 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Integration of Speech Recognition, Dereverberation, Beamforming, and Self-Supervised Learning Representation
Paper and Code
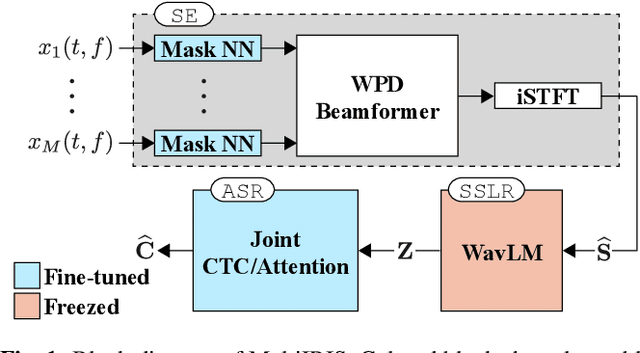
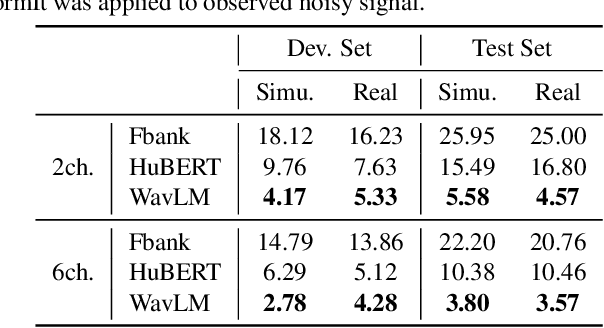
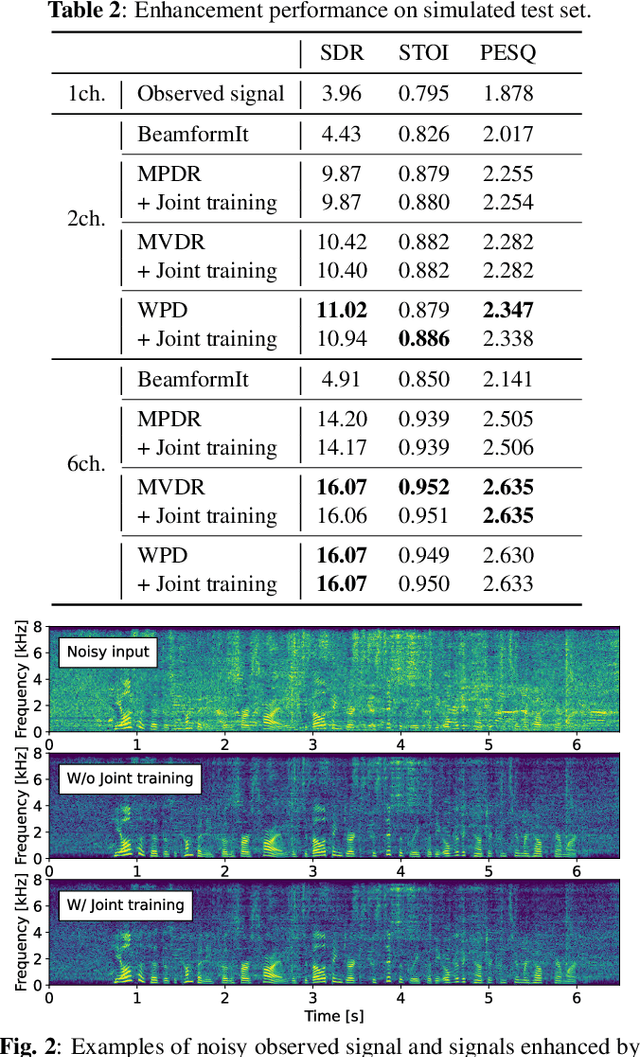
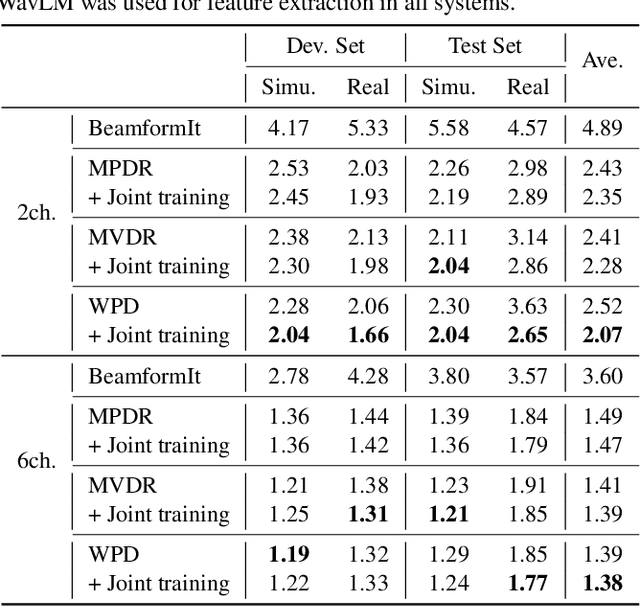
Self-supervised learning representation (SSLR) has demonstrated its significant effectiveness in automatic speech recognition (ASR), mainly with clean speech. Recent work pointed out the strength of integrating SSLR with single-channel speech enhancement for ASR in noisy environments. This paper further advances this integration by dealing with multi-channel input. We propose a novel end-to-end architecture by integrating dereverberation, beamforming, SSLR, and ASR within a single neural network. Our system achieves the best performance reported in the literature on the CHiME-4 6-channel track with a word error rate (WER) of 1.77%. While the WavLM-based strong SSLR demonstrates promising results by itself, the end-to-end integration with the weighted power minimization distortionless response beamformer, which simultaneously performs dereverberation and denoising, improves WER significantly. Its effectiveness is also validated on the REVERB dataset.