 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2D-CLAP: Masked Modeling Duo Meets CLAP for Learning General-purpose Audio-Language Representation
Jun 04, 2024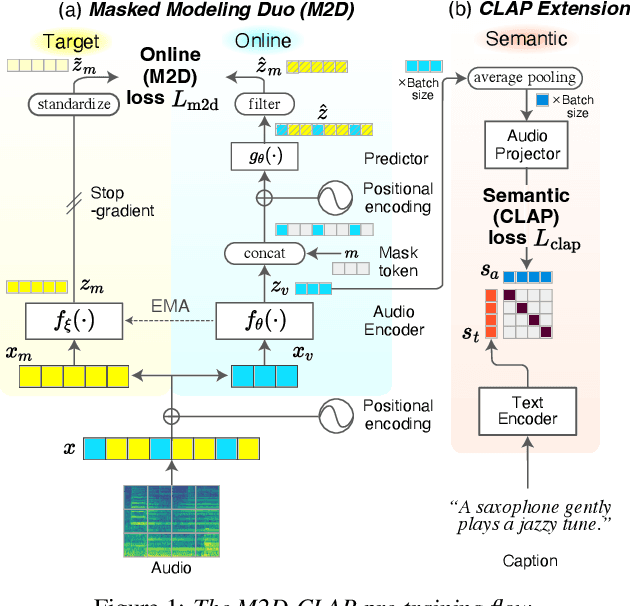



Contrastive language-audio pre-training (CLAP) enables zero-shot (ZS) inference of audio and exhibits promising performance in several classification tasks. However, conventional audio representations are still crucial for many tasks where ZS is not applicable (e.g., regression problems). Here, we explore a new representation, a general-purpose audio-language representation, that performs well in both ZS and transfer learning. To do so, we propose a new method, M2D-CLAP, which combines self-supervised learning Masked Modeling Duo (M2D) and CLAP. M2D learns an effective representation to model audio signals, and CLAP aligns the representation with text embedding. As a result, M2D-CLAP learns a versatile representation that allows for both ZS and transfer learning. Experiments show that M2D-CLAP performs well on linear evaluation, fine-tuning, and ZS classification with a GTZAN state-of-the-art of 75.17%, thus achieving a general-purpose audio-language representation.
Refining Knowledge Transfer on Audio-Image Temporal Agreement for Audio-Text Cross Retrieval
Mar 16, 2024



The aim of this research is to refine knowledge transfer on audio-image temporal agreement for audio-text cross retrieval. To address the limited availability of paired non-speech audio-text data, learning methods for transferring the knowledge acquired from a large amount of paired audio-image data to shared audio-text representation have been investigated, suggesting the importance of how audio-image co-occurrence is learned. Conventional approaches in audio-image learning assign a single image randomly selected from the corresponding video stream to the entire audio clip, assuming their co-occurrence. However, this method may not accurately capture the temporal agreement between the target audio and image because a single image can only represent a snapshot of a scene, though the target audio changes from moment to moment. To address this problem, we propose two methods for audio and image matching that effectively capture the temporal information: (i) Nearest Match wherein an image is selected from multiple time frames based on similarity with audio, and (ii) Multiframe Match wherein audio and image pairs of multiple time frames are used. Experimental results show that method (i) improves the audio-text retrieval performance by selecting the nearest image that aligns with the audio information and transferring the learned knowledge. Conversely, method (ii) improves the performance of audio-image retrieval while not showing significant improvements in audio-text retrieval performance. These results indicate that refining audio-image temporal agreement may contribute to better knowledge transfer to audio-text retrieval.
Joint Analysis of Acoustic Scenes and Sound Events with Weakly labeled Data
Jul 10, 2022



Considering that acoustic scenes and sound events are closely related to each other, in some previous papers, a joint analysis of acoustic scenes and sound events utilizing multitask learning (MTL)-based neural networks was proposed. In conventional methods, a strongly supervised scheme is applied to sound event detection in MTL models, which requires strong labels of sound events in model training; however, annotating strong event labels is quite time-consuming. In this paper, we thus propose a method for the joint analysis of acoustic scenes and sound events based on the MTL framework with weak labels of sound events. In particular, in the proposed method, we introduce the multiple-instance learning scheme for weakly supervised training of sound event detection and evaluate four pooling functions, namely, max pooling, average pooling, exponential softmax pooling, and attention pooling. Experimental results obtained using parts of the TUT Acoustic Scenes 2016/2017 and TUT Sound Events 2016/2017 datasets show that the proposed MTL-based method with weak labels outperforms the conventional single-task-based scene classification and event detection models with weak labels in terms of both the scene classification and event detection performances.
How Information on Acoustic Scenes and Sound Events Mutually Benefits Event Detection and Scene Classification Tasks
Apr 05, 2022

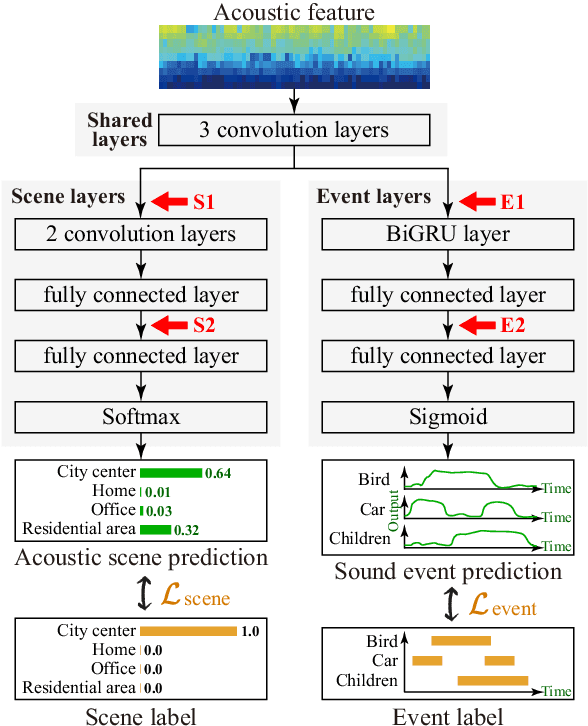

Acoustic scene classification (ASC) and sound event detection (SED) are fundamental tasks in environmental sound analysis, and many methods based on deep learning have been proposed. Considering that information on acoustic scenes and sound events helps SED and ASC mutually, some researchers have proposed a joint analysis of acoustic scenes and sound events by multitask learning (MTL). However, conventional works have not investigated in detail how acoustic scenes and sound events mutually benefit SED and ASC. We, therefore, investigate the impact of information on acoustic scenes and sound events on the performance of SED and ASC by using domain adversarial training based on a gradient reversal layer (GRL) or model training with fake labels. Experimental results obtained using the TUT Acoustic Scenes 2016/2017 and TUT Sound Events 2016/2017 show that pieces of information on acoustic scenes and sound events are effectively used to detect sound events and classify acoustic scenes, respectively. Moreover, upon comparing GRL- and fake-label-based methods with single-task-based ASC and SED methods, single-task-based methods are found to achieve better performance. This result implies that even when using single-task-based ASC and SED methods, information on acoustic scenes may be implicitly utilized for SED and vice versa.