 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Image Representation with Spatial Pyramid VLAD Coding of CNN for Locally Robust Captioning
Paper and Code
Mar 30, 2016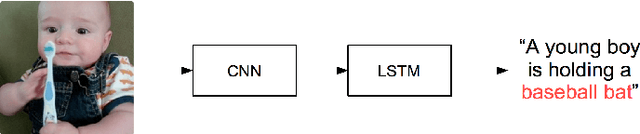



The workflow of extracting features from images using convolutional neural networks (CNN) and generating captions with recurrent neural networks (RNN) has become a de-facto standard for image captioning task. However, since CNN features are originally designed for classification task, it is mostly concerned with the main conspicuous element of the image, and often fails to correctly convey information on local, secondary elements. We propose to incorporate coding with vector of locally aggregated descriptors (VLAD) on spatial pyramid for CNN features of sub-regions in order to generate image representations that better reflect the local information of the images. Our results show that our method of compact VLAD coding can match CNN features with as little as 3% of dimensionality and, when combined with spatial pyramid, it results in image captions that more accurately take local elements into account.