 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Masked Self-Distillation Modeling for Distributed Multimedia Sensor Event Analysis
Apr 12, 2024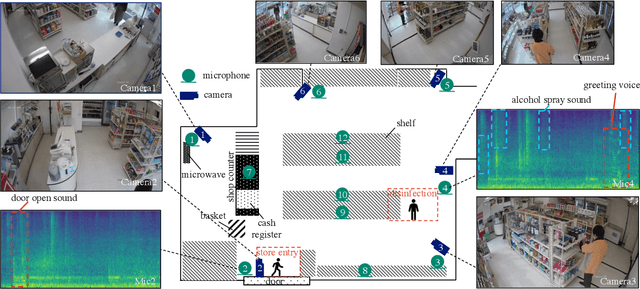

Observations with distributed sensors are essential in analyzing a series of human and machine activities (referred to as 'events' in this paper) in complex and extensive real-world environments. This is because the information obtained from a single sensor is often missing or fragmented in such an environment; observations from multiple locations and modalities should be integrated to analyze events comprehensively. However, a learning method has yet to be established to extract joint representations that effectively combine such distributed observations. Therefore, we propose Guided Masked sELf-Distillation modeling (Guided-MELD) for inter-sensor relationship modeling. The basic idea of Guided-MELD is to learn to supplement the information from the masked sensor with information from other sensors needed to detect the event. Guided-MELD is expected to enable the system to effectively distill the fragmented or redundant target event information obtained by the sensors without being overly dependent on any specific sensors. To validate the effectiveness of the proposed method in novel tasks of distributed multimedia sensor event analysis, we recorded two new datasets that fit the problem setting: MM-Store and MM-Office. These datasets consist of human activities in a convenience store and an office, recorded using distributed cameras and microphones. Experimental results on these datasets show that the proposed Guided-MELD improves event tagging and detection performance and outperforms conventional inter-sensor relationship modeling methods. Furthermore, the proposed method performed robustly even when sensors were reduced.
6DoF SELD: Sound Event Localization and Detection Using Microphones and Motion Tracking Sensors on self-motioning human
Mar 04, 2024We aim to perform sound event localization and detection (SELD) using wearable equipment for a moving human, such as a pedestrian. Conventional SELD tasks have dealt only with microphone arrays located in static positions. However, self-motion with three rotational and three translational degrees of freedom (6DoF) shall be considered for wearable microphone