 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Information on Acoustic Scenes and Sound Events Mutually Benefits Event Detection and Scene Classification Tasks
Paper and Code
Apr 05, 2022

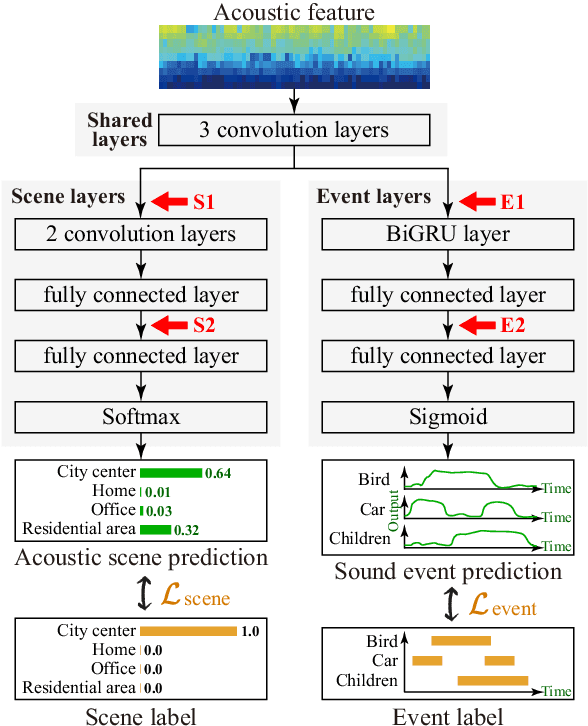

Acoustic scene classification (ASC) and sound event detection (SED) are fundamental tasks in environmental sound analysis, and many methods based on deep learning have been proposed. Considering that information on acoustic scenes and sound events helps SED and ASC mutually, some researchers have proposed a joint analysis of acoustic scenes and sound events by multitask learning (MTL). However, conventional works have not investigated in detail how acoustic scenes and sound events mutually benefit SED and ASC. We, therefore, investigate the impact of information on acoustic scenes and sound events on the performance of SED and ASC by using domain adversarial training based on a gradient reversal layer (GRL) or model training with fake labels. Experimental results obtained using the TUT Acoustic Scenes 2016/2017 and TUT Sound Events 2016/2017 show that pieces of information on acoustic scenes and sound events are effectively used to detect sound events and classify acoustic scenes, respectively. Moreover, upon comparing GRL- and fake-label-based methods with single-task-based ASC and SED methods, single-task-based methods are found to achieve better performance. This result implies that even when using single-task-based ASC and SED methods, information on acoustic scenes may be implicitly utilized for SED and vice versa.