 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCA23K: An audio dataset for investigating open-set label noise
Sep 19, 2021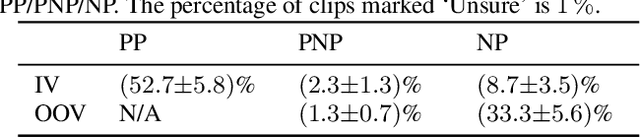
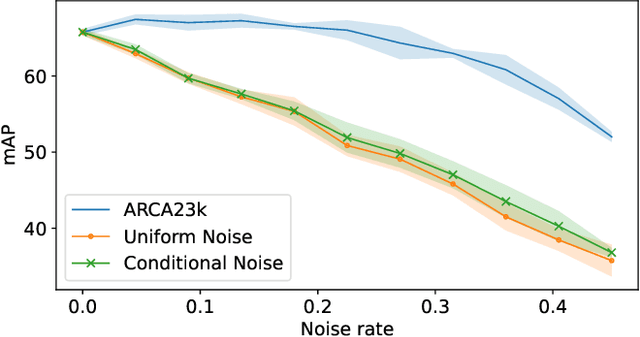

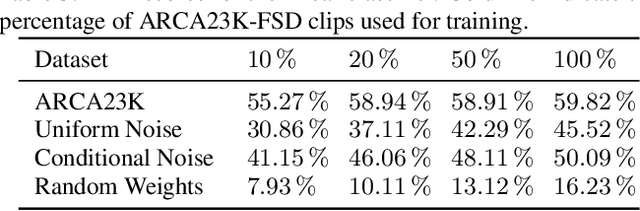
The availability of audio data on sound sharing platforms such as Freesound gives users access to large amounts of annotated audio. Utilising such data for training is becoming increasingly popular, but the problem of label noise that is often prevalent in such datasets requires further investigation. This paper introduces ARCA23K, an Automatically Retrieved and Curated Audio dataset comprised of over 23000 labelled Freesound clips. Unlike past datasets such as FSDKaggle2018 and FSDnoisy18K, ARCA23K facilitates the study of label noise in a more controlled manner. We describe the entire process of creating the dataset such that it is fully reproducible, meaning researchers can extend our work with little effort. We show that the majority of labelling errors in ARCA23K are due to out-of-vocabulary audio clips, and we refer to this type of label noise as open-set label noise. Experiments are carried out in which we study the impact of label noise in terms of classification performance and representation learning.
Conditional Sound Generation Using Neural Discrete Time-Frequency Representation Learning
Jul 25, 2021



Deep generative models have recently achieved impressive performance in speech and music synthesis. However, compared to the generation of those domain-specific sounds, generating general sounds (such as siren, gunshots) has received less attention, despite their wide applications. In previous work, the SampleRNN method was considered for sound generation in the time domain. However, SampleRNN is potentially limited in capturing long-range dependencies within sounds as it only back-propagates through a limited number of samples. In this work, we propose a method for generating sounds via neural discrete time-frequency representation learning, conditioned on sound classes. This offers an advantage in efficiently modelling long-range dependencies and retaining local fine-grained structures within sound clips. We evaluate our approach on the UrbanSound8K dataset, compared to SampleRNN, with the performance metrics measuring the quality and diversity of generated sounds. Experimental results show that our method offers comparable performance in quality and significantly better performance in diversity.
Enhancing Audio Augmentation Methods with Consistency Learning
Feb 09, 2021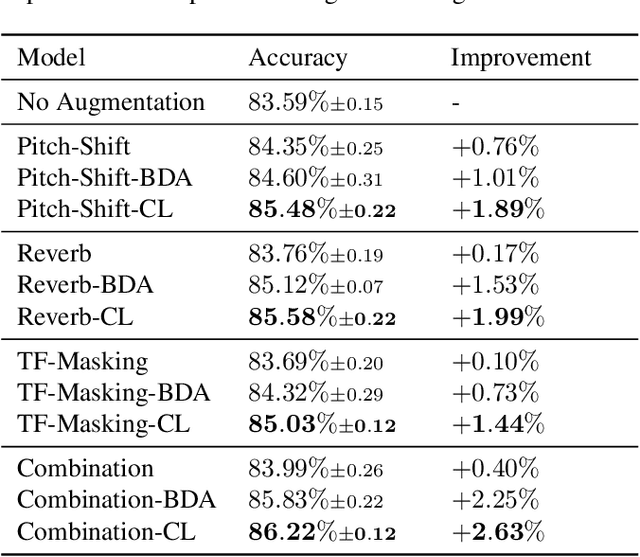

Data augmentation is an inexpensive way to increase training data diversity, and is commonly achieved via transformations of existing data. For tasks such as classification, there is a good case for learning representations of the data that are invariant to such transformations, yet this is not explicitly enforced by classification losses such as the cross-entropy loss. This paper investigates the use of training objectives that explicitly impose this consistency constraint, and how it can impact downstream audio classification tasks. In the context of deep convolutional neural networks in the supervised setting, we show empirically that certain measures of consistency are not implicitly captured by the cross-entropy loss, and that incorporating such measures into the loss function can improve the performance of tasks such as audio tagging. Put another way, we demonstrate how existing augmentation methods can further improve learning by enforcing consistency.
Learning with Out-of-Distribution Data for Audio Classification
Feb 11, 2020In supervised machine learning, the assumption that training data is labelled correctly is not always satisfied. In this paper, we investigate an instance of labelling error for classification tasks in which the dataset is corrupted with out-of-distribution (OOD) instances: data that does not belong to any of the target classes, but is labelled as such. We show that detecting and relabelling certain OOD instances, rather than discarding them, can have a positive effect on learning. The proposed method uses an auxiliary classifier, trained on data that is known to be in-distribution, for detection and relabelling. The amount of data required for this is shown to be small. Experiments are carried out on the FSDnoisy18k audio dataset, where OOD instances are very prevalent. The proposed method is shown to improve the performance of convolutional neural networks by a significant margin. Comparisons with other noise-robust techniques are similarly encouraging.