 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiability and Estimation for Unlabeled Finite Mixtures under Marginal Independence
Jun 06, 2026We study component recovery and mixing-matrix estimation from unlabeled finite mixtures whose observable distributions share the same latent components but have unknown mixing weights. The main identifying signal is marginal independence: each component is assumed to be independent on at least one coordinate pair, but no labels, clean component samples, or mixing weights are observed. We first prove a structural result for product components: under linear independence of the univariate marginals, any independent affine combination of the components must coincide with a single component. We then extend this principle to observable mixtures and show that, under full-rank and no-cancellation conditions, marginally independent affine combinations recover the corresponding latent components. When every component is independent on some coordinate pair, all components are identifiable, and the mixing matrix is recoverable under the stated completion conditions. Finally, we propose a Product-Marginal Maximum Mean Discrepancy (PM-MMD) estimator over affine combinations of the observable mixtures and prove uniform convergence and stability under approximate marginal independence. This framework also separates the empirical roles of the assumptions: irreducibility is, in general, not directly testable from the unlabeled mixtures alone, whereas marginal independence yields a candidate-level diagnostic through held-out PM-MMD. Controlled and flow-cytometry experiments show when marginal independence provides a useful recovery signal. In the reported multi-component comparisons, condition-aware representative selection stabilizes PM-MMD and improves recovery relative to clustering, factorization, and pairwise mixture-proportion baselines using the same unlabeled mixtures.
Conditional Video Generation Using Action-Appearance Captions
Dec 05, 2018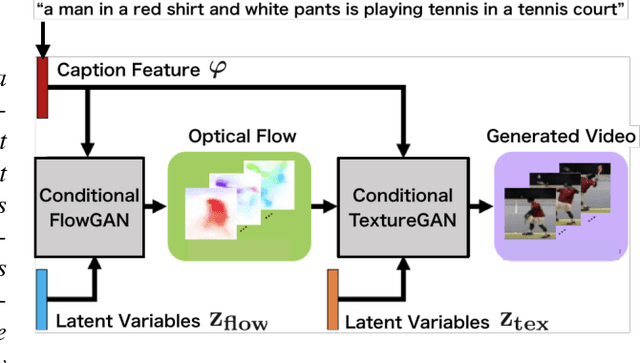


The field of automatic video generation has received a boost thanks to the recent Generative Adversarial Networks (GANs). However, most existing methods cannot control the contents of the generated video using a text caption, losing their usefulness to a large extent. This particularly affects human videos due to their great variety of actions and appearances. This paper presents Conditional Flow and Texture GAN (CFT-GAN), a GAN-based video generation method from action-appearance captions. We propose a novel way of generating video by encoding a caption (e.g., "a man in blue jeans is playing golf") in a two-stage generation pipeline. Our CFT-GAN uses such caption to generate an optical flow (action) and a texture (appearance) for each frame. As a result, the output video reflects the content specified in the caption in a plausible way. Moreover, to train our method, we constructed a new dataset for human video generation with captions. We evaluated the proposed method qualitatively and quantitatively via an ablation study and a user study. The results demonstrate that CFT-GAN is able to successfully generate videos containing the action and appearances indicated in the captions.
Open Set Domain Adaptation by Backpropagation
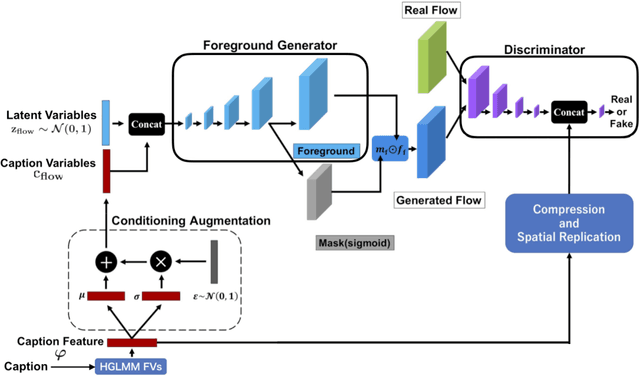
Jul 06, 2018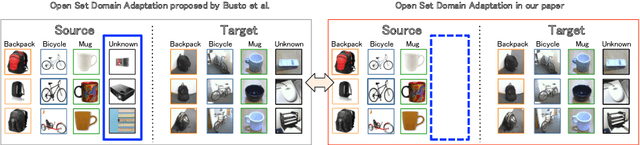
