 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Caption To Narrative: Video Captioning With Multiple Sentences
Paper and Code
May 18, 2016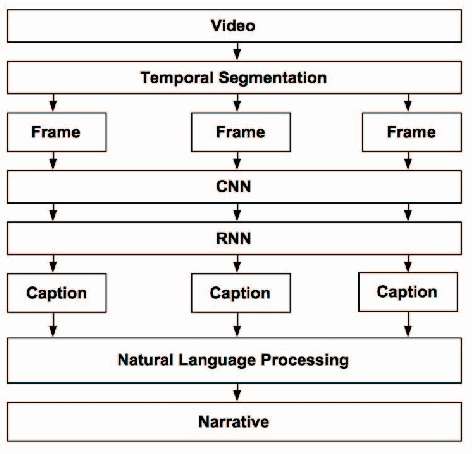



Recent advances in image captioning task have led to increasing interests in video captioning task. However, most works on video captioning are focused on generating single input of aggregated features, which hardly deviates from image captioning process and does not fully take advantage of dynamic contents present in videos. We attempt to generate video captions that convey richer contents by temporally segmenting the video with action localization, generating multiple captions from multiple frames, and connecting them with natural language processing techniques, in order to generate a story-like caption. We show that our proposed method can generate captions that are richer in contents and can compete with state-of-the-art method without explicitly using video-level features as input.