 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Synchronous Speech-to-Text Alignment for ASR Using Forward and Backward Transformers
Paper and Code
Apr 21, 2021
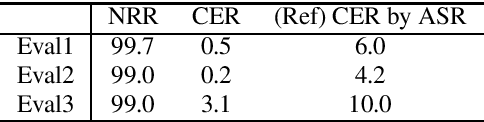
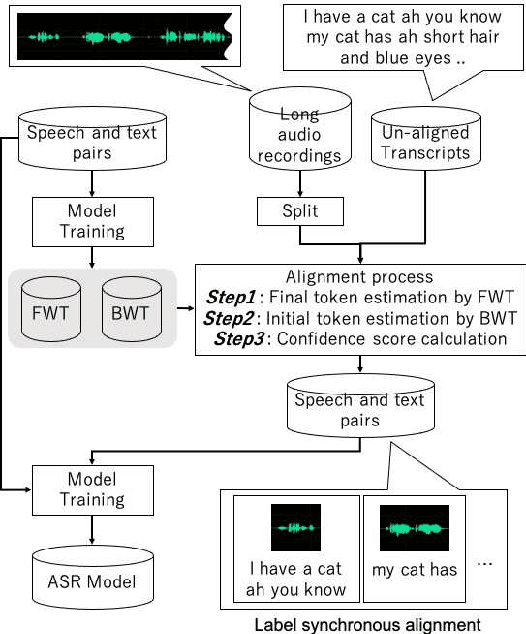
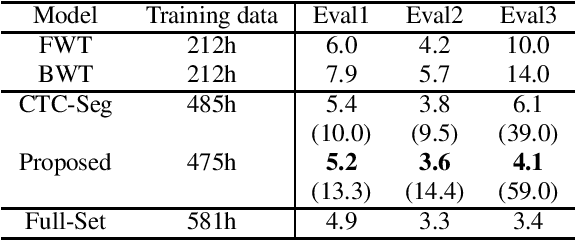
This paper proposes a novel label-synchronous speech-to-text alignment technique for automatic speech recognition (ASR). The speech-to-text alignment is a problem of splitting long audio recordings with un-aligned transcripts into utterance-wise pairs of speech and text. Unlike conventional methods based on frame-synchronous prediction, the proposed method re-defines the speech-to-text alignment as a label-synchronous text mapping problem. This enables an accurate alignment benefiting from the strong inference ability of the state-of-the-art attention-based encoder-decoder models, which cannot be applied to the conventional methods. Two different Transformer models named forward Transformer and backward Transformer are respectively used for estimating an initial and final tokens of a given speech segment based on end-of-sentence prediction with teacher-forcing. Experiments using the corpus of spontaneous Japanese (CSJ) demonstrate that the proposed method provides an accurate utterance-wise alignment, that matches the manually annotated alignment with as few as 0.2% errors. It is also confirmed that a Transformer-based hybrid CTC/Attention ASR model using the aligned speech and text pairs as an additional training data reduces character error rates relatively up to 59.0%, which is significantly better than 39.0% reduction by a conventional alignment method based on connectionist temporal classification model.