 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Audio Augmentation Methods with Consistency Learning
Paper and Code
Feb 09, 2021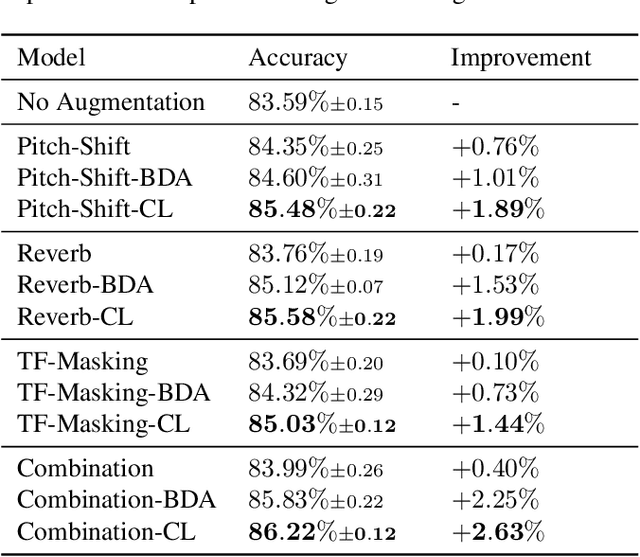

Data augmentation is an inexpensive way to increase training data diversity, and is commonly achieved via transformations of existing data. For tasks such as classification, there is a good case for learning representations of the data that are invariant to such transformations, yet this is not explicitly enforced by classification losses such as the cross-entropy loss. This paper investigates the use of training objectives that explicitly impose this consistency constraint, and how it can impact downstream audio classification tasks. In the context of deep convolutional neural networks in the supervised setting, we show empirically that certain measures of consistency are not implicitly captured by the cross-entropy loss, and that incorporating such measures into the loss function can improve the performance of tasks such as audio tagging. Put another way, we demonstrate how existing augmentation methods can further improve learning by enforcing consistency.