 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCA23K: An audio dataset for investigating open-set label noise
Sep 19, 2021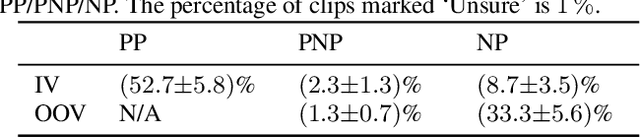
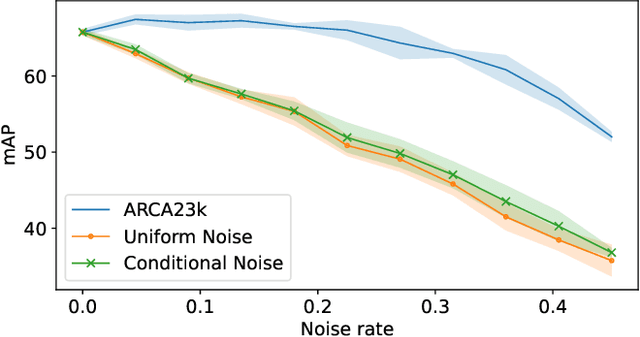

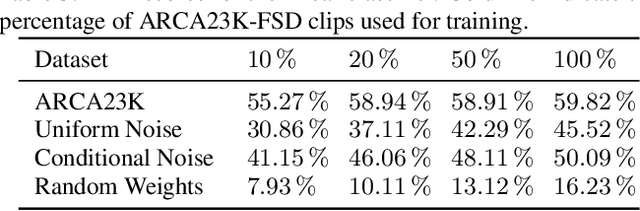
The availability of audio data on sound sharing platforms such as Freesound gives users access to large amounts of annotated audio. Utilising such data for training is becoming increasingly popular, but the problem of label noise that is often prevalent in such datasets requires further investigation. This paper introduces ARCA23K, an Automatically Retrieved and Curated Audio dataset comprised of over 23000 labelled Freesound clips. Unlike past datasets such as FSDKaggle2018 and FSDnoisy18K, ARCA23K facilitates the study of label noise in a more controlled manner. We describe the entire process of creating the dataset such that it is fully reproducible, meaning researchers can extend our work with little effort. We show that the majority of labelling errors in ARCA23K are due to out-of-vocabulary audio clips, and we refer to this type of label noise as open-set label noise. Experiments are carried out in which we study the impact of label noise in terms of classification performance and representation learning.
Raw Audio for Depression Detection Can Be More Robust Against Gender Imbalance than Mel-Spectrogram Features
Oct 28, 2020



Depression is a large-scale mental health problem and a challenging area for machine learning researchers in terms of the detection of depression. Datasets such as the Distress Analysis Interview Corpus - Wizard of Oz have been created to aid research in this area. However, on top of the challenges inherent in accurately detecting depression, biases in datasets may result in skewed classification performance. In this paper we examine gender bias in the DAIC-WOZ dataset using audio-based deep neural networks. We show that gender biases in DAIC-WOZ can lead to an overreporting of performance, which has been overlooked in the past due to the same gender biases being present in the test set. By using raw audio and different concepts from Fair Machine Learning, such as data re-distribution, we can mitigate against the harmful effects of bias.