 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Score Expansion with Variable-Length Infilling
Nov 11, 2021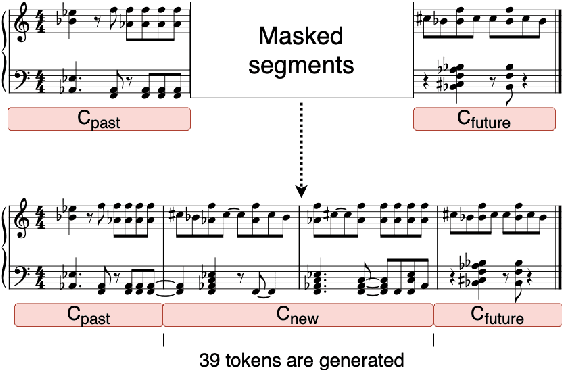
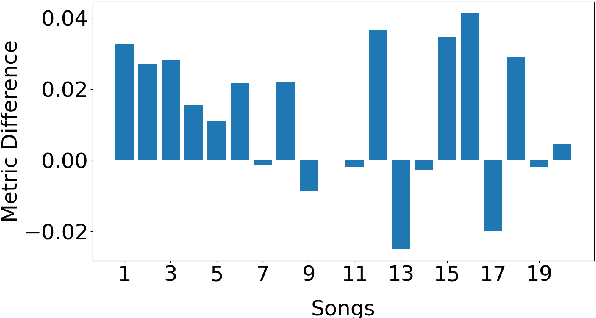

In this paper, we investigate using the variable-length infilling (VLI) model, which is originally proposed to infill missing segments, to "prolong" existing musical segments at musical boundaries. Specifically, as a case study, we expand 20 musical segments from 12 bars to 16 bars, and examine the degree to which the VLI model preserves musical boundaries in the expanded results using a few objective metrics, including the Register Histogram Similarity we newly propose. The results show that the VLI model has the potential to address the expansion task.
Variable-Length Music Score Infilling via XLNet and Musically Specialized Positional Encoding
Aug 11, 2021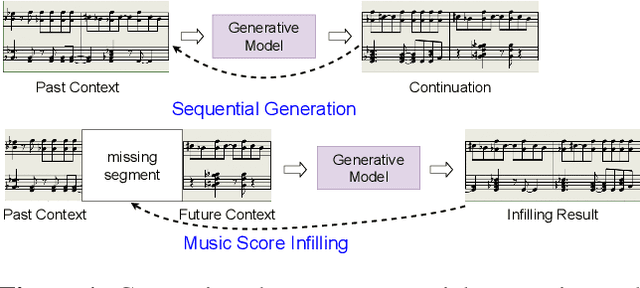



This paper proposes a new self-attention based model for music score infilling, i.e., to generate a polyphonic music sequence that fills in the gap between given past and future contexts. While existing approaches can only fill in a short segment with a fixed number of notes, or a fixed time span between the past and future contexts, our model can infill a variable number of notes (up to 128) for different time spans. We achieve so with three major technical contributions. First, we adapt XLNet, an autoregressive model originally proposed for unsupervised model pre-training, to music score infilling. Second, we propose a new, musically specialized positional encoding called relative bar encoding that better informs the model of notes' position within the past and future context. Third, to capitalize relative bar encoding, we perform look-ahead onset prediction to predict the onset of a note one time step before predicting the other attributes of the note. We compare our proposed model with two strong baselines and show that our model is superior in both objective and subjective analyses.
MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding
Jul 12, 2021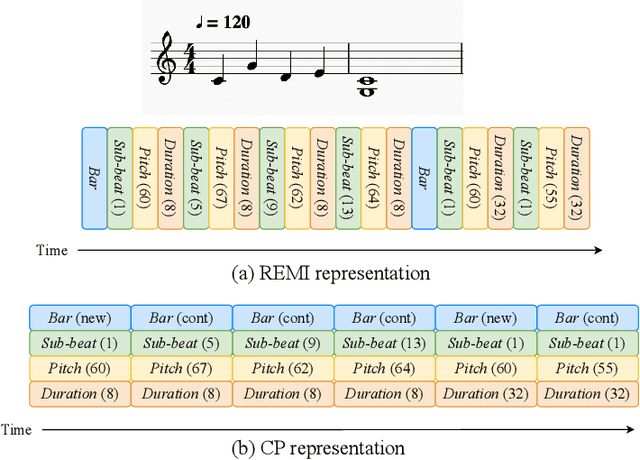
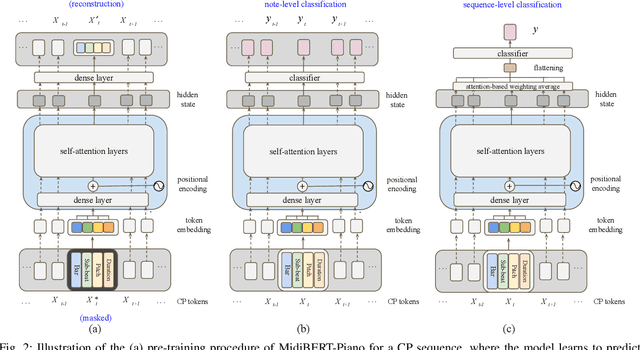
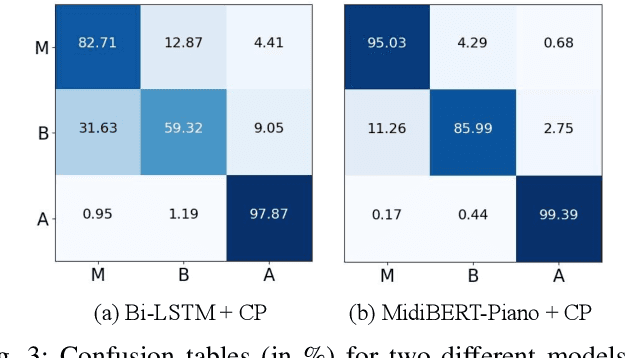
