 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiBA: Diagonal and Binary Matrix Approximation for Neural Network Weight Compression
May 07, 2026In this paper, we propose DiBA (Diagonal and Binary Matrix Approximation), a compact matrix factorization for neural network weight compression. Many components of modern networks, including linear layers, $1\times1$ convolutions, attention projections, and embedding layers, have dense matrix weights. DiBA approximates $A\in\mathbb{R}^{m\times n}$ by $\widehat A=D_1B_1D_2B_2D_3$, where $D_1,D_2,D_3$ are diagonal matrices and $B_1,B_2$ are $0/1$ binary matrices. The intermediate dimension $k$ controls the trade-off between theoretical storage and approximation accuracy. For matrix-vector products, DiBA decomposes dense multiplication into three element-wise scaling operations and two binary mixing operations, reducing the floating-point multiplication count from $mn$ to $m+k+n$. For optimization, we introduce DiBA-Greedy, an alternating solver that combines closed-form least-squares updates for the diagonal factors with exact one-bit improvement tests for the binary factors. We also introduce DiBARD (DiBA with Retuning only Diagonal factors), which replaces dense-matrix layers by DiBA factors, freezes the binary matrices, and retunes only the diagonal entries on downstream data. This preserves compact binary mixing without discrete search during adaptation. On 40 dense weight matrices extracted from public pretrained models, DiBA-Greedy yields consistent SNR improvements as the theoretical storage ratio increases. After DiBA replacement in two component-replacement studies, DiBARD improves DistilBERT/WikiText masked-token accuracy from 0.4447 to 0.5210 and Speech Commands test accuracy for an Audio Spectrogram Transformer from 0.7684 to 0.9781 without reoptimizing the binary factors.
Description and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
Rethinking Masking Strategies for Masked Prediction-based Audio Self-supervised Learning
Mar 25, 2026Since the introduction of Masked Autoencoders, various improvements to masking techniques have been explored. In this paper, we rethink masking strategies for audio representation learning using masked prediction-based self-supervised learning (SSL) on general audio spectrograms. While recent informed masking techniques have attracted attention, we observe that they incur substantial computational overhead. Motivated by this observation, we propose dispersion-weighted masking (DWM), a lightweight masking strategy that leverages the spectral sparsity inherent in the frequency structure of audio content. Our experiments show that inverse block masking, commonly used in recent SSL frameworks, improves audio event understanding performance while introducing a trade-off in generalization. The proposed DWM alleviates these limitations and computational complexity, leading to consistent performance improvements. This work provides practical guidance on masking strategy design for masked prediction-based audio representation learning.
What Do Neurons Listen To? A Neuron-level Dissection of a General-purpose Audio Model
Feb 17, 2026In this paper, we analyze the internal representations of a general-purpose audio self-supervised learning (SSL) model from a neuron-level perspective. Despite their strong empirical performance as feature extractors, the internal mechanisms underlying the robust generalization of SSL audio models remain unclear. Drawing on the framework of mechanistic interpretability, we identify and examine class-specific neurons by analyzing conditional activation patterns across diverse tasks. Our analysis reveals that SSL models foster the emergence of class-specific neurons that provide extensive coverage across novel task classes. These neurons exhibit shared responses across different semantic categories and acoustic similarities, such as speech attributes and musical pitch. We also confirm that these neurons have a functional impact on classification performance. To our knowledge, this is the first systematic neuron-level analysis of a general-purpose audio SSL model, providing new insights into its internal representation.
Fast Swap-Based Element Selection for Multiplication-Free Dimension Reduction
Feb 14, 2026In this paper, we propose a fast algorithm for element selection, a multiplication-free form of dimension reduction that produces a dimension-reduced vector by simply selecting a subset of elements from the input. Dimension reduction is a fundamental technique for reducing unnecessary model parameters, mitigating overfitting, and accelerating training and inference. A standard approach is principal component analysis (PCA), but PCA relies on matrix multiplications; on resource-constrained systems, the multiplication count itself can become a bottleneck. Element selection eliminates this cost because the reduction consists only of selecting elements, and thus the key challenge is to determine which elements should be retained. We evaluate a candidate subset through the minimum mean-squared error of linear regression that predicts a target vector from the selected elements, where the target may be, for example, a one-hot label vector in classification. When an explicit target is unavailable, the input itself can be used as the target, yielding a reconstruction-based criterion. The resulting optimization is combinatorial, and exhaustive search is impractical. To address this, we derive an efficient formula for the objective change caused by swapping a selected and an unselected element, using the matrix inversion lemma, and we perform a swap-based local search that repeatedly applies objective-decreasing swaps until no further improvement is possible. Experiments on MNIST handwritten-digit images demonstrate the effectiveness of the proposed method.
