 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Data Distribution Gap in Music Emotion Recognition
Oct 06, 2025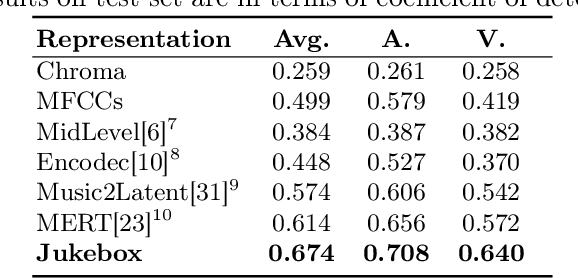
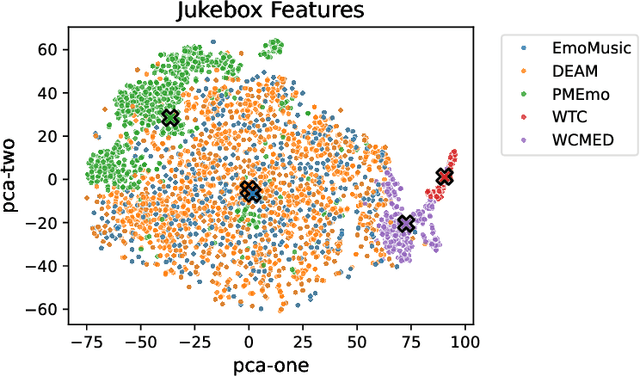
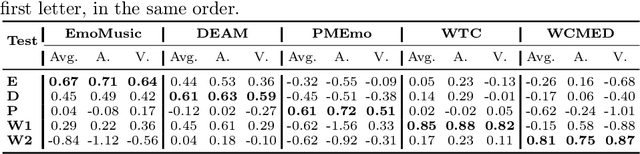
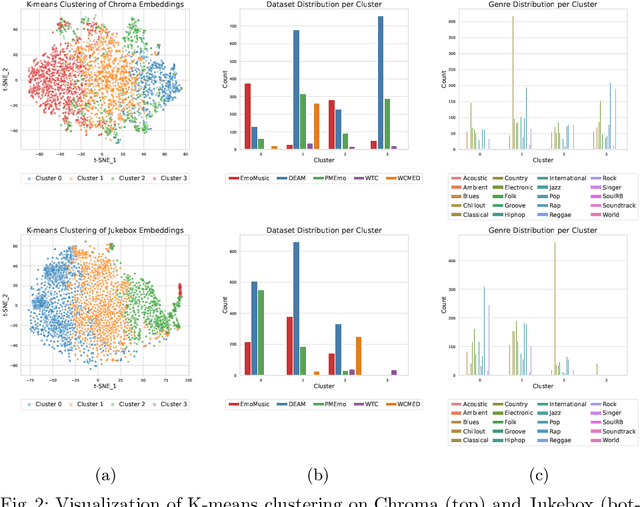
Music Emotion Recognition (MER) is a task deeply connected to human perception, relying heavily on subjective annotations collected from contributors. Prior studies tend to focus on specific musical styles rather than incorporating a diverse range of genres, such as rock and classical, within a single framework. In this paper, we address the task of recognizing emotion from audio content by investigating five datasets with dimensional emotion annotations -- EmoMusic, DEAM, PMEmo, WTC, and WCMED -- which span various musical styles. We demonstrate the problem of out-of-distribution generalization in a systematic experiment. By closely looking at multiple data and feature sets, we provide insight into genre-emotion relationships in existing data and examine potential genre dominance and dataset biases in certain feature representations. Based on these experiments, we arrive at a simple yet effective framework that combines embeddings extracted from the Jukebox model with chroma features and demonstrate how, alongside a combination of several diverse training sets, this permits us to train models with substantially improved cross-dataset generalization capabilities.
Language Models for Music Medicine Generation
Nov 13, 2024
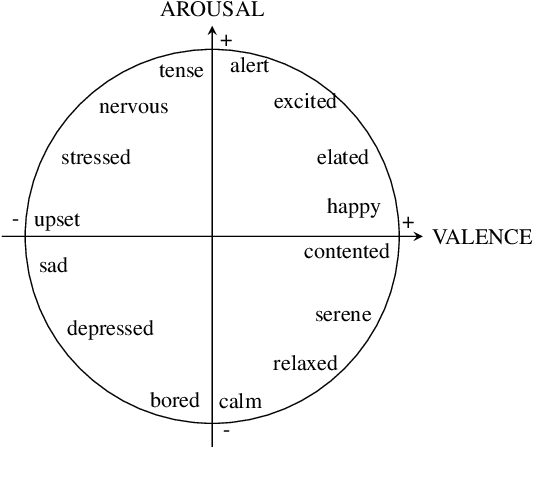
Music therapy has been shown in recent years to provide multiple health benefits related to emotional wellness. In turn, maintaining a healthy emotional state has proven to be effective for patients undergoing treatment, such as Parkinson's patients or patients suffering from stress and anxiety. We propose fine-tuning MusicGen, a music-generating transformer model, to create short musical clips that assist patients in transitioning from negative to desired emotional states. Using low-rank decomposition fine-tuning on the MTG-Jamendo Dataset with emotion tags, we generate 30-second clips that adhere to the iso principle, guiding patients through intermediate states in the valence-arousal circumplex. The generated music is evaluated using a music emotion recognition model to ensure alignment with intended emotions. By concatenating these clips, we produce a 15-minute "music medicine" resembling a music therapy session. Our approach is the first model to leverage Language Models to generate music medicine. Ultimately, the output is intended to be used as a temporary relief between music therapy sessions with a board-certified therapist.
