 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Design of Diffusion-based Neural Speech Codecs
Paper and Code
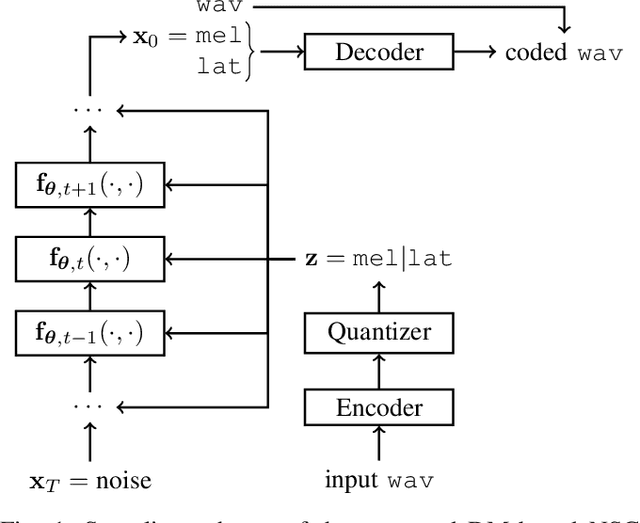
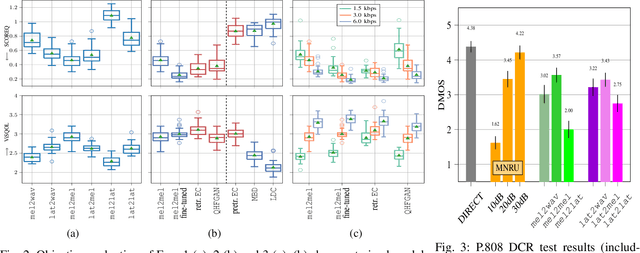
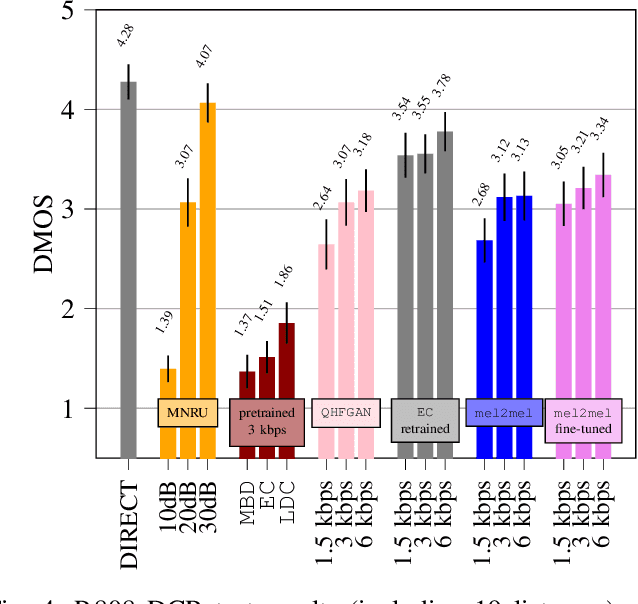

Recently, neural speech codecs (NSCs) trained as generative models have shown superior performance compared to conventional codecs at low bitrates. Although most state-of-the-art NSCs are trained as Generative Adversarial Networks (GANs), Diffusion Models (DMs), a recent class of generative models, represent a promising alternative due to their superior performance in image generation relative to GANs. Consequently, DMs have been successfully applied for audio and speech coding among various other audio generation applications. However, the design of diffusion-based NSCs has not yet been explored in a systematic way. We address this by providing a comprehensive analysis of diffusion-based NSCs divided into three contributions. First, we propose a categorization based on the conditioning and output domains of the DM. This simple conceptual framework allows us to define a design space for diffusion-based NSCs and to assign a category to existing approaches in the literature. Second, we systematically investigate unexplored designs by creating and evaluating new diffusion-based NSCs within the conceptual framework. Finally, we compare the proposed models to existing GAN and DM baselines through objective metrics and subjective listening tests.