arrays. A system trained only with a dataset using microphone arrays in a fixed position would be unable to adapt to the fast relative motion of sound events associated with self-motion, resulting in the degradation of SELD performance. To address this, we designed 6DoF SELD Dataset for wearable systems, the first SELD dataset considering the self-motion of microphones. Furthermore, we proposed a multi-modal SELD system that jointly utilizes audio and motion tracking sensor signals. These sensor signals are expected to help the system find useful acoustic cues for SELD on the basis of the current self-motion state. Experimental results on our dataset show that the proposed method effectively improves SELD performance with a mechanism to extract acoustic features conditioned by sensor signals.
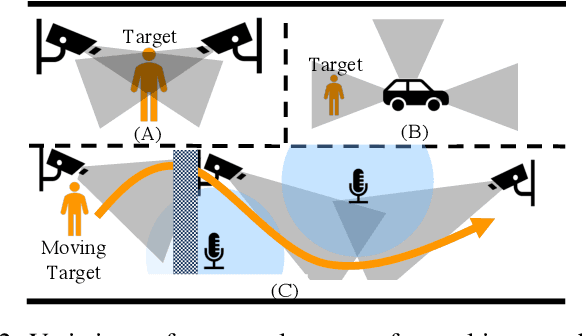
Multi-view and Multi-modal Event Detection Utilizing Transformer-based Multi-sensor fusion
Feb 18, 2022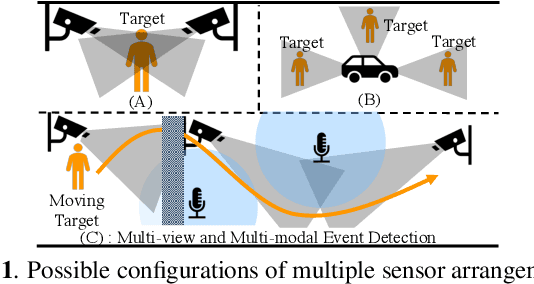
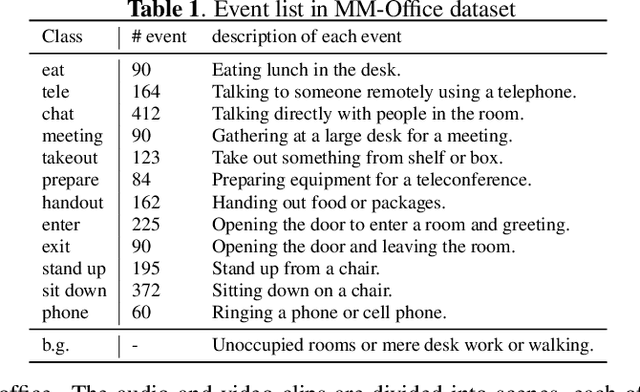
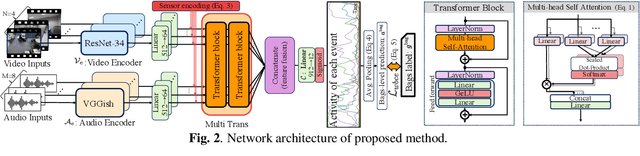
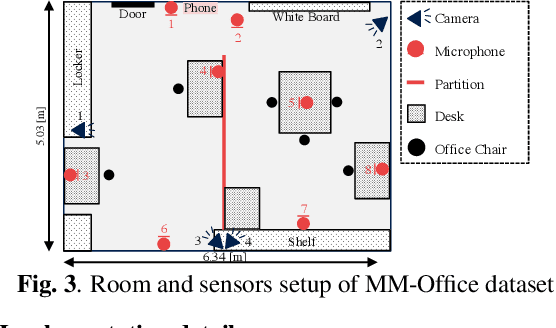
We tackle a challenging task: multi-view and multi-modal event detection that detects events in a wide-range real environment by utilizing data from distributed cameras and microphones and their weak labels. In this task, distributed sensors are utilized complementarily to capture events that are difficult to capture with a single sensor, such as a series of actions of people moving in an intricate room, or communication between people located far apart in a room. For sensors to cooperate effectively in such a situation, the system should be able to exchange information among sensors and combines information that is useful for identifying events in a complementary manner. For such a mechanism, we propose a Transformer-based multi-sensor fusion (MultiTrans) which combines multi-sensor data on the basis of the relationships between features of different viewpoints and modalities. In the experiments using a dataset newly collected for this task, our proposed method using MultiTrans improved the event detection performance and outperformed comparatives.
Echo-aware Adaptation of Sound Event Localization and Detection in Unknown Environments
Feb 18, 2022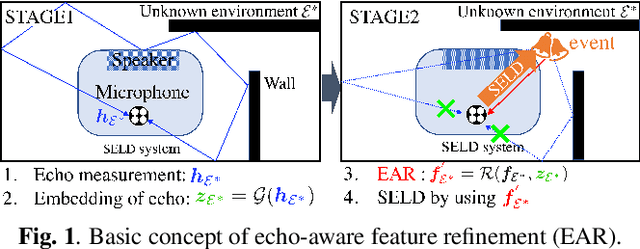
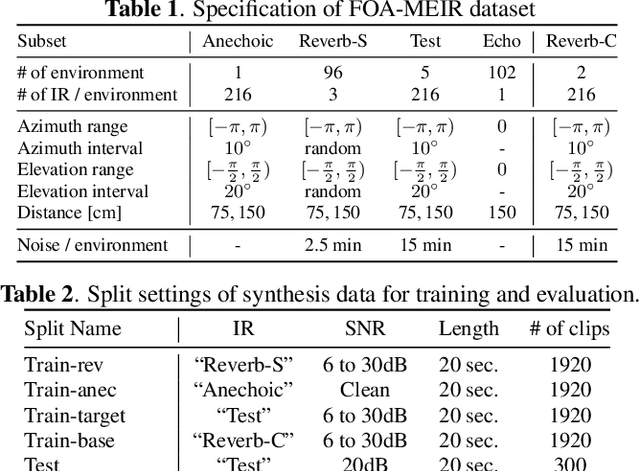
