 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Periodicity-Based Beat Tracking for Expressive Classical Piano Music
Aug 20, 2023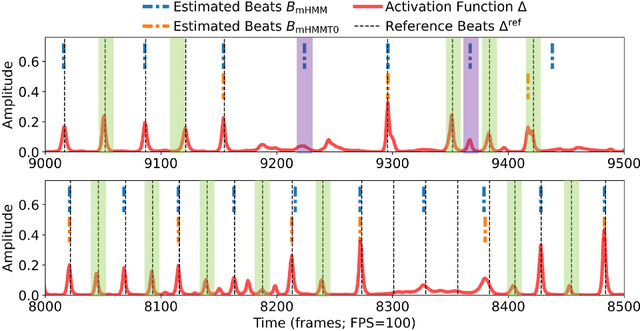
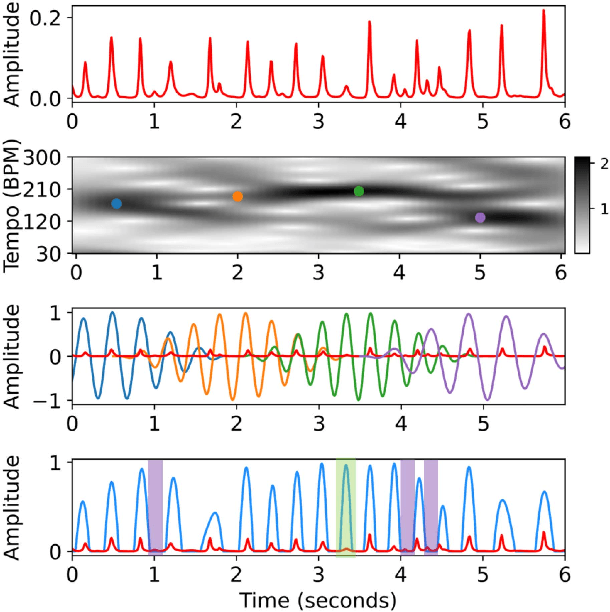
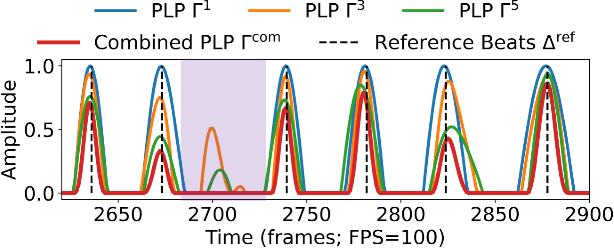
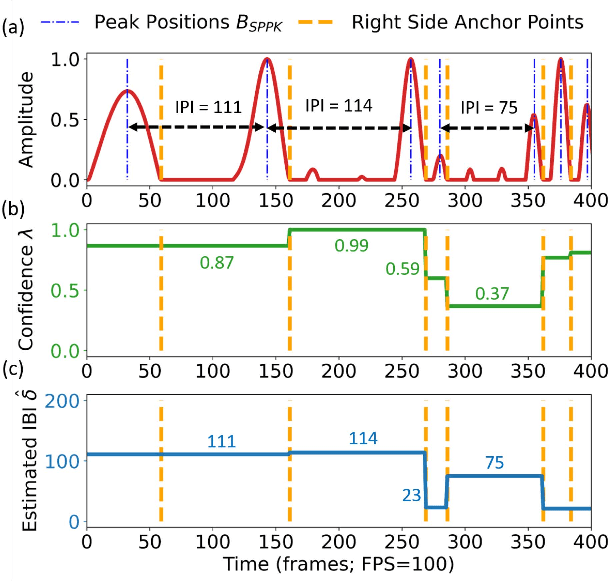
To model the periodicity of beats, state-of-the-art beat tracking systems use "post-processing trackers" (PPTs) that rely on several empirically determined global assumptions for tempo transition, which work well for music with a steady tempo. For expressive classical music, however, these assumptions can be too rigid. With two large datasets of Western classical piano music, namely the Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs to cope with local tempo changes, thus calling for new methods. In this paper, we propose a new local periodicity-based PPT, called predominant local pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible tempo transitions. Specifically, the new PPT incorporates a method called "predominant local pulses" (PLP) in combination with a dynamic programming (DP) component to jointly consider the locally detected periodicity and beat activation strength at each time instant. Accordingly, PLPDP accounts for the local periodicity, rather than relying on a global tempo assumption. Compared to existing PPTs, PLPDP particularly enhances the recall values at the cost of a lower precision, resulting in an overall improvement of F1-score for beat tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).
