 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Paper and Code
Oct 27, 2022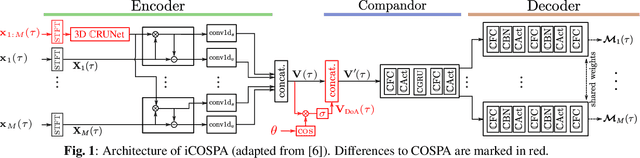
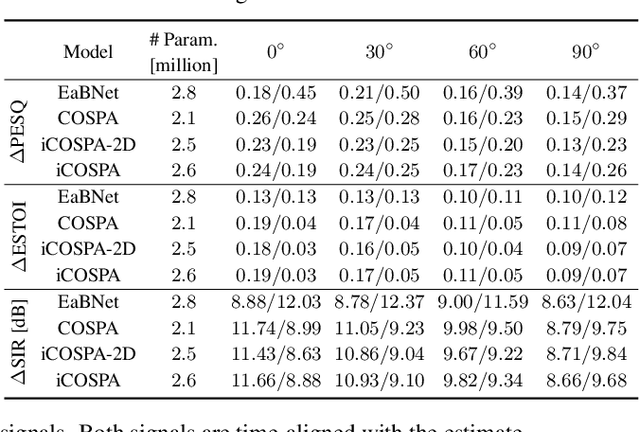

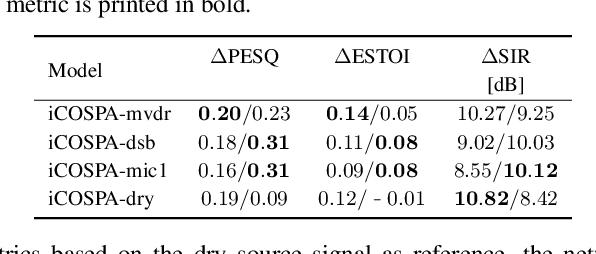
In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.