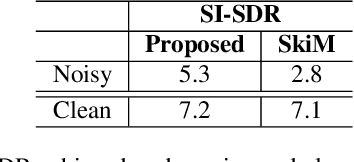
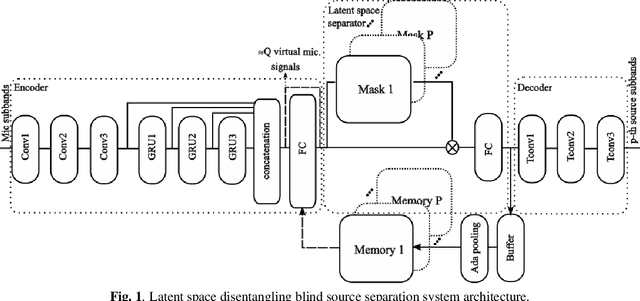
While neural network approaches have made significant strides in resolving classical signal processing problems, it is often the case that hybrid approaches that draw insight from both signal processing and neural networks produce more complete solutions. In this paper, we present a hybrid classical digital signal processing/deep neural network (DSP/DNN) approach to source separation (SS) highlighting the theoretical link between variational autoencoder and classical approaches to SS. We propose a system that transforms the single channel under-determined SS task to an equivalent multichannel over-determined SS problem in a properly designed latent space. The separation task in the latent space is treated as finding a variational block-wise disentangled representation of the mixture. We show empirically, that the design choices and the variational formulation of the task at hand motivated by the classical signal processing theoretical results lead to robustness to unseen out-of-distribution data and reduction of the overfitting risk. To address the resulting permutation issue we explicitly incorporate a novel differentiable permutation loss function and augment the model with a memory mechanism to keep track of the statistics of the individual sources.
Real-time Stereo Speech Enhancement with Spatial-Cue Preservation based on Dual-Path Structure
Feb 01, 2024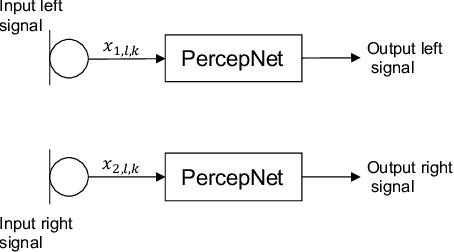



We introduce a real-time, multichannel speech enhancement algorithm which maintains the spatial cues of stereo recordings including two speech sources. Recognizing that each source has unique spatial information, our method utilizes a dual-path structure, ensuring the spatial cues remain unaffected during enhancement by applying source-specific common-band gain. This method also seamlessly integrates pretrained monaural speech enhancement, eliminating the need for retraining on stereo inputs. Source separation from stereo mixtures is achieved via spatial beamforming, with the steering vector for each source being adaptively updated using post-enhancement output signal. This ensures accurate tracking of the spatial information. The final stereo output is derived by merging the spatial images of the enhanced sources, with its efficacy not heavily reliant on the separation performance of the beamforming. The algorithm runs in real-time on 10-ms frames with a 40 ms of look-ahead. Evaluations reveal its effectiveness in enhancing speech and preserving spatial cues in both fully and sparsely overlapped mixtures.
Refinement of Direction of Arrival Estimators by Majorization-Minimization Optimization on the Array Manifold
Jun 02, 2021
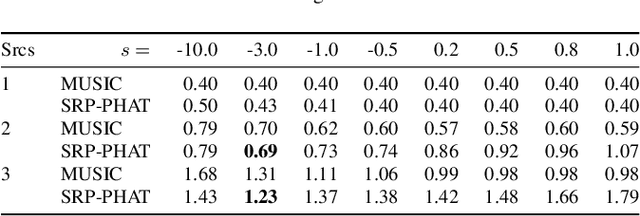
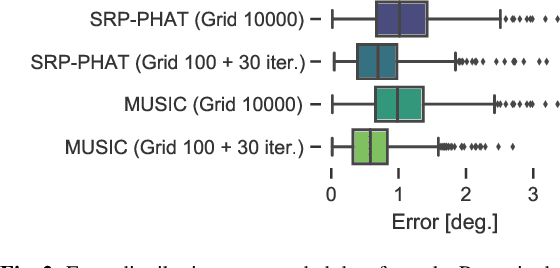
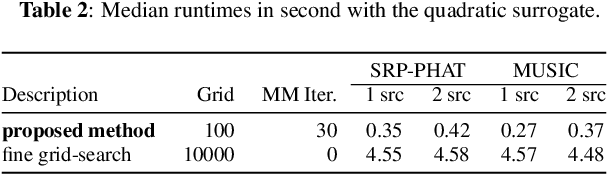
We propose a generalized formulation of direction of arrival estimation that includes many existing methods such as steered response power, subspace, coherent and incoherent, as well as speech sparsity-based methods. Unlike most conventional methods that rely exclusively on grid search, we introduce a continuous optimization algorithm to refine DOA estimates beyond the resolution of the initial grid. The algorithm is derived from the majorization-minimization (MM) technique. We derive two surrogate functions, one quadratic and one linear. Both lead to efficient iterative algorithms that do not require hyperparameters, such as step size, and ensure that the DOA estimates never leave the array manifold, without the need for a projection step. In numerical experiments, we show that the accuracy after a few iterations of the MM algorithm nearly removes dependency on the resolution of the initial grid used. We find that the quadratic surrogate function leads to very fast convergence, but the simplicity of the linear algorithm is very attractive, and the performance gap small.