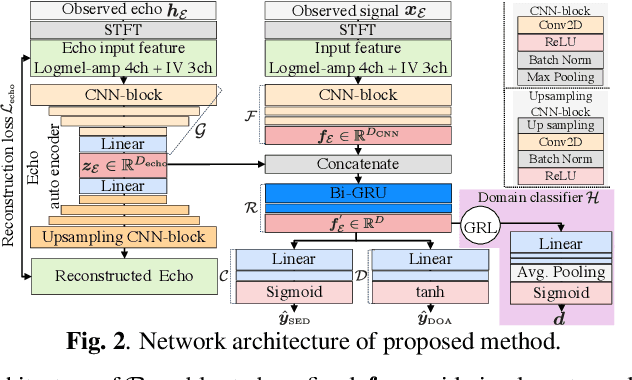

Our goal is to develop a sound event localization and detection (SELD) system that works robustly in unknown environments. A SELD system trained on known environment data is degraded in an unknown environment due to environmental effects such as reverberation and noise not contained in the training data. Previous studies on related tasks have shown that domain adaptation methods are effective when data on the environment in which the system will be used is available even without labels. However adaptation to unknown environments remains a difficult task. In this study, we propose echo-aware feature refinement (EAR) for SELD, which suppresses environmental effects at the feature level by using additional spatial cues of the unknown environment obtained through measuring acoustic echoes. FOA-MEIR, an impulse response dataset containing over 100 environments, was recorded to validate the proposed method. Experiments on FOA-MEIR show that the EAR effectively improves SELD performance in unknown environments.
Wearable SELD dataset: Dataset for sound event localization and detection using wearable devices around head
Feb 17, 2022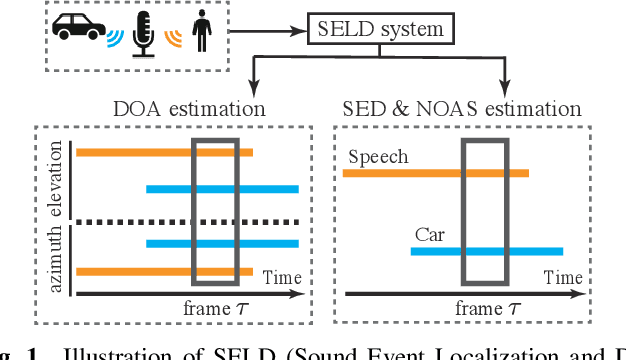
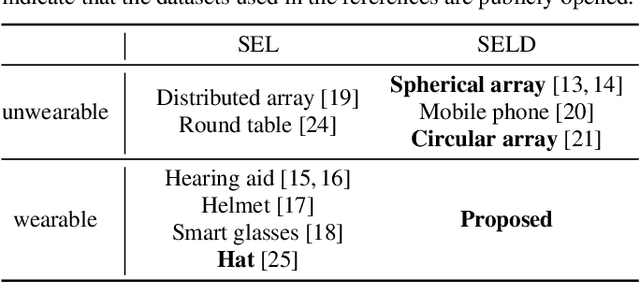
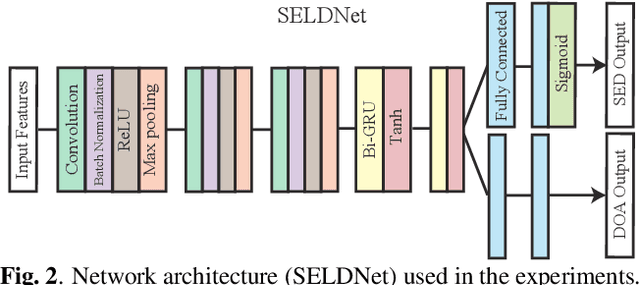
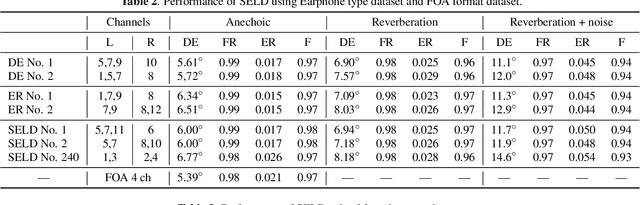
Sound event localization and detection (SELD) is a combined task of identifying the sound event and its direction. Deep neural networks (DNNs) are utilized to associate them with the sound signals observed by a microphone array. Although ambisonic microphones are popular in the literature of SELD, they might limit the range of applications due to their predetermined geometry. Some applications (including those for pedestrians that perform SELD while walking) require a wearable microphone array whose geometry can be designed to suit the task. In this paper, for the development of such a wearable SELD, we propose a dataset named Wearable SELD dataset. It consists of data recorded by 24 microphones placed on a head and torso simulators (HATS) with some accessories mimicking wearable devices (glasses, earphones, and headphones). We also provide experimental results of SELD using the proposed dataset and SELDNet to investigate the effect of microphone configuration.
