 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Jul 29, 2024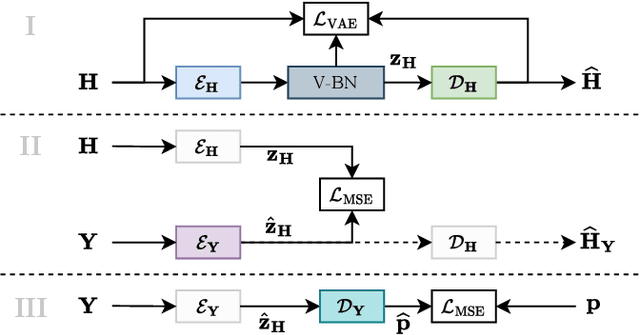
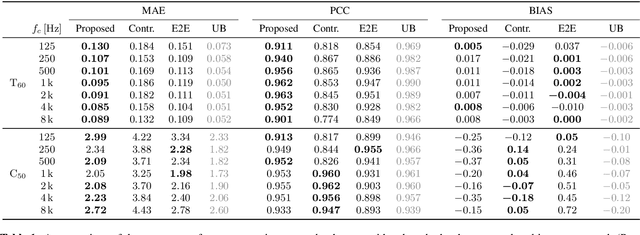
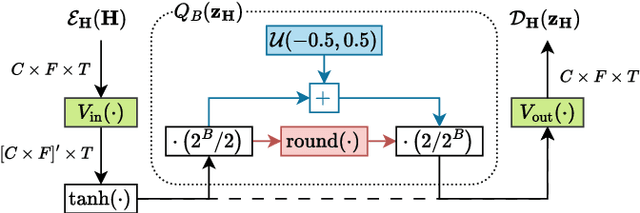
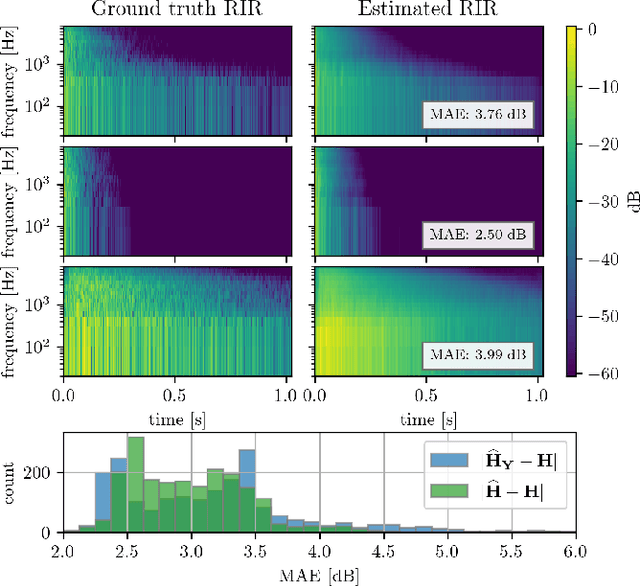
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
Contrastive Representation Learning for Acoustic Parameter Estimation
Mar 13, 2023



A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and perform similarly to a fully-supervised baseline.
AID: Open-source Anechoic Interferer Dataset
Aug 05, 2022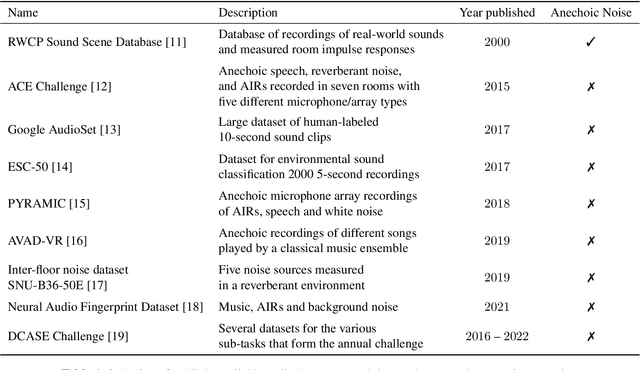

