 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Universal Interatomic Potentials on Zeolite Structures
Sep 09, 2025Interatomic potentials (IPs) with wide elemental coverage and high accuracy are powerful tools for high-throughput materials discovery. While the past few years witnessed the development of multiple new universal IPs that cover wide ranges of the periodic table, their applicability to target chemical systems should be carefully investigated. We benchmark several universal IPs using equilibrium zeolite structures as testbeds. We select a diverse set of universal IPs encompassing two major categories: (i) universal analytic IPs, including GFN-FF, UFF, and Dreiding; (ii) pretrained universal machine learning IPs (MLIPs), comprising CHGNet, ORB-v3, MatterSim, eSEN-30M-OAM, PFP-v7, and EquiformerV2-lE4-lF100-S2EFS-OC22. We compare them with established tailor-made IPs, SLC, ClayFF, and BSFF using experimental data and density functional theory (DFT) calculations with dispersion correction as the reference. The tested zeolite structures comprise pure silica frameworks and aluminosilicates containing copper species, potassium, and organic cations. We found that GFN-FF is the best among the tested universal analytic IPs, but it does not achieve satisfactory accuracy for highly strained silica rings and aluminosilicate systems. All MLIPs can well reproduce experimental or DFT-level geometries and energetics. Among the universal MLIPs, the eSEN-30M-OAM model shows the most consistent performance across all zeolite structures studied. These findings show that the modern pretrained universal MLIPs are practical tools in zeolite screening workflows involving various compositions.
Guided Masked Self-Distillation Modeling for Distributed Multimedia Sensor Event Analysis
Apr 12, 2024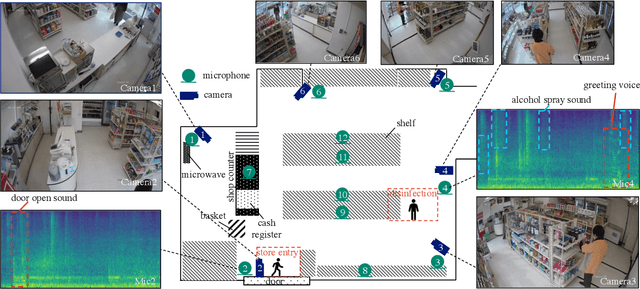
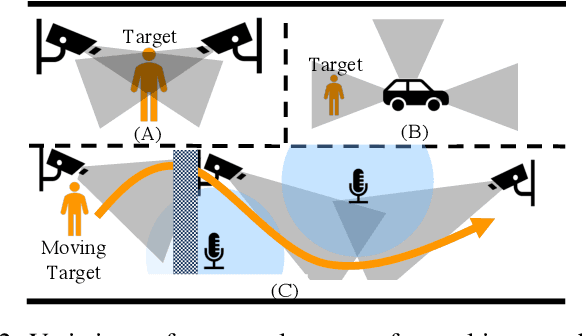

Observations with distributed sensors are essential in analyzing a series of human and machine activities (referred to as 'events' in this paper) in complex and extensive real-world environments. This is because the information obtained from a single sensor is often missing or fragmented in such an environment; observations from multiple locations and modalities should be integrated to analyze events comprehensively. However, a learning method has yet to be established to extract joint representations that effectively combine such distributed observations. Therefore, we propose Guided Masked sELf-Distillation modeling (Guided-MELD) for inter-sensor relationship modeling. The basic idea of Guided-MELD is to learn to supplement the information from the masked sensor with information from other sensors needed to detect the event. Guided-MELD is expected to enable the system to effectively distill the fragmented or redundant target event information obtained by the sensors without being overly dependent on any specific sensors. To validate the effectiveness of the proposed method in novel tasks of distributed multimedia sensor event analysis, we recorded two new datasets that fit the problem setting: MM-Store and MM-Office. These datasets consist of human activities in a convenience store and an office, recorded using distributed cameras and microphones. Experimental results on these datasets show that the proposed Guided-MELD improves event tagging and detection performance and outperforms conventional inter-sensor relationship modeling methods. Furthermore, the proposed method performed robustly even when sensors were reduced.
6DoF SELD: Sound Event Localization and Detection Using Microphones and Motion Tracking Sensors on self-motioning human
Mar 04, 2024We aim to perform sound event localization and detection (SELD) using wearable equipment for a moving human, such as a pedestrian. Conventional SELD tasks have dealt only with microphone arrays located in static positions. However, self-motion with three rotational and three translational degrees of freedom (6DoF) shall be considered for wearable microphone arrays. A system trained only with a dataset using microphone arrays in a fixed position would be unable to adapt to the fast relative motion of sound events associated with self-motion, resulting in the degradation of SELD performance. To address this, we designed 6DoF SELD Dataset for wearable systems, the first SELD dataset considering the self-motion of microphones. Furthermore, we proposed a multi-modal SELD system that jointly utilizes audio and motion tracking sensor signals. These sensor signals are expected to help the system find useful acoustic cues for SELD on the basis of the current self-motion state. Experimental results on our dataset show that the proposed method effectively improves SELD performance with a mechanism to extract acoustic features conditioned by sensor signals.