ToyADMOS2: Another dataset of miniature-machine operating sounds for anomalous sound detection under domain shift conditions
Jun 04, 2021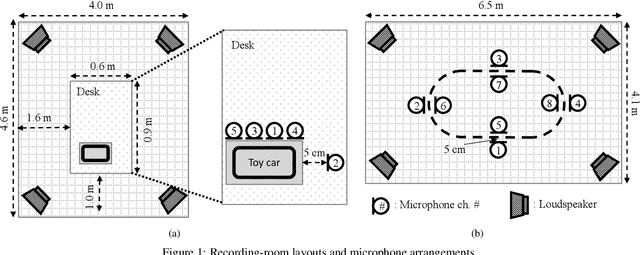

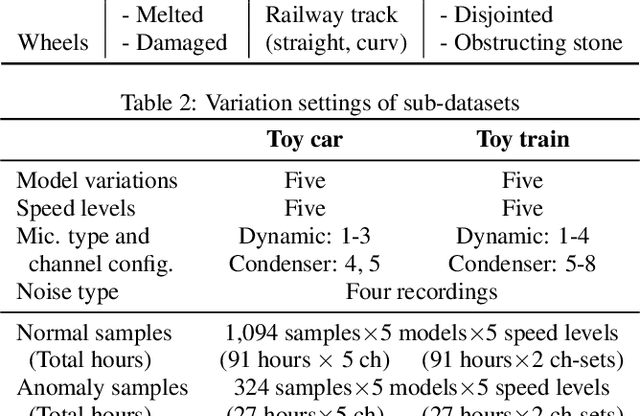
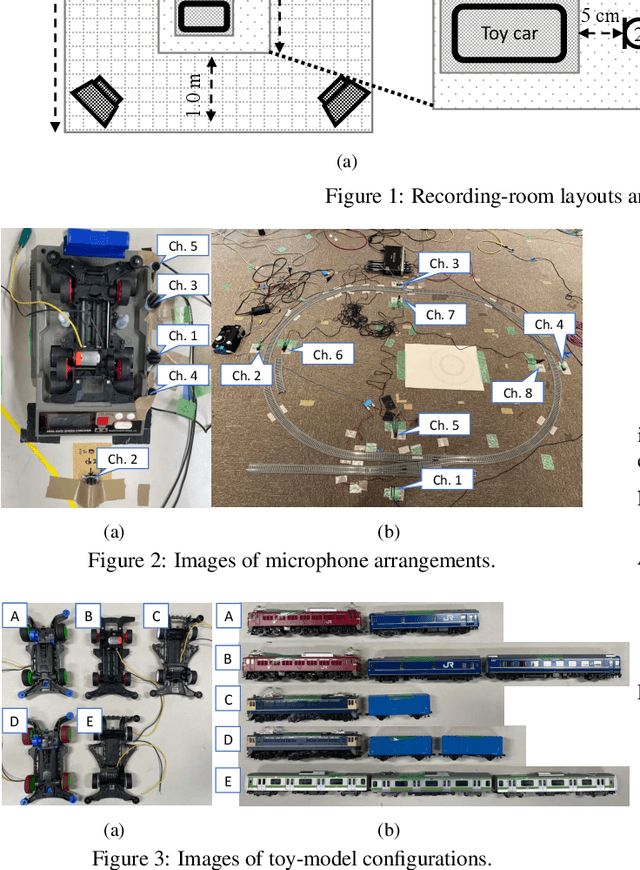
This paper proposes a new large-scale dataset called "ToyADMOS2" for anomaly detection in machine operating sounds (ADMOS). As did for our previous ToyADMOS dataset, we collected a large number of operating sounds of miniature machines (toys) under normal and anomaly conditions by deliberately damaging them but extended with providing controlled depth of damages in anomaly samples. Since typical application scenarios of ADMOS often require robust performance under domain-shift conditions, the ToyADMOS2 dataset is designed for evaluating systems under such conditions. The released dataset consists of two sub-datasets for machine-condition inspection: fault diagnosis of machines with geometrically fixed tasks and fault diagnosis of machines with moving tasks. Domain shifts are represented by introducing several differences in operating conditions, such as the use of the same machine type but with different machine models and parts configurations, different operating speeds, microphone arrangements, etc. Each sub-dataset contains over 27 k samples of normal machine-operating sounds and over 8 k samples of anomalous sounds recorded with five to eight microphones. The dataset is freely available for download at https://github.com/nttcslab/ToyADMOS2-dataset and https://doi.org/10.5281/zenodo.4580270.
