 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement Of Coded Speech Using a Mask-Based Post-Filter
Paper and Code
Oct 12, 2020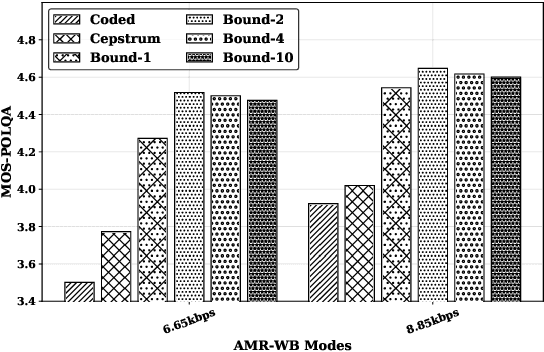
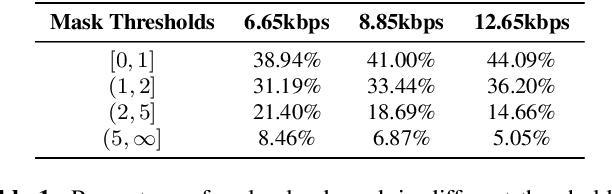

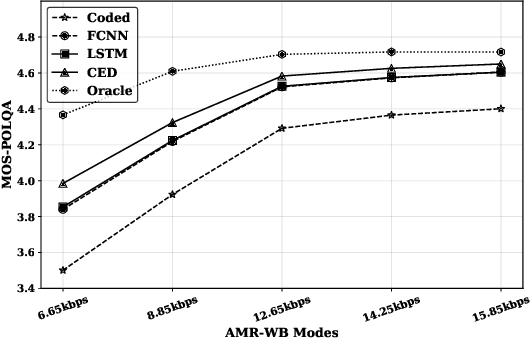
The quality of speech codecs deteriorates at low bitrates due to high quantization noise. A post-filter is generally employed to enhance the quality of the coded speech. In this paper, a data-driven post-filter relying on masking in the time-frequency domain is proposed. A fully connected neural network (FCNN), a convolutional encoder-decoder (CED) network and a long short-term memory (LSTM) network are implemeted to estimate a real-valued mask per time-frequency bin. The proposed models were tested on the five lowest operating modes (6.65 kbps-15.85 kbps) of the Adaptive Multi-Rate Wideband codec (AMR-WB). Both objective and subjective evaluations confirm the enhancement of the coded speech and also show the superiority of the mask-based neural network system over a conventional heuristic post-filter used in the standard like ITU-T G.718.