 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
Paper and Code
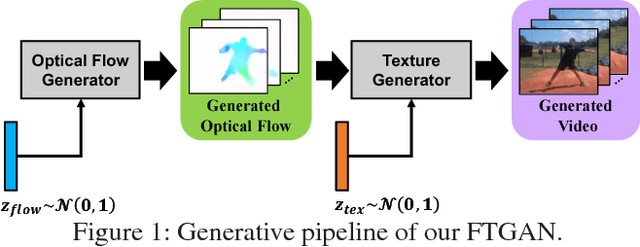
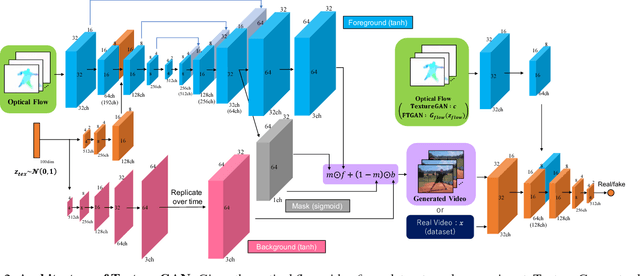


Learning to represent and generate videos from unlabeled data is a very challenging problem. To generate realistic videos, it is important not only to ensure that the appearance of each frame is real, but also to ensure the plausibility of a video motion and consistency of a video appearance in the time direction. The process of video generation should be divided according to these intrinsic difficulties. In this study, we focus on the motion and appearance information as two important orthogonal components of a video, and propose Flow-and-Texture-Generative Adversarial Networks (FTGAN) consisting of FlowGAN and TextureGAN. In order to avoid a huge annotation cost, we have to explore a way to learn from unlabeled data. Thus, we employ optical flow as motion information to generate videos. FlowGAN generates optical flow, which contains only the edge and motion of the videos to be begerated. On the other hand, TextureGAN specializes in giving a texture to optical flow generated by FlowGAN. This hierarchical approach brings more realistic videos with plausible motion and appearance consistency. Our experiments show that our model generates more plausible motion videos and also achieves significantly improved performance for unsupervised action classification in comparison to previous GAN works. In addition, because our model generates videos from two independent information, our model can generate new combinations of motion and attribute that are not seen in training data, such as a video in which a person is doing sit-up in a baseball ground.