An Analysis Method for Metric-Level Switching in Beat Tracking
Oct 13, 2022



For expressive music, the tempo may change over time, posing challenges to tracking the beats by an automatic model. The model may first tap to the correct tempo, but then may fail to adapt to a tempo change, or switch between several incorrect but perceptually plausible ones (e.g., half- or double-tempo). Existing evaluation metrics for beat tracking do not reflect such behaviors, as they typically assume a fixed relationship between the reference beats and estimated beats. In this paper, we propose a new performance analysis method, called annotation coverage ratio (ACR), that accounts for a variety of possible metric-level switching behaviors of beat trackers. The idea is to derive sequences of modified reference beats of all metrical levels for every two consecutive reference beats, and compare every sequence of modified reference beats to the subsequences of estimated beats. We show via experiments on three datasets of different genres the usefulness of ACR when utilized alongside existing metrics, and discuss the new insights to be gained.
Source Separation-based Data Augmentation for Improved Joint Beat and Downbeat Tracking
Jun 16, 2021
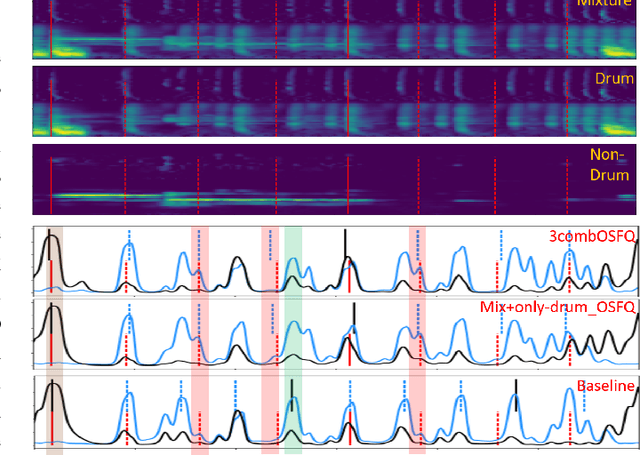
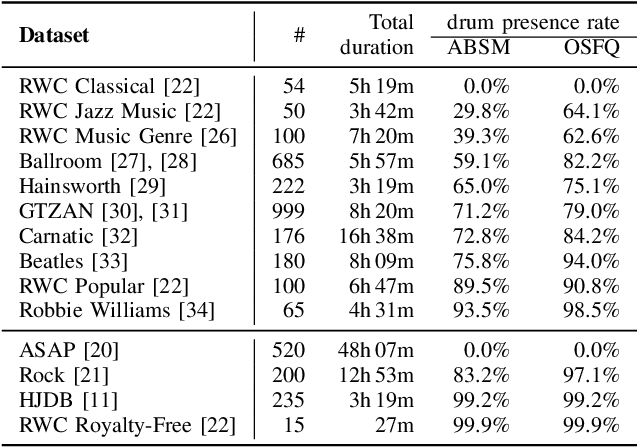
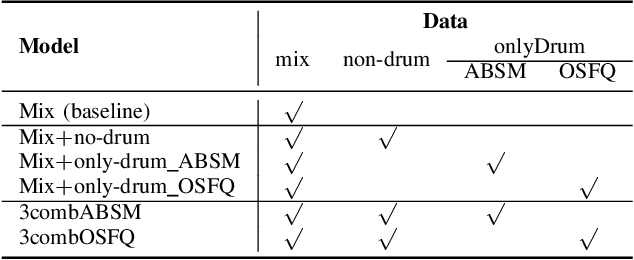
Due to advances in deep learning, the performance of automatic beat and downbeat tracking in musical audio signals has seen great improvement in recent years. In training such deep learning based models, data augmentation has been found an important technique. However, existing data augmentation methods for this task mainly target at balancing the distribution of the training data with respect to their tempo. In this paper, we investigate another approach for data augmentation, to account for the composition of the training data in terms of the percussive and non-percussive sound sources. Specifically, we propose to employ a blind drum separation model to segregate the drum and non-drum sounds from each training audio signal, filtering out training signals that are drumless, and then use the obtained drum and non-drum stems to augment the training data. We report experiments on four completely unseen test sets, validating the effectiveness of the proposed method, and accordingly the importance of drum sound composition in the training data for beat and downbeat tracking.
