 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Dense Trajectory with Cross Streams
Paper and Code
Apr 29, 2016


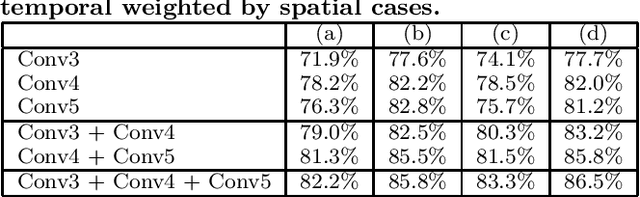
Improved dense trajectories (iDT) have shown great performance in action recognition, and their combination with the two-stream approach has achieved state-of-the-art performance. It is, however, difficult for iDT to completely remove background trajectories from video with camera shaking. Trajectories in less discriminative regions should be given modest weights in order to create more discriminative local descriptors for action recognition. In addition, the two-stream approach, which learns appearance and motion information separately, cannot focus on motion in important regions when extracting features from spatial convolutional layers of the appearance network, and vice versa. In order to address the above mentioned problems, we propose a new local descriptor that pools a new convolutional layer obtained from crossing two networks along iDT. This new descriptor is calculated by applying discriminative weights learned from one network to a convolutional layer of the other network. Our method has achieved state-of-the-art performance on ordinal action recognition datasets, 92.3% on UCF101, and 66.2% on HMDB51.