 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Joint Control of Acoustic Echo Cancellation, Beamforming and Postfiltering
Paper and Code
Mar 03, 2022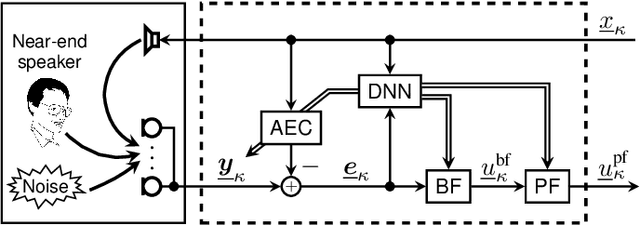
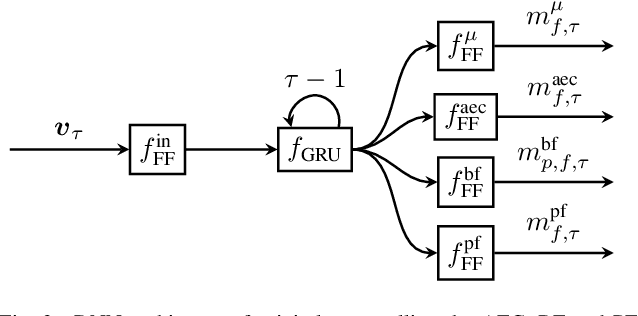
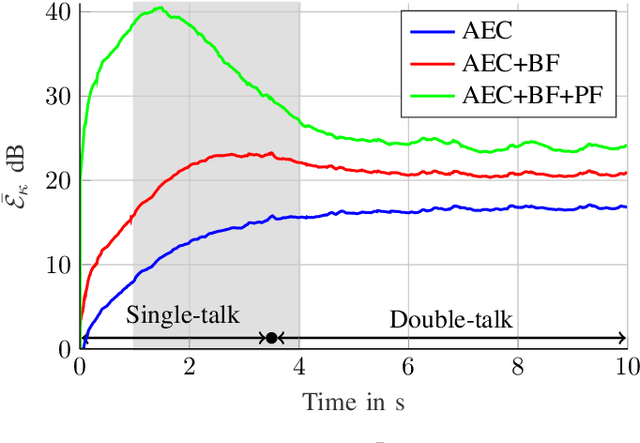
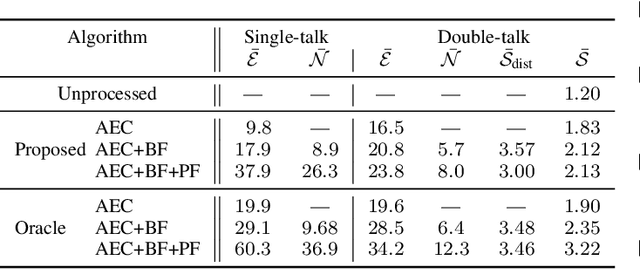
We introduce a novel method for controlling the functionality of a hands-free speech communication device which comprises a model-based acoustic echo canceller (AEC), minimum variance distortionless response (MVDR) beamformer (BF) and spectral postfilter (PF). While the AEC removes the early echo component, the MVDR BF and PF suppress the residual echo and background noise. As key innovation, we suggest to use a single deep neural network (DNN) to jointly control the adaptation of the various algorithmic components. This allows for rapid convergence and high steady-state performance in the presence of high-level interfering double-talk. End-to-end training of the DNN using a time-domain speech extraction loss function avoids the design of individual control strategies.