 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitch Contour Exploration Across Audio Domains: A Vision-Based Transfer Learning Approach
Mar 24, 2025



This study examines pitch contours as a unifying semantic construct prevalent across various audio domains including music, speech, bioacoustics, and everyday sounds. Analyzing pitch contours offers insights into the universal role of pitch in the perceptual processing of audio signals and contributes to a deeper understanding of auditory mechanisms in both humans and animals. Conventional pitch-tracking methods, while optimized for music and speech, face challenges in handling much broader frequency ranges and more rapid pitch variations found in other audio domains. This study introduces a vision-based approach to pitch contour analysis that eliminates the need for explicit pitch-tracking. The approach uses a convolutional neural network, pre-trained for object detection in natural images and fine-tuned with a dataset of synthetically generated pitch contours, to extract key contour parameters from the time-frequency representation of short audio segments. A diverse set of eight downstream tasks from four audio domains were selected to provide a challenging evaluation scenario for cross-domain pitch contour analysis. The results show that the proposed method consistently surpasses traditional techniques based on pitch-tracking on a wide range of tasks. This suggests that the vision-based approach establishes a foundation for comparative studies of pitch contour characteristics across diverse audio domains.
Multi-input Architecture and Disentangled Representation Learning for Multi-dimensional Modeling of Music Similarity
Nov 02, 2021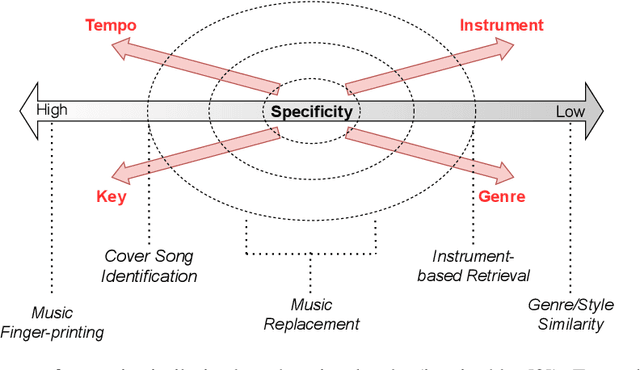


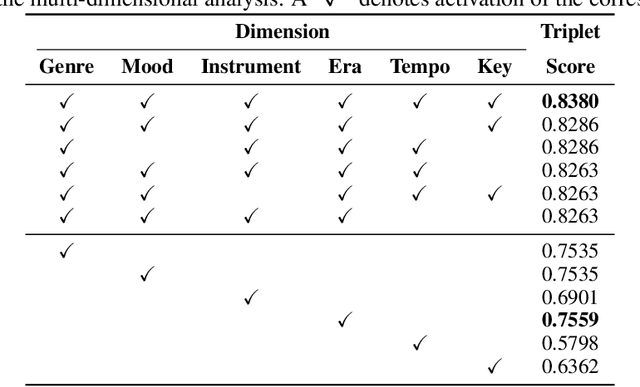
In the context of music information retrieval, similarity-based approaches are useful for a variety of tasks that benefit from a query-by-example scenario. Music however, naturally decomposes into a set of semantically meaningful factors of variation. Current representation learning strategies pursue the disentanglement of such factors from deep representations, resulting in highly interpretable models. This allows the modeling of music similarity perception, which is highly subjective and multi-dimensional. While the focus of prior work is on metadata driven notions of similarity, we suggest to directly model the human notion of multi-dimensional music similarity. To achieve this, we propose a multi-input deep neural network architecture, which simultaneously processes mel-spectrogram, CENS-chromagram and tempogram in order to extract informative features for the different disentangled musical dimensions: genre, mood, instrument, era, tempo, and key. We evaluated the proposed music similarity approach using a triplet prediction task and found that the proposed multi-input architecture outperforms a state of the art method. Furthermore, we present a novel multi-dimensional analysis in order to evaluate the influence of each disentangled dimension on the perception of music similarity.
Towards Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning
Oct 26, 2021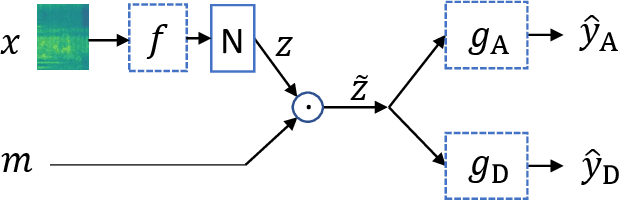
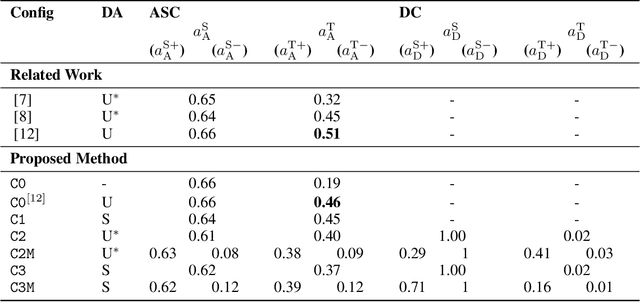

The deployment of machine listening algorithms in real-life applications is often impeded by a domain shift caused for instance by different microphone characteristics. In this paper, we propose a novel domain adaptation strategy based on disentanglement learning. The goal is to disentangle task-specific and domain-specific characteristics in the analyzed audio recordings. In particular, we combine two strategies: First, we apply different binary masks to internal embedding representations and, second, we suggest a novel combination of categorical cross-entropy and variance-based losses. Our results confirm the disentanglement of both tasks on an embedding level but show only minor improvement in the acoustic scene classification performance, when training data from both domains can be used. As a second finding, we can confirm the effectiveness of a state-of-the-art unsupervised domain adaptation strategy, which performs across-domain adaptation on a feature-level instead.
