Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Paper and Code
Jul 29, 2024
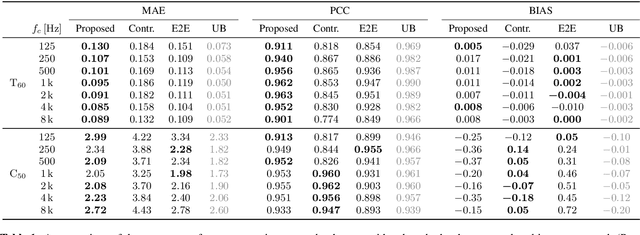
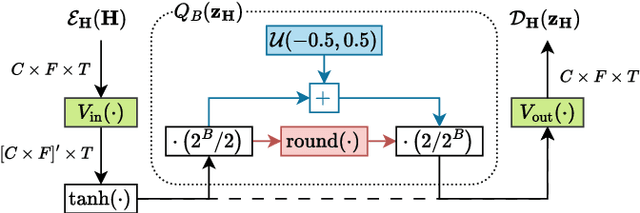
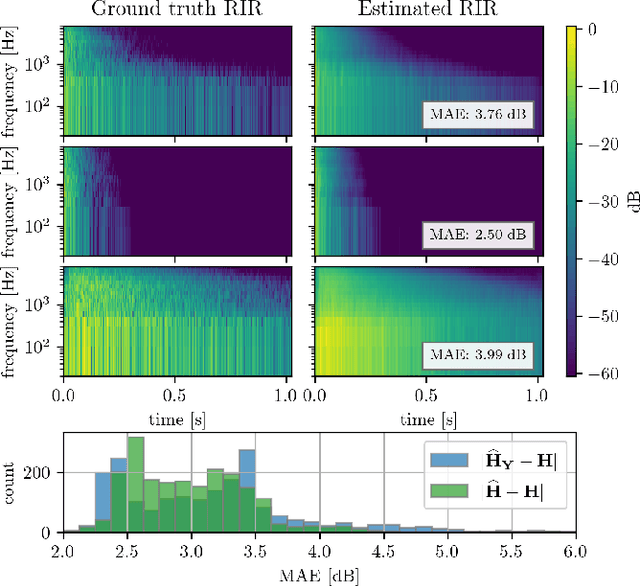
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
* Accepted for publication at IWAENC 2024
View paper on