A Transformer-based Audio Captioning Model with Keyword Estimation
Jul 01, 2020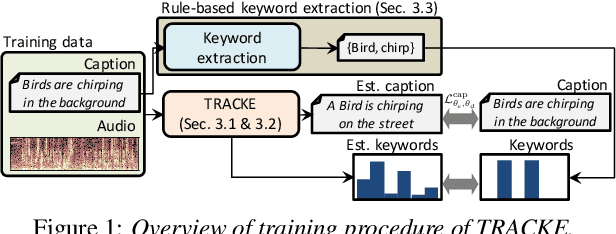
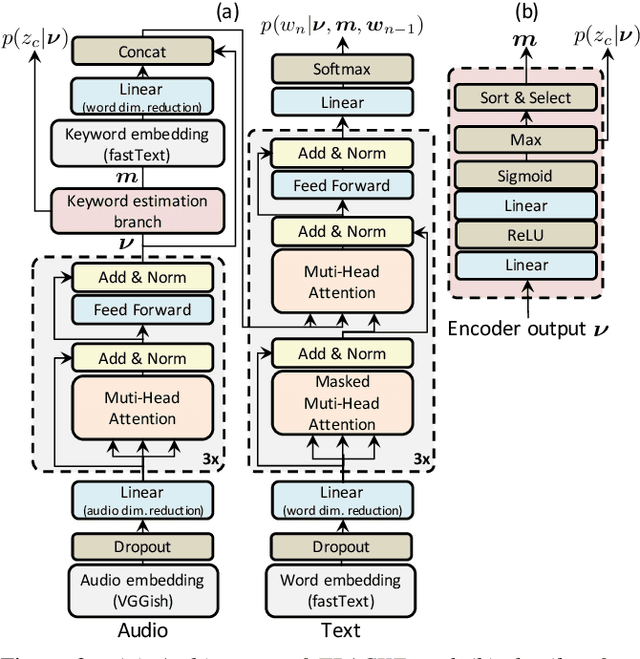
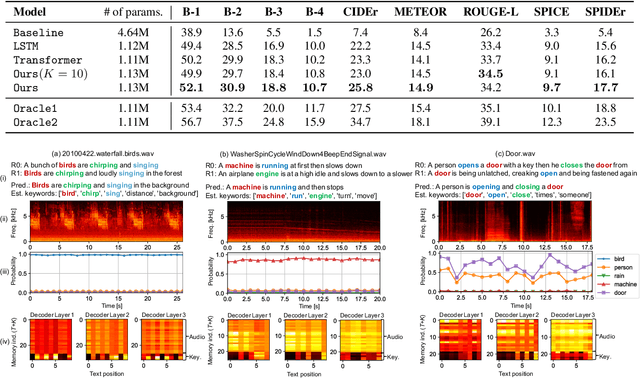
One of the problems with automated audio captioning (AAC) is the indeterminacy in word selection corresponding to the audio event/scene. Since one acoustic event/scene can be described with several words, it results in a combinatorial explosion of possible captions and difficulty in training. To solve this problem, we propose a Transformer-based audio-captioning model with keyword estimation called TRACKE. It simultaneously solves the word-selection indeterminacy problem with the main task of AAC while executing the sub-task of acoustic event detection/acoustic scene classification (i.e., keyword estimation). TRACKE estimates keywords, which comprise a word set corresponding to audio events/scenes in the input audio, and generates the caption while referring to the estimated keywords to reduce word-selection indeterminacy. Experimental results on a public AAC dataset indicate that TRACKE achieved state-of-the-art performance and successfully estimated both the caption and its keywords.