USM-SED - A Dataset for Polyphonic Sound Event Detection in Urban Sound Monitoring Scenarios
May 06, 2021
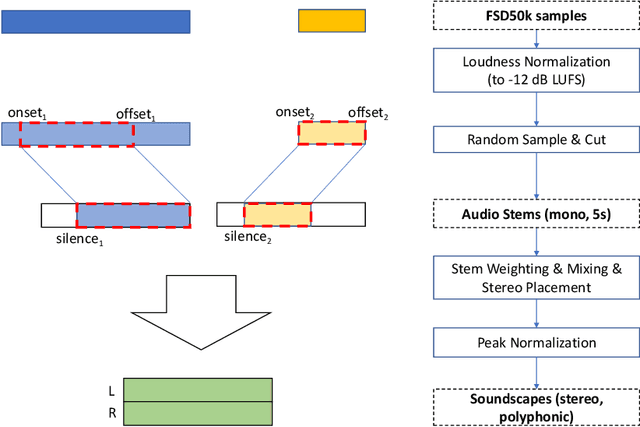
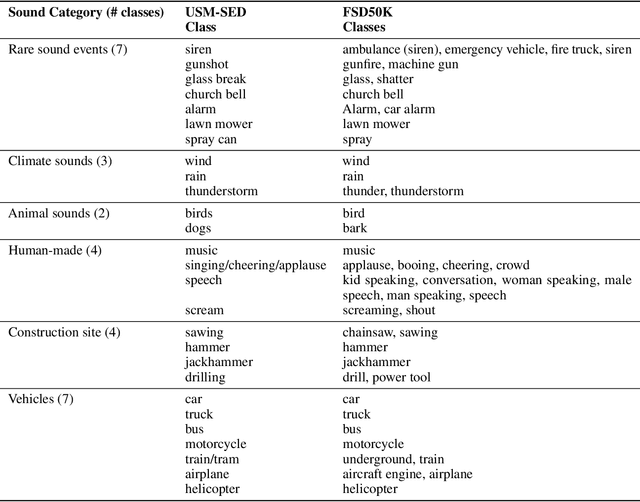
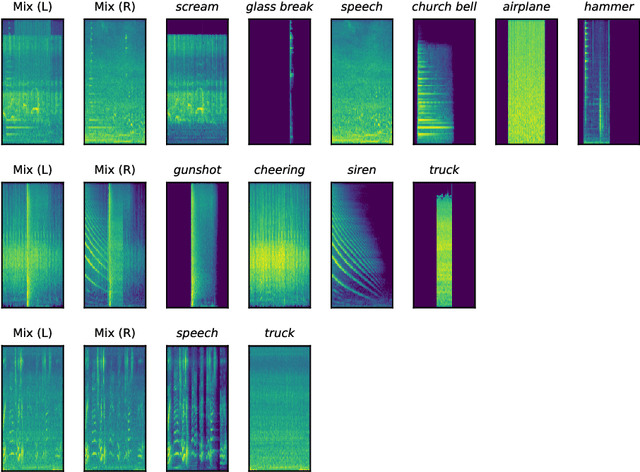
This paper introduces a novel dataset for polyphonic sound event detection in urban sound monitoring use-cases. Based on isolated sounds taken from the FSD50k dataset, 20,000 polyphonic soundscapes are synthesized with sounds being randomly positioned in the stereo panorama using different loudness levels. The paper gives a detailed discussion of possible application scenarios, explains the dataset generation process in detail, and discusses current limitations of the proposed USM-SED dataset.