* 5 pages, 2 figures, 2 tables. Presented at IEEE ICASSP 2021
Label-Synchronous Speech-to-Text Alignment for ASR Using Forward and Backward Transformers
Apr 21, 2021
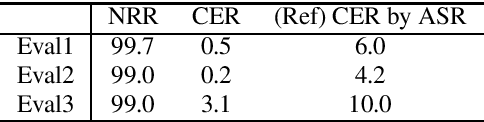
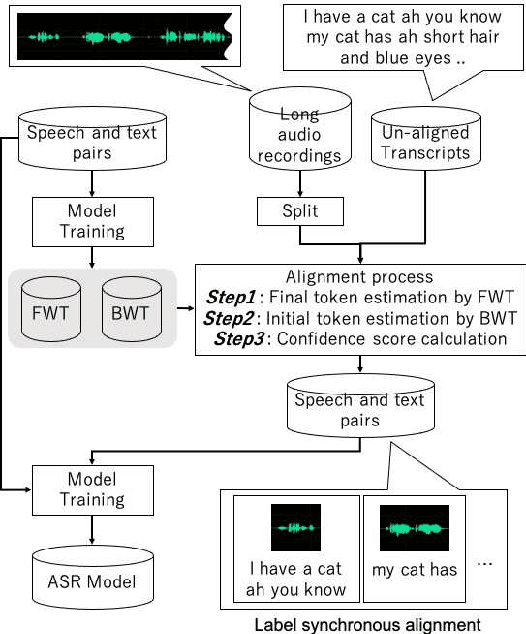
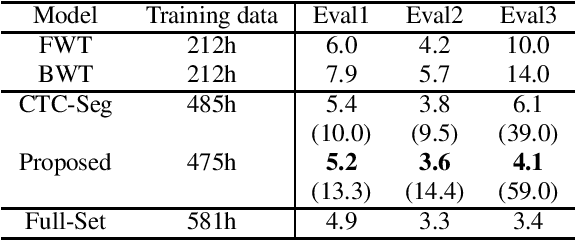
This paper proposes a novel label-synchronous speech-to-text alignment technique for automatic speech recognition (ASR). The speech-to-text alignment is a problem of splitting long audio recordings with un-aligned transcripts into utterance-wise pairs of speech and text. Unlike conventional methods based on frame-synchronous prediction, the proposed method re-defines the speech-to-text alignment as a label-synchronous text mapping problem. This enables an accurate alignment benefiting from the strong inference ability of the state-of-the-art attention-based encoder-decoder models, which cannot be applied to the conventional methods. Two different Transformer models named forward Transformer and backward Transformer are respectively used for estimating an initial and final tokens of a given speech segment based on end-of-sentence prediction with teacher-forcing. Experiments using the corpus of spontaneous Japanese (CSJ) demonstrate that the proposed method provides an accurate utterance-wise alignment, that matches the manually annotated alignment with as few as 0.2% errors. It is also confirmed that a Transformer-based hybrid CTC/Attention ASR model using the aligned speech and text pairs as an additional training data reduces character error rates relatively up to 59.0%, which is significantly better than 39.0% reduction by a conventional alignment method based on connectionist temporal classification model.
Joint Dereverberation and Separation with Iterative Source Steering
Feb 12, 2021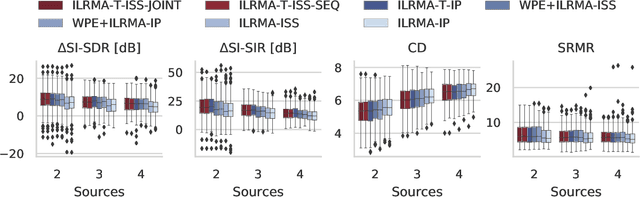
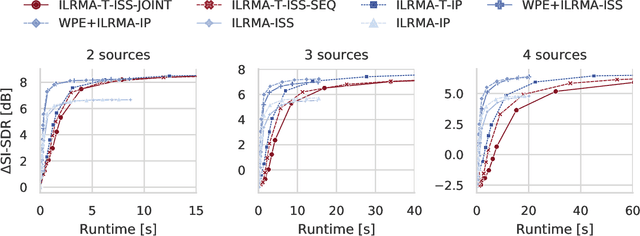
We propose a new algorithm for joint dereverberation and blind source separation (DR-BSS). Our work builds upon the IRLMA-T framework that applies a unified filter combining dereverberation and separation. One drawback of this framework is that it requires several matrix inversions, an operation inherently costly and with potential stability issues. We leverage the recently introduced iterative source steering (ISS) updates to propose two algorithms mitigating this issue. Albeit derived from first principles, the first algorithm turns out to be a natural combination of weighted prediction error (WPE) dereverberation and ISS-based BSS, applied alternatingly. In this case, we manage to reduce the number of matrix inversion to only one per iteration and source. The second algorithm updates the ILRMA-T matrix using only sequential ISS updates requiring no matrix inversion at all. Its implementation is straightforward and memory efficient. Numerical experiments demonstrate that both methods achieve the same final performance as ILRMA-T in terms of several relevant objective metrics. In the important case of two sources, the number of iterations required is also similar.