Learning To Generate Piano Music With Sustain Pedals
Nov 01, 2021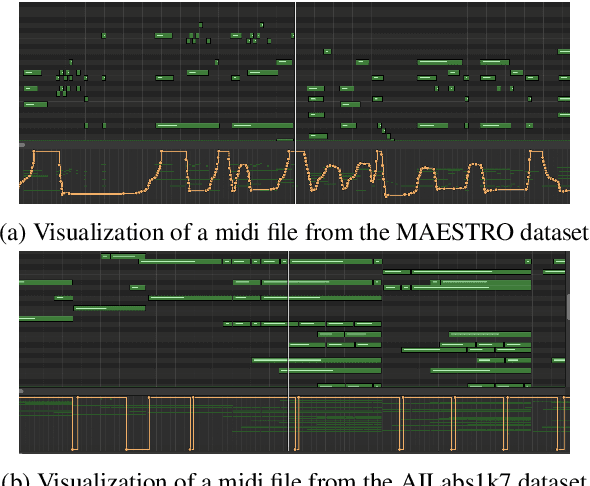
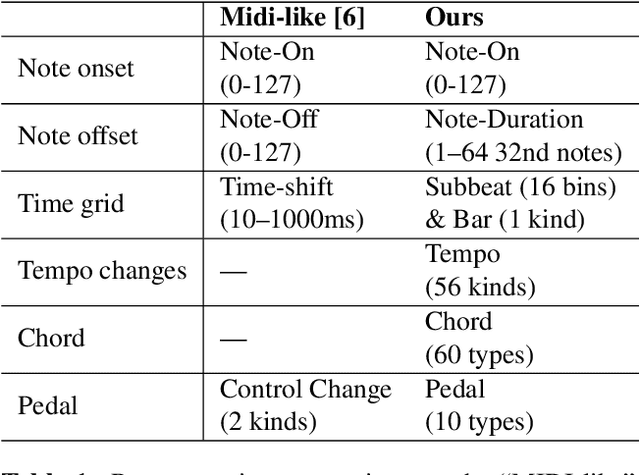
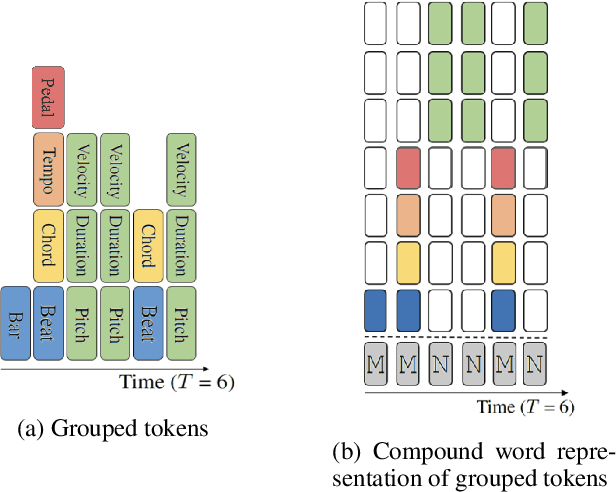
Recent years have witnessed a growing interest in research related to the detection of piano pedals from audio signals in the music information retrieval community. However, to our best knowledge, recent generative models for symbolic music have rarely taken piano pedals into account. In this work, we employ the transcription model proposed by Kong et al. to get pedal information from the audio recordings of piano performance in the AILabs1k7 dataset, and then modify the Compound Word Transformer proposed by Hsiao et al. to build a Transformer decoder that generates pedal-related tokens along with other musical tokens. While the work is done by using inferred sustain pedal information as training data, the result shows hope for further improvement and the importance of the involvement of sustain pedal in tasks of piano performance generations.
EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-based Music Generation
Aug 03, 2021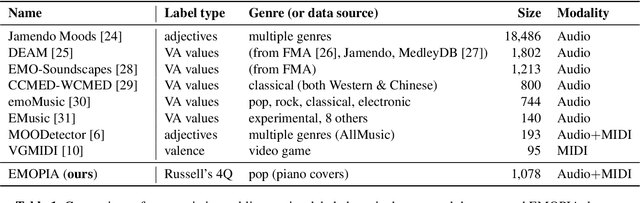
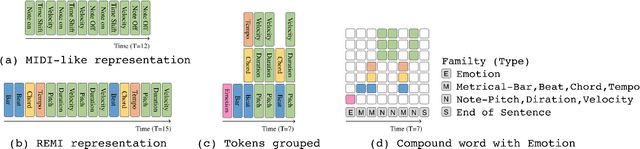
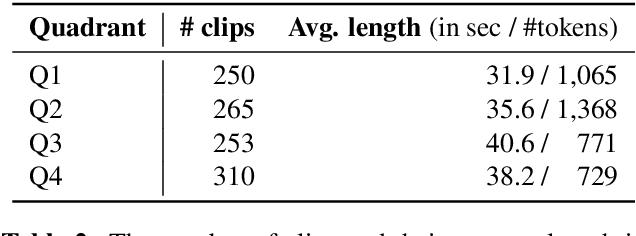
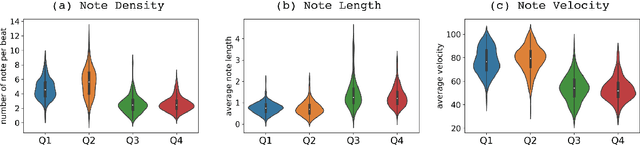
While there are many music datasets with emotion labels in the literature, they cannot be used for research on symbolic-domain music analysis or generation, as there are usually audio files only. In this paper, we present the EMOPIA (pronounced `yee-m\`{o}-pi-uh') dataset, a shared multi-modal (audio and MIDI) database focusing on perceived emotion in pop piano music, to facilitate research on various tasks related to music emotion. The dataset contains 1,087 music clips from 387 songs and clip-level emotion labels annotated by four dedicated annotators. Since the clips are not restricted to one clip per song, they can also be used for song-level analysis. We present the methodology for building the dataset, covering the song list curation, clip selection, and emotion annotation processes. Moreover, we prototype use cases on clip-level music emotion classification and emotion-based symbolic music generation by training and evaluating corresponding models using the dataset. The result demonstrates the potential of EMOPIA for being used in future exploration on piano emotion-related MIR tasks.
MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding
Jul 12, 2021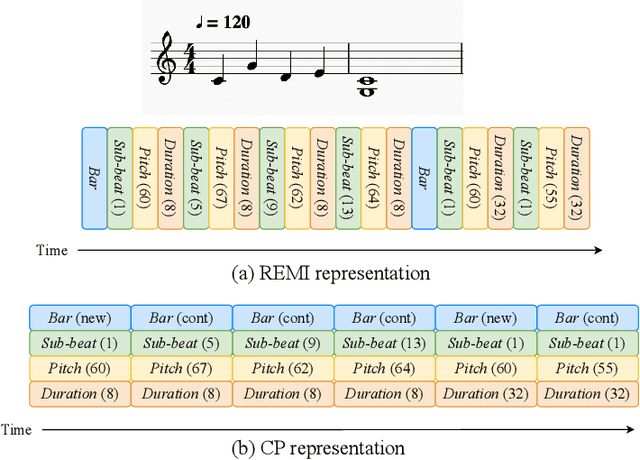
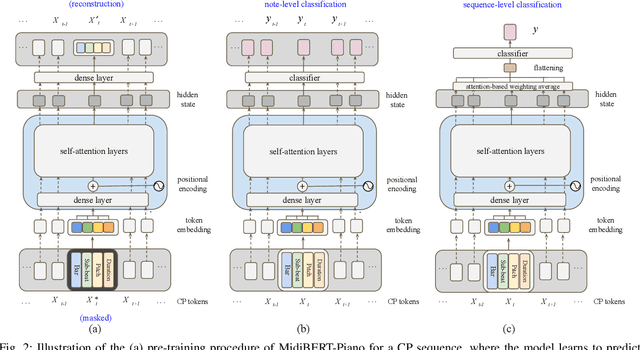
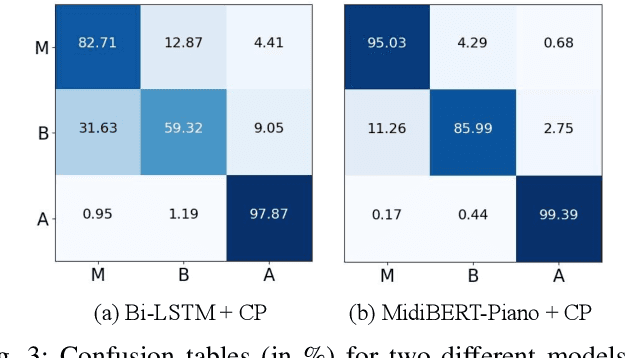
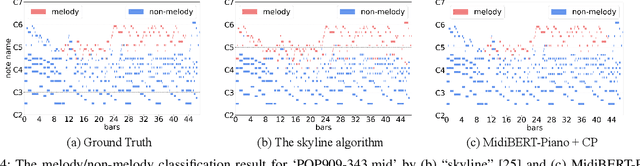
This paper presents an attempt to employ the mask language modeling approach of BERT to pre-train a 12-layer Transformer model over 4,166 pieces of polyphonic piano MIDI files for tackling a number of symbolic-domain discriminative music understanding tasks. These include two note-level classification tasks, i.e., melody extraction and velocity prediction, as well as two sequence-level classification tasks, i.e., composer classification and emotion classification. We find that, given a pre-trained Transformer, our models outperform recurrent neural network based baselines with less than 10 epochs of fine-tuning. Ablation studies show that the pre-training remains effective even if none of the MIDI data of the downstream tasks are seen at the pre-training stage, and that freezing the self-attention layers of the Transformer at the fine-tuning stage slightly degrades performance. All the five datasets employed in this work are publicly available, as well as checkpoints of our pre-trained and fine-tuned models. As such, our research can be taken as a benchmark for symbolic-domain music understanding.
