 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoCoNet: Better Speech Enhancement with Frequency-Positional Embeddings, Semi-Supervised Conversational Data, and Biased Loss
Paper and Code
Aug 11, 2020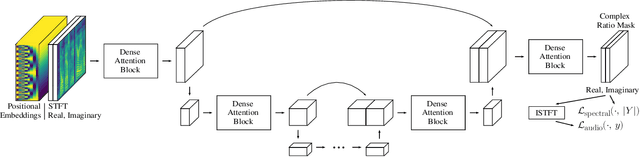
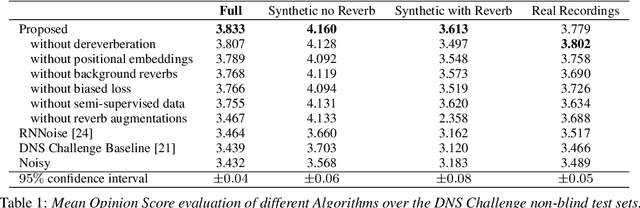
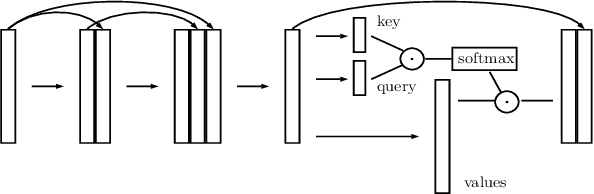
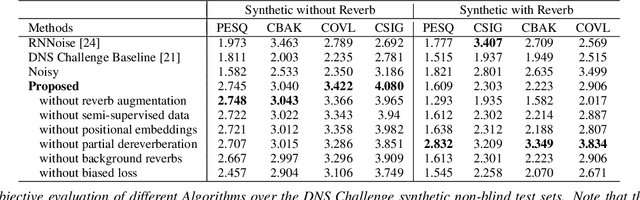
Neural network applications generally benefit from larger-sized models, but for current speech enhancement models, larger scale networks often suffer from decreased robustness to the variety of real-world use cases beyond what is encountered in training data. We introduce several innovations that lead to better large neural networks for speech enhancement. The novel PoCoNet architecture is a convolutional neural network that, with the use of frequency-positional embeddings, is able to more efficiently build frequency-dependent features in the early layers. A semi-supervised method helps increase the amount of conversational training data by pre-enhancing noisy datasets, improving performance on real recordings. A new loss function biased towards preserving speech quality helps the optimization better match human perceptual opinions on speech quality. Ablation experiments and objective and human opinion metrics show the benefits of the proposed improvements.