DOA Estimation by DNN-based Denoising and Dereverberation from Sound Intensity Vector
Oct 10, 2019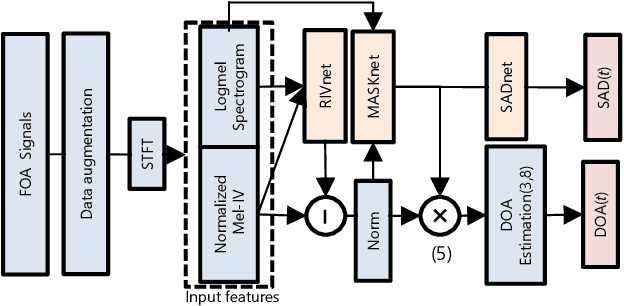

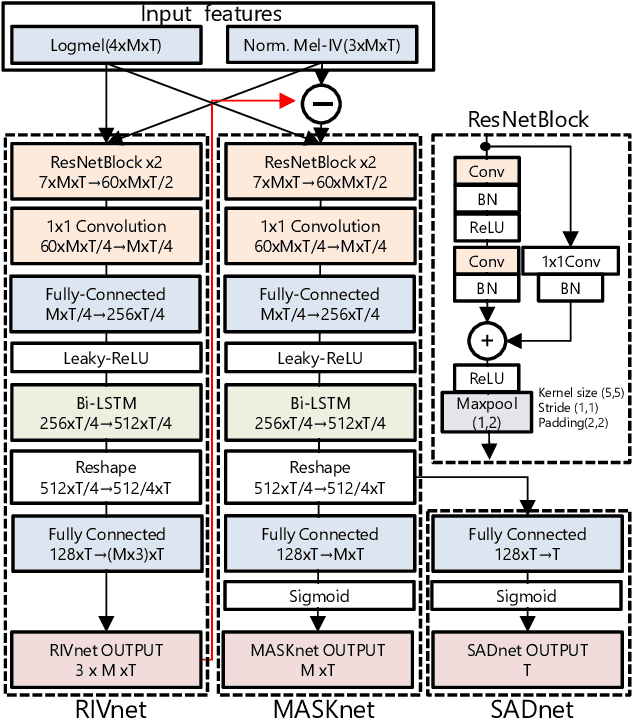
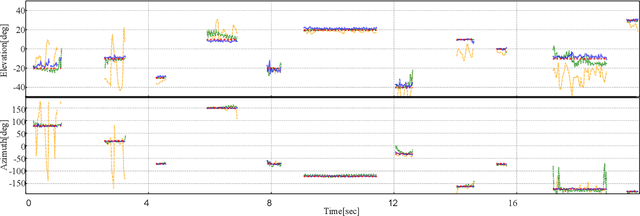
We propose a direction of arrival (DOA) estimation method that combines sound-intensity vector (IV)-based DOA estimation and DNN-based denoising and dereverberation. Since the accuracy of IV-based DOA estimation degrades due to environmental noise and reverberation, two DNNs are used to remove such effects from the observed IVs. DOA is then estimated from the refined IVs based on the physics of wave propagation. Experiments on an open dataset showed that the average DOA error of the proposed method was 0.528 degrees, and it outperformed a conventional IV-based and DNN-based DOA estimation method.
ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection
Aug 09, 2019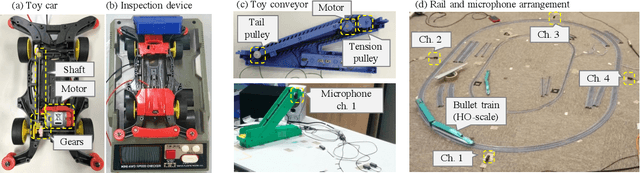
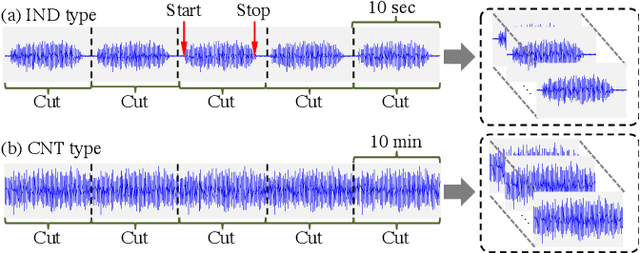
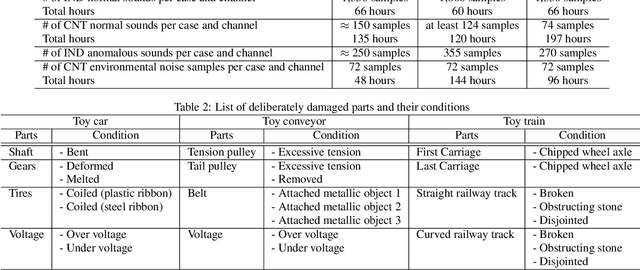
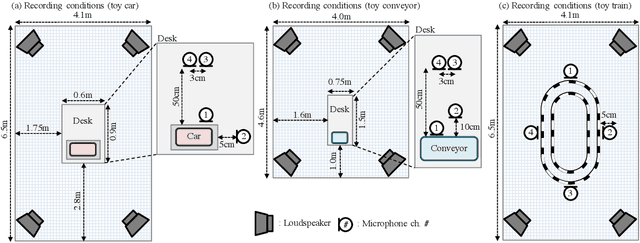
This paper introduces a new dataset called "ToyADMOS" designed for anomaly detection in machine operating sounds (ADMOS). To the best our knowledge, no large-scale datasets are available for ADMOS, although large-scale datasets have contributed to recent advancements in acoustic signal processing. This is because anomalous sound data are difficult to collect. To build a large-scale dataset for ADMOS, we collected anomalous operating sounds of miniature machines (toys) by deliberately damaging them. The released dataset consists of three sub-datasets for machine-condition inspection, fault diagnosis of machines with geometrically fixed tasks, and fault diagnosis of machines with moving tasks. Each sub-dataset includes over 180 hours of normal machine-operating sounds and over 4,000 samples of anomalous sounds collected with four microphones at a 48-kHz sampling rate. The dataset is freely available for download at https://github.com/YumaKoizumi/ToyADMOS-dataset
Batch Uniformization for Minimizing Maximum Anomaly Score of DNN-based Anomaly Detection in Sounds
Jul 19, 2019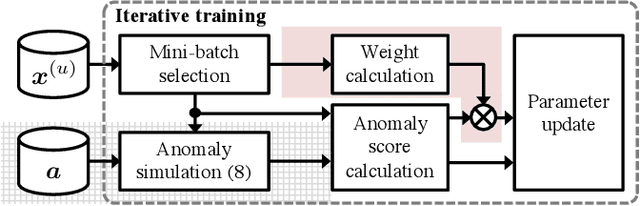

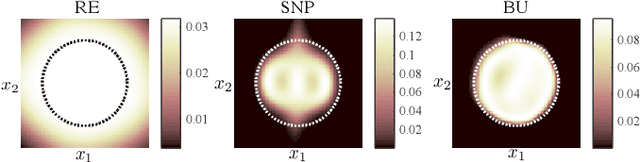
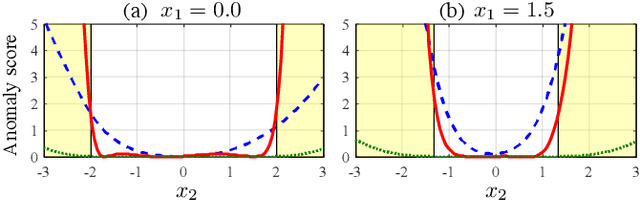
Use of an autoencoder (AE) as a normal model is a state-of-the-art technique for unsupervised-anomaly detection in sounds (ADS). The AE is trained to minimize the sample mean of the anomaly score of normal sounds in a mini-batch. One problem with this approach is that the anomaly score of rare-normal sounds becomes higher than that of frequent-normal sounds, because the sample mean is strongly affected by frequent-normal samples, resulting in preferentially decreasing the anomaly score of frequent-normal samples. To decrease anomaly scores for both frequent- and rare-normal sounds, we propose batch uniformization, a training method for unsupervised-ADS for minimizing a weighted average of the anomaly score on each sample in a mini-batch. We used the reciprocal of the probabilistic density of each sample as the weight, more intuitively, a large weight is given for rare-normal sounds. Such a weight works to give a constant anomaly score for both frequent- and rare-normal sounds. Since the probabilistic density is unknown, we estimate it by using the kernel density estimation on each training mini-batch. Verification- and objective-experiments show that the proposed batch uniformization improves the performance of unsupervised-ADS.