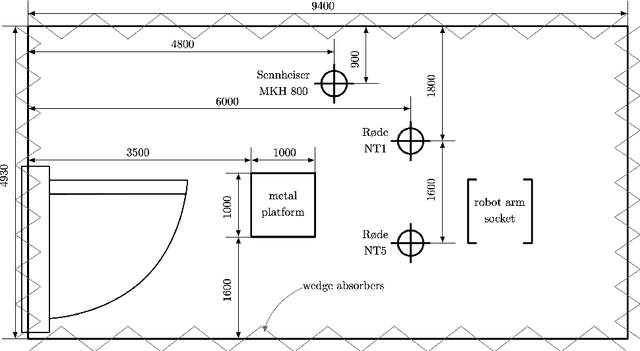

A dataset of anechoic recordings of various sound sources encountered in domestic environments is presented. The dataset is intended to be a resource of non-stationary, environmental noise signals that, when convolved with acoustic impulse responses, can be used to simulate complex acoustic scenes. Additionally, a Python library is provided to generate random mixtures of the recordings in the dataset, which can be used as non-stationary interference signals.
Blind Reverberation Time Estimation in Dynamic Acoustic Conditions
Feb 23, 2022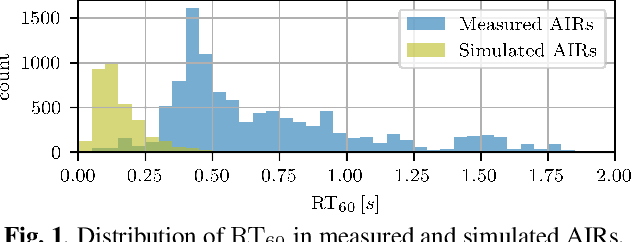

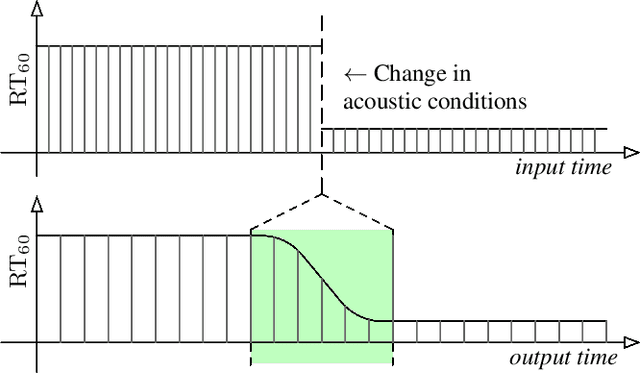
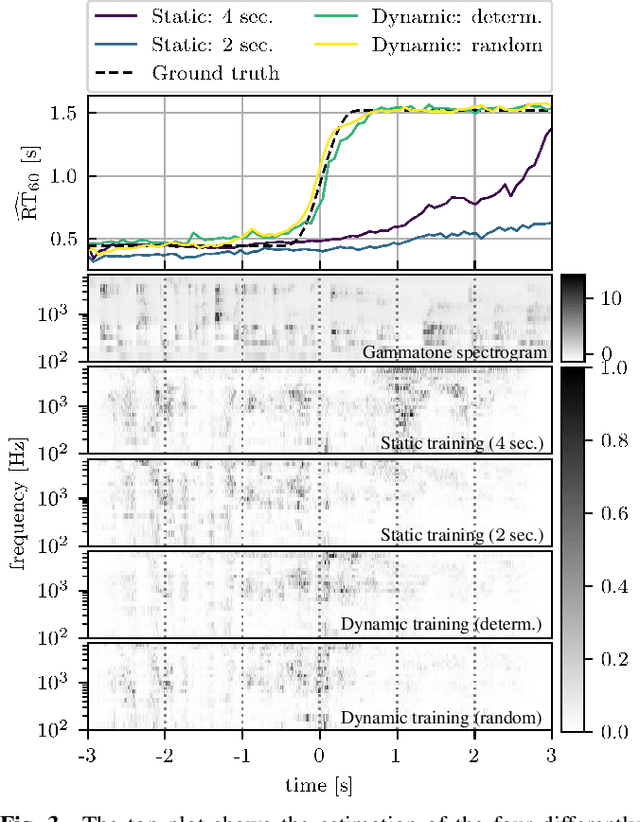
The estimation of reverberation time from real-world signals plays a central role in a wide range of applications. In many scenarios, acoustic conditions change over time which in turn requires the estimate to be updated continuously. Previously proposed methods involving deep neural networks were mostly designed and tested under the assumption of static acoustic conditions. In this work, we show that these approaches can perform poorly in dynamically evolving acoustic environments. Motivated by a recent trend towards data-centric approaches in machine learning, we propose a novel way of generating training data and demonstrate, using an existing deep neural network architecture, the considerable improvement in the ability to follow temporal changes in reverberation time.