Source Separation-based Data Augmentation for Improved Joint Beat and Downbeat Tracking
Jun 16, 2021
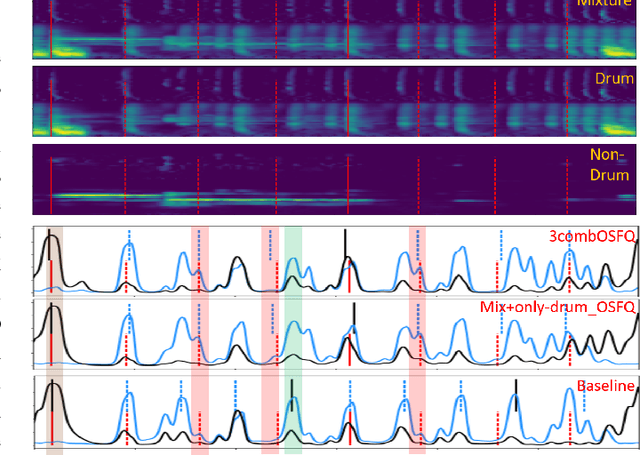
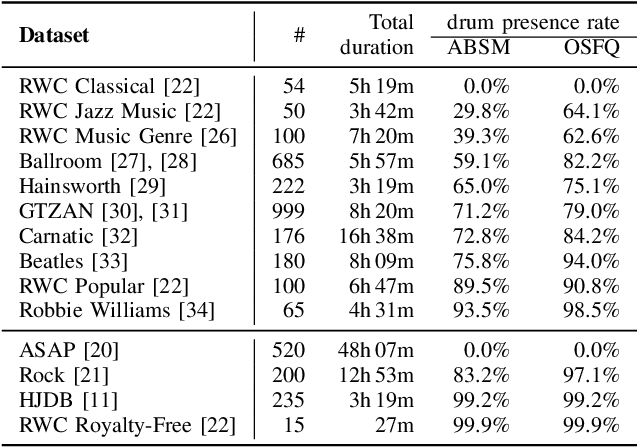
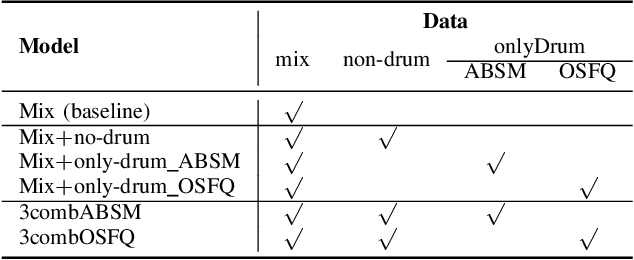
Due to advances in deep learning, the performance of automatic beat and downbeat tracking in musical audio signals has seen great improvement in recent years. In training such deep learning based models, data augmentation has been found an important technique. However, existing data augmentation methods for this task mainly target at balancing the distribution of the training data with respect to their tempo. In this paper, we investigate another approach for data augmentation, to account for the composition of the training data in terms of the percussive and non-percussive sound sources. Specifically, we propose to employ a blind drum separation model to segregate the drum and non-drum sounds from each training audio signal, filtering out training signals that are drumless, and then use the obtained drum and non-drum stems to augment the training data. We report experiments on four completely unseen test sets, validating the effectiveness of the proposed method, and accordingly the importance of drum sound composition in the training data for beat and downbeat tracking.