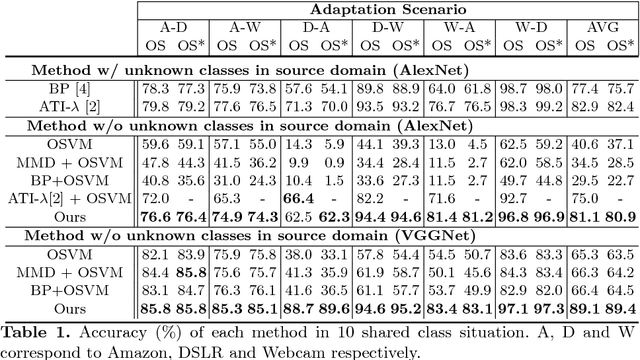
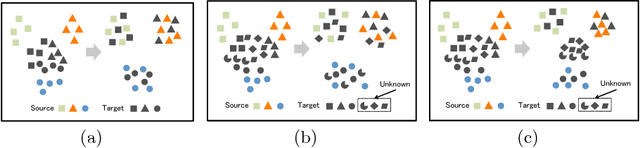
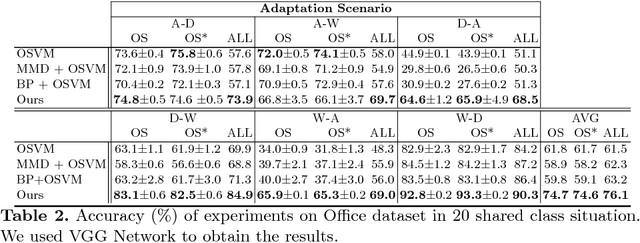
Numerous algorithms have been proposed for transferring knowledge from a label-rich domain (source) to a label-scarce domain (target). Almost all of them are proposed for a closed-set scenario, where the source and the target domain completely share the class of their samples. We call the shared class the \doublequote{known class.} However, in practice, when samples in target domain are not labeled, we cannot know whether the domains share the class. A target domain can contain samples of classes that are not shared by the source domain. We call such classes the \doublequote{unknown class} and algorithms that work well in the open set situation are very practical. However, most existing distribution matching methods for domain adaptation do not work well in this setting because unknown target samples should not be aligned with the source. In this paper, we propose a method for an open set domain adaptation scenario which utilizes adversarial training. A classifier is trained to make a boundary between the source and the target samples whereas a generator is trained to make target samples far from the boundary. Thus, we assign two options to the feature generator: aligning them with source known samples or rejecting them as unknown target samples. This approach allows extracting features that separate unknown target samples from known target samples. Our method was extensively evaluated in domain adaptation setting and outperformed other methods with a large margin in most settings.
Hierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
Dec 01, 2017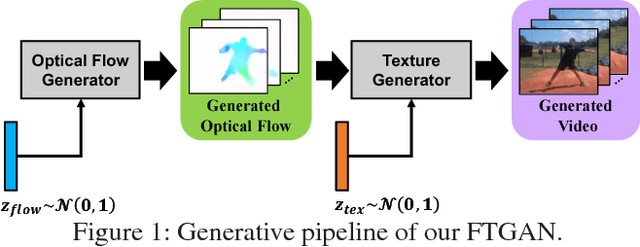
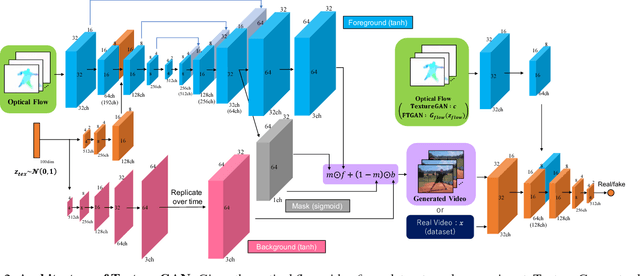


Learning to represent and generate videos from unlabeled data is a very challenging problem. To generate realistic videos, it is important not only to ensure that the appearance of each frame is real, but also to ensure the plausibility of a video motion and consistency of a video appearance in the time direction. The process of video generation should be divided according to these intrinsic difficulties. In this study, we focus on the motion and appearance information as two important orthogonal components of a video, and propose Flow-and-Texture-Generative Adversarial Networks (FTGAN) consisting of FlowGAN and TextureGAN. In order to avoid a huge annotation cost, we have to explore a way to learn from unlabeled data. Thus, we employ optical flow as motion information to generate videos. FlowGAN generates optical flow, which contains only the edge and motion of the videos to be begerated. On the other hand, TextureGAN specializes in giving a texture to optical flow generated by FlowGAN. This hierarchical approach brings more realistic videos with plausible motion and appearance consistency. Our experiments show that our model generates more plausible motion videos and also achieves significantly improved performance for unsupervised action classification in comparison to previous GAN works. In addition, because our model generates videos from two independent information, our model can generate new combinations of motion and attribute that are not seen in training data, such as a video in which a person is doing sit-up in a baseball ground.