Drum-Aware Ensemble Architecture for Improved Joint Musical Beat and Downbeat Tracking
Jun 16, 2021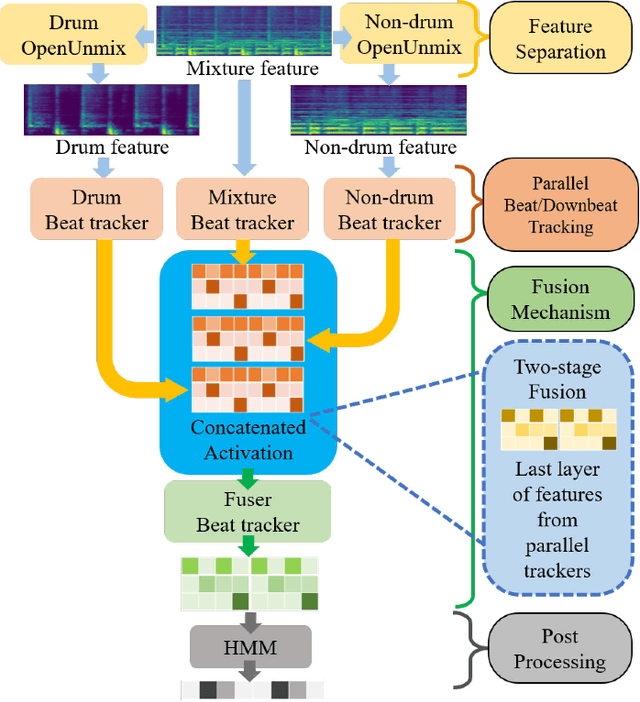
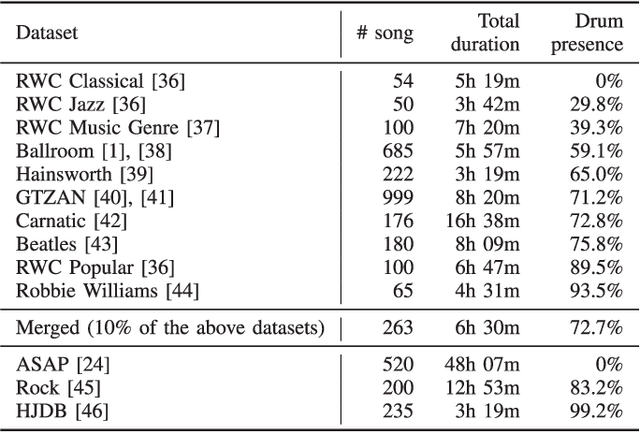
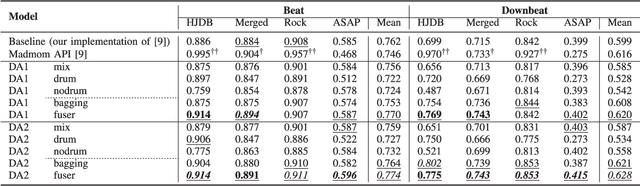
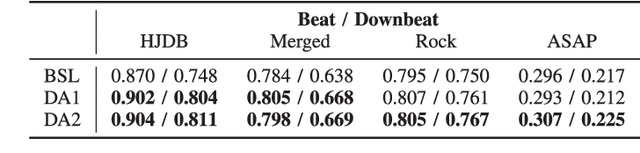
This paper presents a novel system architecture that integrates blind source separation with joint beat and downbeat tracking in musical audio signals. The source separation module segregates the percussive and non-percussive components of the input signal, over which beat and downbeat tracking are performed separately and then the results are aggregated with a learnable fusion mechanism. This way, the system can adaptively determine how much the tracking result for an input signal should depend on the input's percussive or non-percussive components. Evaluation on four testing sets that feature different levels of presence of drum sounds shows that the new architecture consistently outperforms the widely-adopted baseline architecture that does not employ source separation.
