Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACE: A light-weight, causal model for enhancing coded speech through adaptive convolutions
Paper and Code
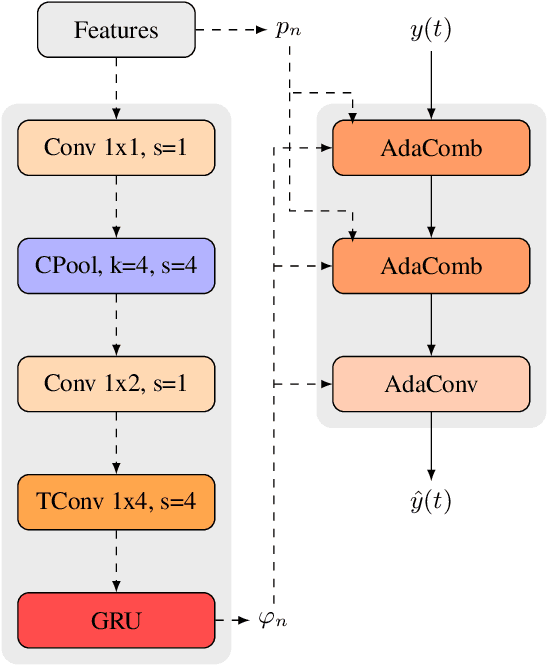



Classical speech coding uses low-complexity postfilters with zero lookahead to enhance the quality of coded speech, but their effectiveness is limited by their simplicity. Deep Neural Networks (DNNs) can be much more effective, but require high complexity and model size, or added delay. We propose a DNN model that generates classical filter kernels on a per-frame basis with a model of just 300~K parameters and 100~MFLOPS complexity, which is a practical complexity for desktop or mobile device CPUs. The lack of added delay allows it to be integrated into the Opus codec, and we demonstrate that it enables effective wideband encoding for bitrates down to 6 kb/s.
* 5 pages, accepted at WASPAA 2023
View paper on