 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Uniformization for Minimizing Maximum Anomaly Score of DNN-based Anomaly Detection in Sounds
Jul 19, 2019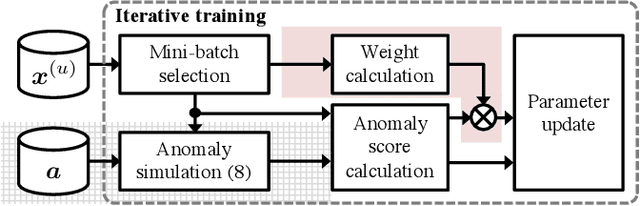

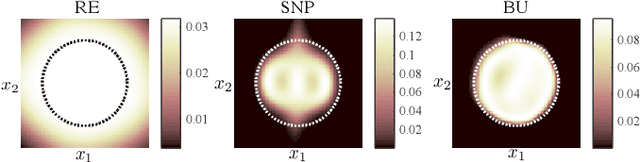
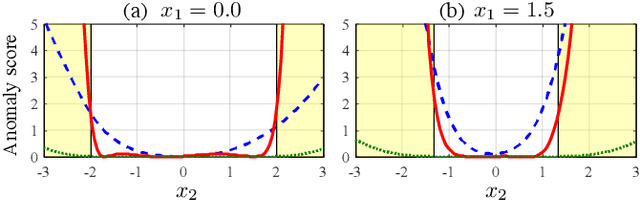
Use of an autoencoder (AE) as a normal model is a state-of-the-art technique for unsupervised-anomaly detection in sounds (ADS). The AE is trained to minimize the sample mean of the anomaly score of normal sounds in a mini-batch. One problem with this approach is that the anomaly score of rare-normal sounds becomes higher than that of frequent-normal sounds, because the sample mean is strongly affected by frequent-normal samples, resulting in preferentially decreasing the anomaly score of frequent-normal samples. To decrease anomaly scores for both frequent- and rare-normal sounds, we propose batch uniformization, a training method for unsupervised-ADS for minimizing a weighted average of the anomaly score on each sample in a mini-batch. We used the reciprocal of the probabilistic density of each sample as the weight, more intuitively, a large weight is given for rare-normal sounds. Such a weight works to give a constant anomaly score for both frequent- and rare-normal sounds. Since the probabilistic density is unknown, we estimate it by using the kernel density estimation on each training mini-batch. Verification- and objective-experiments show that the proposed batch uniformization improves the performance of unsupervised-ADS.
AdaFlow: Domain-Adaptive Density Estimator with Application to Anomaly Detection and Unpaired Cross-Domain Translation
Dec 14, 2018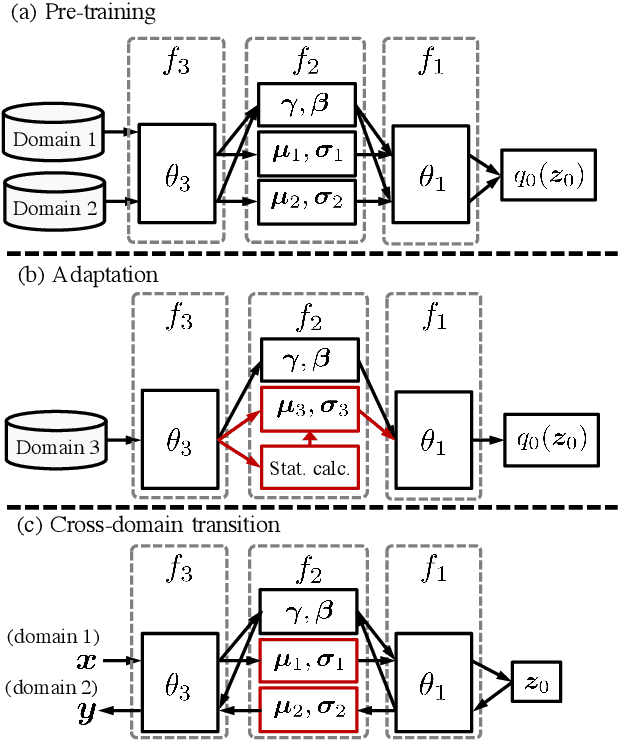
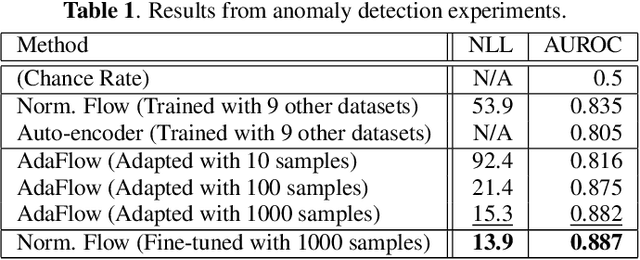

We tackle unsupervised anomaly detection (UAD), a problem of detecting data that significantly differ from normal data. UAD is typically solved by using density estimation. Recently, deep neural network (DNN)-based density estimators, such as Normalizing Flows, have been attracting attention. However, one of their drawbacks is the difficulty in adapting them to the change in the normal data's distribution. To address this difficulty, we propose AdaFlow, a new DNN-based density estimator that can be easily adapted to the change of the distribution. AdaFlow is a unified model of a Normalizing Flow and Adaptive Batch-Normalizations, a module that enables DNNs to adapt to new distributions. AdaFlow can be adapted to a new distribution by just conducting forward propagation once per sample; hence, it can be used on devices that have limited computational resources. We have confirmed the effectiveness of the proposed model through an anomaly detection in a sound task. We also propose a method of applying AdaFlow to the unpaired cross-domain translation problem, in which one has to train a cross-domain translation model with only unpaired samples. We have confirmed that our model can be used for the cross-domain translation problem through experiments on image datasets.
Spatio-temporal Person Retrieval via Natural Language Queries
Aug 22, 2017



In this paper, we address the problem of spatio-temporal person retrieval from multiple videos using a natural language query, in which we output a tube (i.e., a sequence of bounding boxes) which encloses the person described by the query. For this problem, we introduce a novel dataset consisting of videos containing people annotated with bounding boxes for each second and with five natural language descriptions. To retrieve the tube of the person described by a given natural language query, we design a model that combines methods for spatio-temporal human detection and multimodal retrieval. We conduct comprehensive experiments to compare a variety of tube and text representations and multimodal retrieval methods, and present a strong baseline in this task as well as demonstrate the efficacy of our tube representation and multimodal feature embedding technique. Finally, we demonstrate the versatility of our model by applying it to two other important tasks.
Dense Image Representation with Spatial Pyramid VLAD Coding of CNN for Locally Robust Captioning
Mar 30, 2016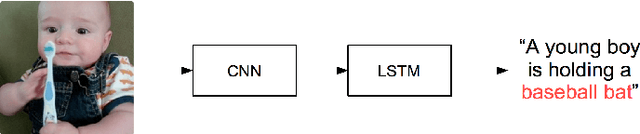



The workflow of extracting features from images using convolutional neural networks (CNN) and generating captions with recurrent neural networks (RNN) has become a de-facto standard for image captioning task. However, since CNN features are originally designed for classification task, it is mostly concerned with the main conspicuous element of the image, and often fails to correctly convey information on local, secondary elements. We propose to incorporate coding with vector of locally aggregated descriptors (VLAD) on spatial pyramid for CNN features of sub-regions in order to generate image representations that better reflect the local information of the images. Our results show that our method of compact VLAD coding can match CNN features with as little as 3% of dimensionality and, when combined with spatial pyramid, it results in image captions that more accurately take local elements into account.