Incremental Averaging Method to Improve Graph-Based Time-Difference-of-Arrival Estimation
Jul 09, 2025Estimating the position of a speech source based on time-differences-of-arrival (TDOAs) is often adversely affected by background noise and reverberation. A popular method to estimate the TDOA between a microphone pair involves maximizing a generalized cross-correlation with phase transform (GCC-PHAT) function. Since the TDOAs across different microphone pairs satisfy consistency relations, generally only a small subset of microphone pairs are used for source position estimation. Although the set of microphone pairs is often determined based on a reference microphone, recently a more robust method has been proposed to determine the set of microphone pairs by computing the minimum spanning tree (MST) of a signal graph of GCC-PHAT function reliabilities. To reduce the influence of noise and reverberation on the TDOA estimation accuracy, in this paper we propose to compute the GCC-PHAT functions of the MST based on an average of multiple cross-power spectral densities (CPSDs) using an incremental method. In each step of the method, we increase the number of CPSDs over which we average by considering CPSDs computed indirectly via other microphones from previous steps. Using signals recorded in a noisy and reverberant laboratory with an array of spatially distributed microphones, the performance of the proposed method is evaluated in terms of TDOA estimation error and 2D source position estimation error. Experimental results for different source and microphone configurations and three reverberation conditions show that the proposed method considering multiple CPSDs improves the TDOA estimation and source position estimation accuracy compared to the reference microphone- and MST-based methods that rely on a single CPSD as well as steered-response power-based source position estimation.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025


Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
Mel-Spectrogram Inversion via Alternating Direction Method of Multipliers
Jan 09, 2025Signal reconstruction from its mel-spectrogram is known as mel-spectrogram inversion and has many applications, including speech and foley sound synthesis. In this paper, we propose a mel-spectrogram inversion method based on a rigorous optimization algorithm. To reconstruct a time-domain signal with inverse short-time Fourier transform (STFT), both full-band STFT magnitude and phase should be predicted from a given mel-spectrogram. Their joint estimation has outperformed the cascaded full-band magnitude prediction and phase reconstruction by preventing error accumulation. However, the existing joint estimation method requires many iterations, and there remains room for performance improvement. We present an alternating direction method of multipliers (ADMM)-based joint estimation method motivated by its success in various nonconvex optimization problems including phase reconstruction. An efficient update of each variable is derived by exploiting the conditional independence among the variables. Our experiments demonstrate the effectiveness of the proposed method on speech and foley sounds.
Guided Masked Self-Distillation Modeling for Distributed Multimedia Sensor Event Analysis
Apr 12, 2024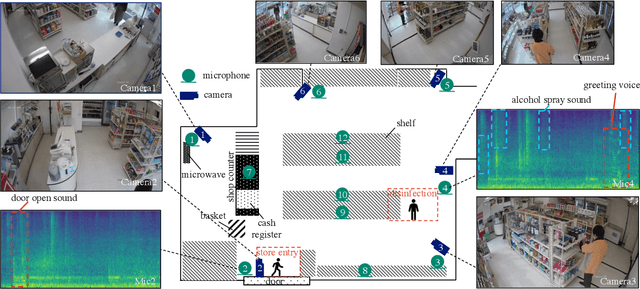
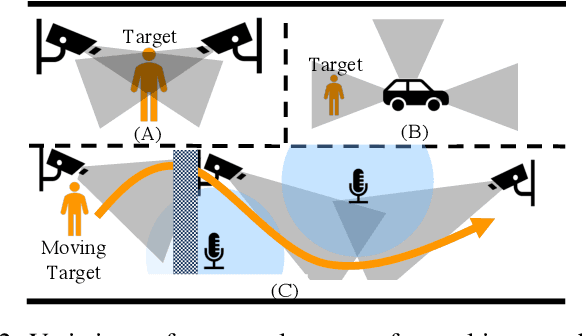

Observations with distributed sensors are essential in analyzing a series of human and machine activities (referred to as 'events' in this paper) in complex and extensive real-world environments. This is because the information obtained from a single sensor is often missing or fragmented in such an environment; observations from multiple locations and modalities should be integrated to analyze events comprehensively. However, a learning method has yet to be established to extract joint representations that effectively combine such distributed observations. Therefore, we propose Guided Masked sELf-Distillation modeling (Guided-MELD) for inter-sensor relationship modeling. The basic idea of Guided-MELD is to learn to supplement the information from the masked sensor with information from other sensors needed to detect the event. Guided-MELD is expected to enable the system to effectively distill the fragmented or redundant target event information obtained by the sensors without being overly dependent on any specific sensors. To validate the effectiveness of the proposed method in novel tasks of distributed multimedia sensor event analysis, we recorded two new datasets that fit the problem setting: MM-Store and MM-Office. These datasets consist of human activities in a convenience store and an office, recorded using distributed cameras and microphones. Experimental results on these datasets show that the proposed Guided-MELD improves event tagging and detection performance and outperforms conventional inter-sensor relationship modeling methods. Furthermore, the proposed method performed robustly even when sensors were reduced.
Signal Reconstruction from Mel-spectrogram Based on Bi-level Consistency of Full-band Magnitude and Phase
Jul 23, 2023We propose an optimization-based method for reconstructing a time-domain signal from a low-dimensional spectral representation such as a mel-spectrogram. Phase reconstruction has been studied to reconstruct a time-domain signal from the full-band short-time Fourier transform (STFT) magnitude. The Griffin-Lim algorithm (GLA) has been widely used because it relies only on the redundancy of STFT and is applicable to various audio signals. In this paper, we jointly reconstruct the full-band magnitude and phase by considering the bi-level relationships among the time-domain signal, its STFT coefficients, and its mel-spectrogram. The proposed method is formulated as a rigorous optimization problem and estimates the full-band magnitude based on the criterion used in GLA. Our experiments demonstrate the effectiveness of the proposed method on speech, music, and environmental signals.