Mixing-Specific Data Augmentation Techniques for Improved Blind Violin/Piano Source Separation
Aug 06, 2020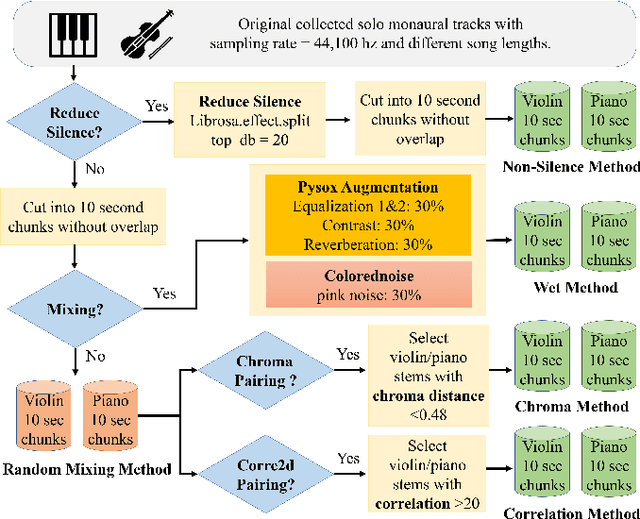
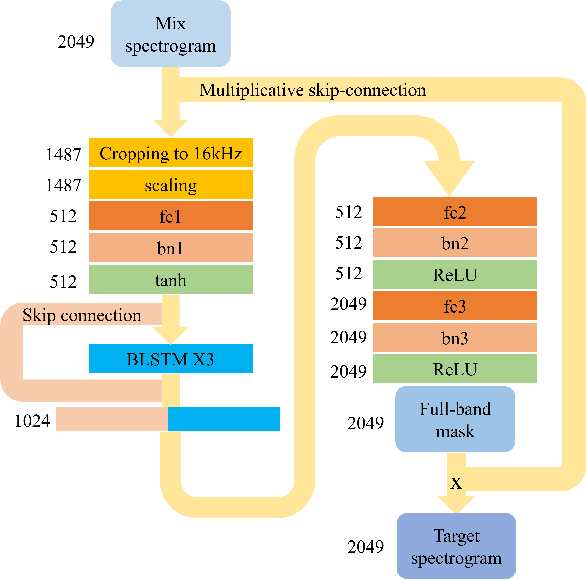
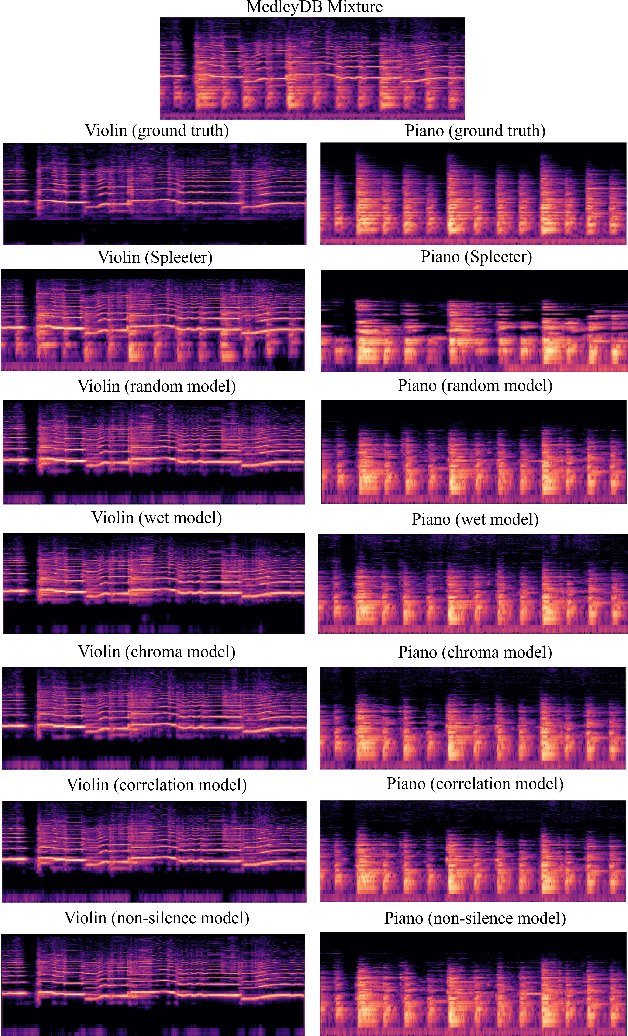
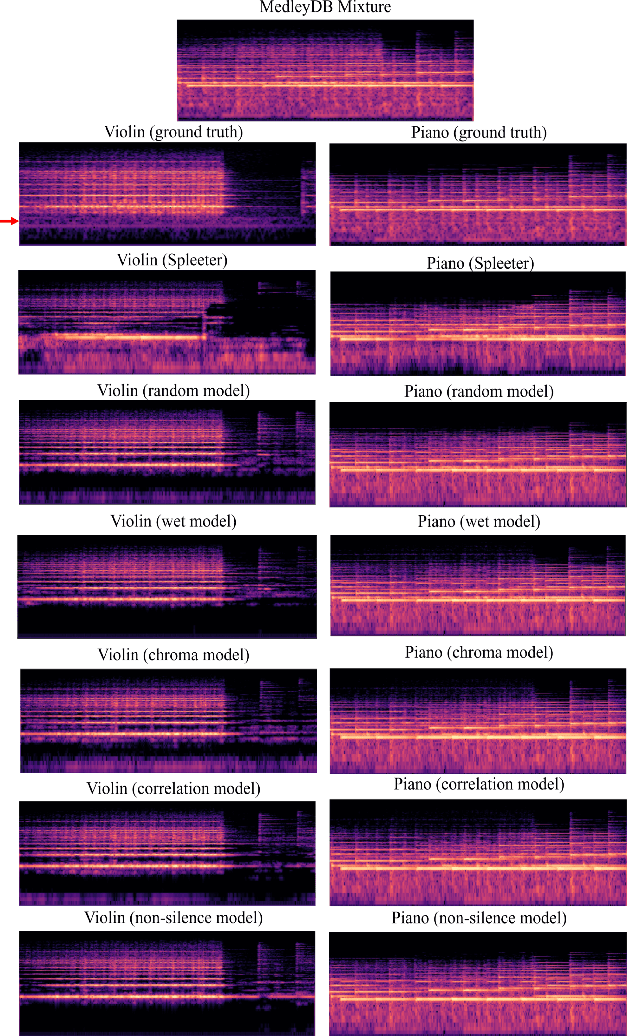
Blind music source separation has been a popular and active subject of research in both the music information retrieval and signal processing communities. To counter the lack of available multi-track data for supervised model training, a data augmentation method that creates artificial mixtures by combining tracks from different songs has been shown useful in recent works. Following this light, we examine further in this paper extended data augmentation methods that consider more sophisticated mixing settings employed in the modern music production routine, the relationship between the tracks to be combined, and factors of silence. As a case study, we consider the separation of violin and piano tracks in a violin piano ensemble, evaluating the performance in terms of common metrics, namely SDR, SIR, and SAR. In addition to examining the effectiveness of these new data augmentation methods, we also study the influence of the amount of training data. Our evaluation shows that the proposed mixing-specific data augmentation methods can help improve the performance of a deep learning-based model for source separation, especially in the case of small training data.