 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
Dec 01, 2017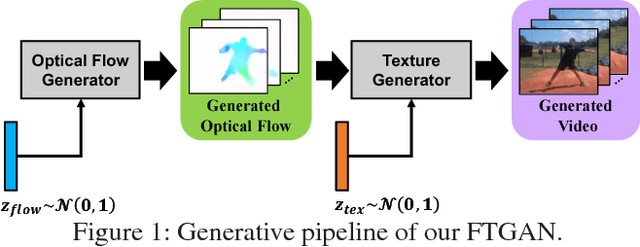
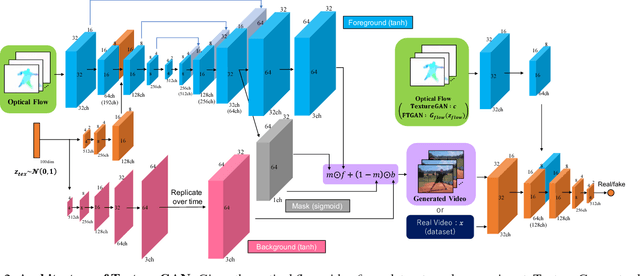


Learning to represent and generate videos from unlabeled data is a very challenging problem. To generate realistic videos, it is important not only to ensure that the appearance of each frame is real, but also to ensure the plausibility of a video motion and consistency of a video appearance in the time direction. The process of video generation should be divided according to these intrinsic difficulties. In this study, we focus on the motion and appearance information as two important orthogonal components of a video, and propose Flow-and-Texture-Generative Adversarial Networks (FTGAN) consisting of FlowGAN and TextureGAN. In order to avoid a huge annotation cost, we have to explore a way to learn from unlabeled data. Thus, we employ optical flow as motion information to generate videos. FlowGAN generates optical flow, which contains only the edge and motion of the videos to be begerated. On the other hand, TextureGAN specializes in giving a texture to optical flow generated by FlowGAN. This hierarchical approach brings more realistic videos with plausible motion and appearance consistency. Our experiments show that our model generates more plausible motion videos and also achieves significantly improved performance for unsupervised action classification in comparison to previous GAN works. In addition, because our model generates videos from two independent information, our model can generate new combinations of motion and attribute that are not seen in training data, such as a video in which a person is doing sit-up in a baseball ground.
Beyond Caption To Narrative: Video Captioning With Multiple Sentences
May 18, 2016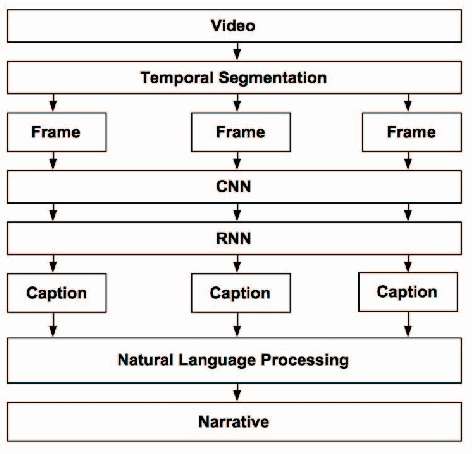



Recent advances in image captioning task have led to increasing interests in video captioning task. However, most works on video captioning are focused on generating single input of aggregated features, which hardly deviates from image captioning process and does not fully take advantage of dynamic contents present in videos. We attempt to generate video captions that convey richer contents by temporally segmenting the video with action localization, generating multiple captions from multiple frames, and connecting them with natural language processing techniques, in order to generate a story-like caption. We show that our proposed method can generate captions that are richer in contents and can compete with state-of-the-art method without explicitly using video-level features as input.
Improved Dense Trajectory with Cross Streams
Apr 29, 2016


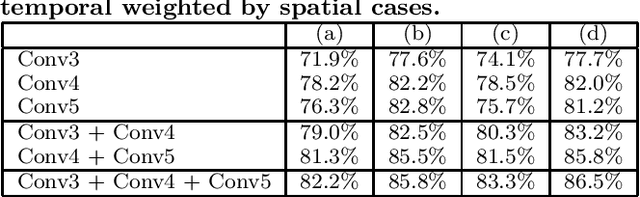
Improved dense trajectories (iDT) have shown great performance in action recognition, and their combination with the two-stream approach has achieved state-of-the-art performance. It is, however, difficult for iDT to completely remove background trajectories from video with camera shaking. Trajectories in less discriminative regions should be given modest weights in order to create more discriminative local descriptors for action recognition. In addition, the two-stream approach, which learns appearance and motion information separately, cannot focus on motion in important regions when extracting features from spatial convolutional layers of the appearance network, and vice versa. In order to address the above mentioned problems, we propose a new local descriptor that pools a new convolutional layer obtained from crossing two networks along iDT. This new descriptor is calculated by applying discriminative weights learned from one network to a convolutional layer of the other network. Our method has achieved state-of-the-art performance on ordinal action recognition datasets, 92.3% on UCF101, and 66.2% on HMDB51.
Recognizing Activities of Daily Living with a Wrist-mounted Camera
Apr 28, 2016



We present a novel dataset and a novel algorithm for recognizing activities of daily living (ADL) from a first-person wearable camera. Handled objects are crucially important for egocentric ADL recognition. For specific examination of objects related to users' actions separately from other objects in an environment, many previous works have addressed the detection of handled objects in images captured from head-mounted and chest-mounted cameras. Nevertheless, detecting handled objects is not always easy because they tend to appear small in images. They can be occluded by a user's body. As described herein, we mount a camera on a user's wrist. A wrist-mounted camera can capture handled objects at a large scale, and thus it enables us to skip object detection process. To compare a wrist-mounted camera and a head-mounted camera, we also develop a novel and publicly available dataset that includes videos and annotations of daily activities captured simultaneously by both cameras. Additionally, we propose a discriminative video representation that retains spatial and temporal information after encoding frame descriptors extracted by Convolutional Neural Networks (CNN).
Dense Image Representation with Spatial Pyramid VLAD Coding of CNN for Locally Robust Captioning
Mar 30, 2016



The workflow of extracting features from images using convolutional neural networks (CNN) and generating captions with recurrent neural networks (RNN) has become a de-facto standard for image captioning task. However, since CNN features are originally designed for classification task, it is mostly concerned with the main conspicuous element of the image, and often fails to correctly convey information on local, secondary elements. We propose to incorporate coding with vector of locally aggregated descriptors (VLAD) on spatial pyramid for CNN features of sub-regions in order to generate image representations that better reflect the local information of the images. Our results show that our method of compact VLAD coding can match CNN features with as little as 3% of dimensionality and, when combined with spatial pyramid, it results in image captions that more accurately take local elements into account.