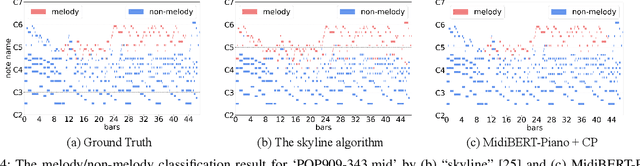
This paper presents an attempt to employ the mask language modeling approach of BERT to pre-train a 12-layer Transformer model over 4,166 pieces of polyphonic piano MIDI files for tackling a number of symbolic-domain discriminative music understanding tasks. These include two note-level classification tasks, i.e., melody extraction and velocity prediction, as well as two sequence-level classification tasks, i.e., composer classification and emotion classification. We find that, given a pre-trained Transformer, our models outperform recurrent neural network based baselines with less than 10 epochs of fine-tuning. Ablation studies show that the pre-training remains effective even if none of the MIDI data of the downstream tasks are seen at the pre-training stage, and that freezing the self-attention layers of the Transformer at the fine-tuning stage slightly degrades performance. All the five datasets employed in this work are publicly available, as well as checkpoints of our pre-trained and fine-tuned models. As such, our research can be taken as a benchmark for symbolic-domain music understanding.
Reducing the Deployment-Time Inference Control Costs of Deep Reinforcement Learning Agents via an Asymmetric Architecture
May 30, 2021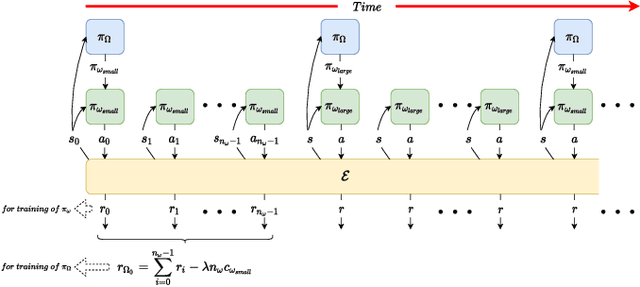
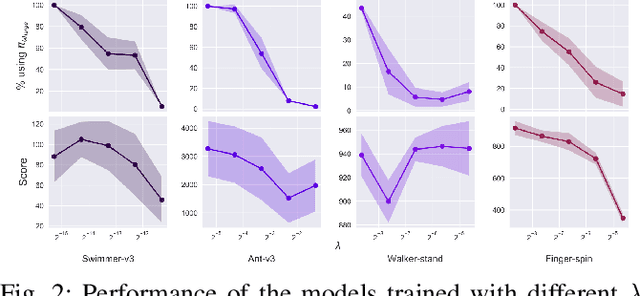
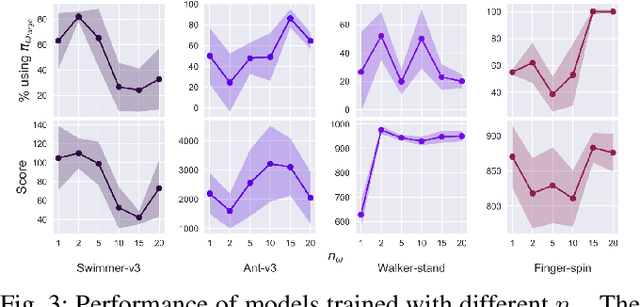
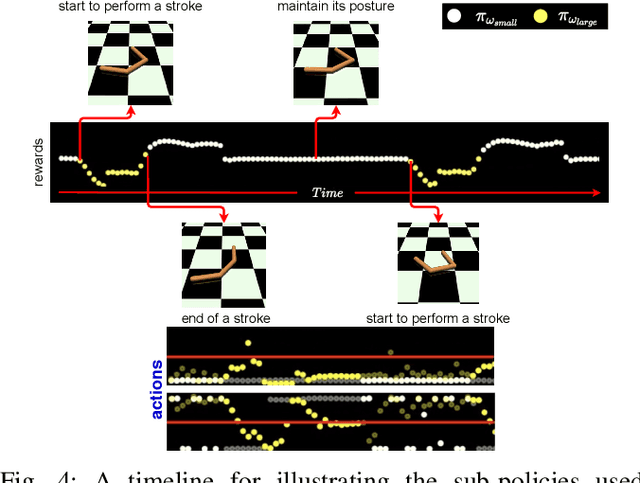
Deep reinforcement learning (DRL) has been demonstrated to provide promising results in several challenging decision making and control tasks. However, the required inference costs of deep neural networks (DNNs) could prevent DRL from being applied to mobile robots which cannot afford high energy-consuming computations. To enable DRL methods to be affordable in such energy-limited platforms, we propose an asymmetric architecture that reduces the overall inference costs via switching between a computationally expensive policy and an economic one. The experimental results evaluated on a number of representative benchmark suites for robotic control tasks demonstrate that our method is able to reduce the inference costs while retaining the agent's overall performance.