IDMT-Traffic: An Open Benchmark Dataset for Acoustic Traffic Monitoring Research
Apr 28, 2021
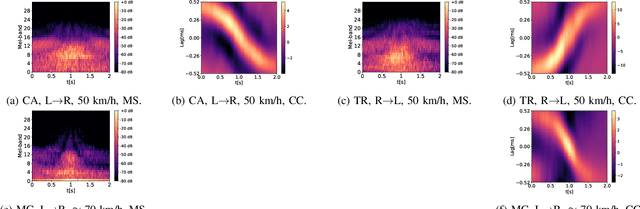
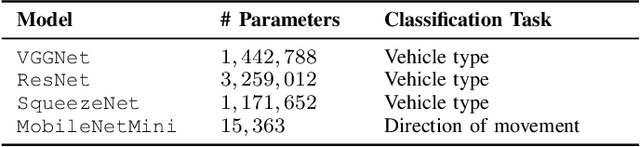
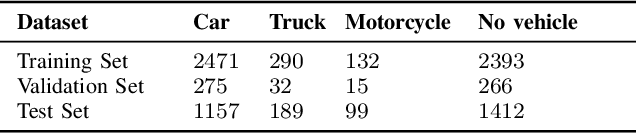
In many urban areas, traffic load and noise pollution are constantly increasing. Automated systems for traffic monitoring are promising countermeasures, which allow to systematically quantify and predict local traffic flow in order to to support municipal traffic planning decisions. In this paper, we present a novel open benchmark dataset, containing 2.5 hours of stereo audio recordings of 4718 vehicle passing events captured with both high-quality sE8 and medium-quality MEMS microphones. This dataset is well suited to evaluate the use-case of deploying audio classification algorithms to embedded sensor devices with restricted microphone quality and hardware processing power. In addition, this paper provides a detailed review of recent acoustic traffic monitoring (ATM) algorithms as well as the results of two benchmark experiments on vehicle type classification and direction of movement estimation using four state-of-the-art convolutional neural network architectures.
DESED-FL and URBAN-FL: Federated Learning Datasets for Sound Event Detection
Feb 19, 2021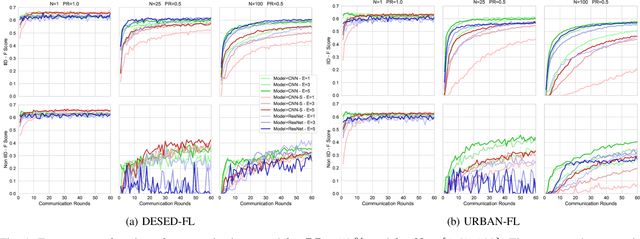
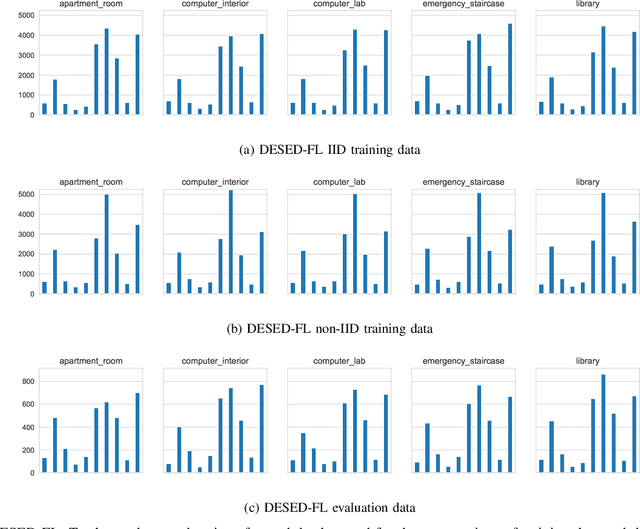
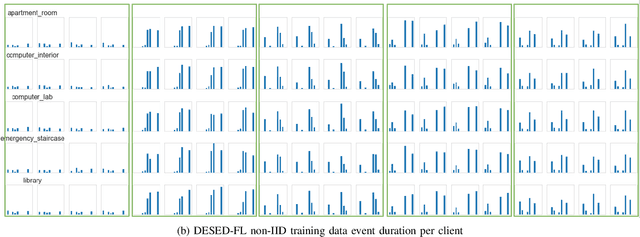
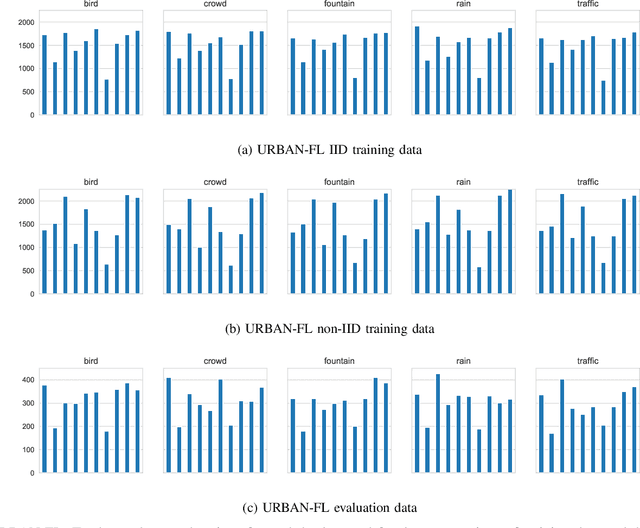
Research on sound event detection (SED) in environmental settings has seen increased attention in recent years. The large amounts of (private) domestic or urban audio data needed raise significant logistical and privacy concerns. The inherently distributed nature of these tasks, make federated learning (FL) a promising approach to take advantage of largescale data while mitigating privacy issues. While FL has also seen increased attention recently, to the best of our knowledge there is no research towards FL for SED. To address this gap and foster further research in this field, we create and publish novel FL datasets for SED in domestic and urban environments. Furthermore, we provide baseline results on the datasets in a FL context for three deep neural network architectures. The results indicate that FL is a promising approach for SED, but faces challenges with divergent data distributions inherent to distributed client edge devices.