 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the Most of Limited Data: Score-Aware Training for Text-to-Music Generation
Jun 05, 2026State-of-the-art text-to-music generation systems rely on massive proprietary datasets and industrial-scale compute, making it impossible to disentangle architectural contributions from resource advantages. We propose \textit{score-aware training}, which treats audio-caption alignment score as a direct supervision signal throughout the pipeline. Rather than discarding low-scoring segments, we repurpose them via a CLAP-conditioned Beta noise timestep schedule that routes them to high-noise training regimes, acting as an effective implicit regularizer. Complementarily, segment-level filtering removes the most misaligned examples, and a two-stage caption procedure bridges the distribution gap between verbose training captions and concise inference prompts. A REPA auxiliary loss further transfers structured semantic knowledge from pretrained CLAP and MuQ encoders without additional data. Our 450M-parameter FluxAudio-based system, submitted to the ICME 2026 ATTM Grand Challenge Efficiency Track, ranked 2nd across both tracks in the objective evaluation and 3rd in the Efficiency Track in the final MOS evaluation.
PiCoGen2: Piano cover generation with transfer learning approach and weakly aligned data
Aug 02, 2024Piano cover generation aims to create a piano cover from a pop song. Existing approaches mainly employ supervised learning and the training demands strongly-aligned and paired song-to-piano data, which is built by remapping piano notes to song audio. This would, however, result in the loss of piano information and accordingly cause inconsistencies between the original and remapped piano versions. To overcome this limitation, we propose a transfer learning approach that pre-trains our model on piano-only data and fine-tunes it on weakly-aligned paired data constructed without note remapping. During pre-training, to guide the model to learn piano composition concepts instead of merely transcribing audio, we use an existing lead sheet transcription model as the encoder to extract high-level features from the piano recordings. The pre-trained model is then fine-tuned on the paired song-piano data to transfer the learned composition knowledge to the pop song domain. Our evaluation shows that this training strategy enables our model, named PiCoGen2, to attain high-quality results, outperforming baselines on both objective and subjective metrics across five pop genres.
PiCoGen: Generate Piano Covers with a Two-stage Approach
Jul 30, 2024Cover song generation stands out as a popular way of music making in the music-creative community. In this study, we introduce Piano Cover Generation (PiCoGen), a two-stage approach for automatic cover song generation that transcribes the melody line and chord progression of a song given its audio recording, and then uses the resulting lead sheet as the condition to generate a piano cover in the symbolic domain. This approach is advantageous in that it does not required paired data of covers and their original songs for training. Compared to an existing approach that demands such paired data, our evaluation shows that PiCoGen demonstrates competitive or even superior performance across songs of different musical genres.
Melody Infilling with User-Provided Structural Context
Oct 06, 2022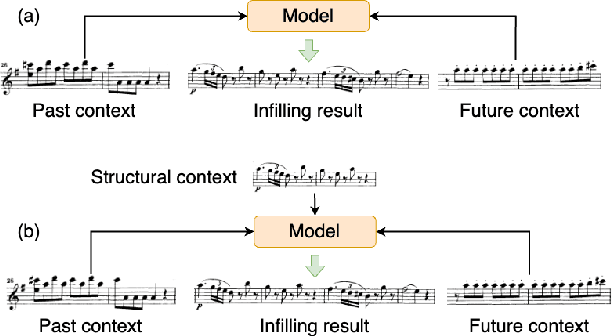
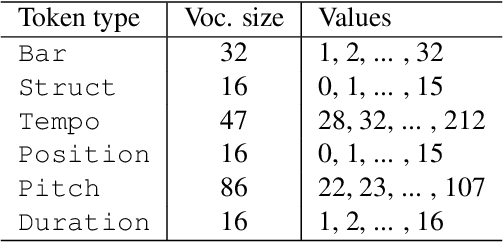
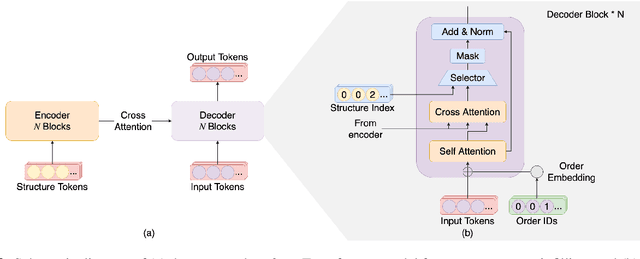

This paper proposes a novel Transformer-based model for music score infilling, to generate a music passage that fills in the gap between given past and future contexts. While existing infilling approaches can generate a passage that connects smoothly locally with the given contexts, they do not take into account the musical form or structure of the music and may therefore generate overly smooth results. To address this issue, we propose a structure-aware conditioning approach that employs a novel attention-selecting module to supply user-provided structure-related information to the Transformer for infilling. With both objective and subjective evaluations, we show that the proposed model can harness the structural information effectively and generate melodies in the style of pop of higher quality than the two existing structure-agnostic infilling models.
Music Score Expansion with Variable-Length Infilling
Nov 11, 2021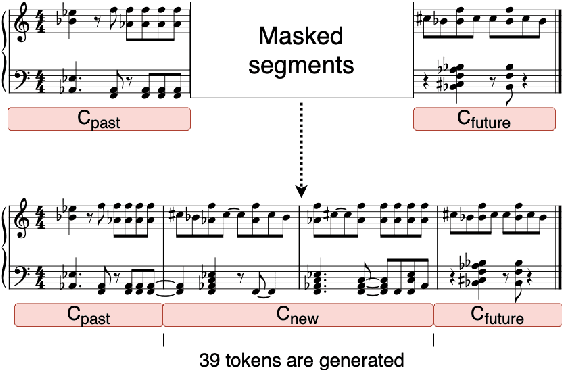
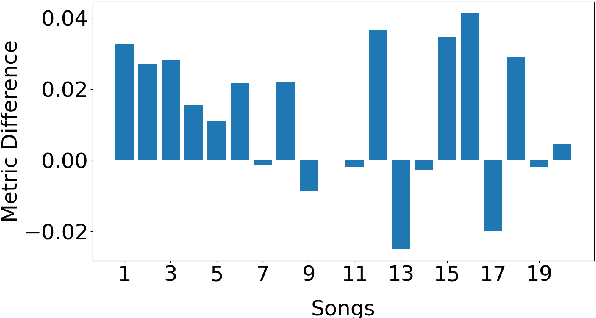

In this paper, we investigate using the variable-length infilling (VLI) model, which is originally proposed to infill missing segments, to "prolong" existing musical segments at musical boundaries. Specifically, as a case study, we expand 20 musical segments from 12 bars to 16 bars, and examine the degree to which the VLI model preserves musical boundaries in the expanded results using a few objective metrics, including the Register Histogram Similarity we newly propose. The results show that the VLI model has the potential to address the expansion task.