 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreak-the-Beat! Controllable MIDI-to-Drum Audio Synthesis
May 14, 2026Current methods for creating drum loop audio in digital music production, such as using one-shot samples or resampling, often demand non-trivial efforts of creators. While recent generative models achieve high fidelity and adhere to text, they lack the specific control needed for such a task. Existing symbolic-to-audio research often focuses on single, tonal instruments, leaving the challenge of polyphonic, percussive drum synthesis unaddressed. We address this gap by introducing ``Break-the-Beat!,'' a model capable of rendering a drum MIDI with the timbre of a reference audio. It is built by fine-tuning a pre-trained text-to-audio model with our proposed content encoder and a effective hybrid conditioning mechanism. To enable this, we construct a new dataset of paired target-reference drum audio from existing drum audio datasets. Experiments demonstrate that our model generates high-quality drum audio that follows high-resolution drum MIDI, achieving strong performance across metrics of audio quality, rhythmic alignment, and beat continuity. This offer producers a new, controllable tool for creative production. Demo page: https://ik4sumii.github.io/break-the-beat/
Concept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?
May 26, 2025We present a framework to foster the evaluation of deep learning-based audio watermarking algorithms, establishing a standardized benchmark and allowing systematic comparisons. To simulate real-world usage, we introduce a comprehensive audio attack pipeline, featuring various distortions such as compression, background noise, and reverberation, and propose a diverse test dataset, including speech, environmental sounds, and music recordings. By assessing the performance of four existing watermarking algorithms on our framework, two main insights stand out: (i) neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions; and (ii) training with audio attacks generally improves robustness, although it is insufficient in some cases. Furthermore, we find that specific distortions, such as polarity inversion, time stretching, or reverb, seriously affect certain algorithms. Our contributions strengthen the robustness and perceptual assessment of audio watermarking algorithms across a wide range of applications, while ensuring a fair and consistent evaluation approach. The evaluation framework, including the attack pipeline, is accessible at github.com/SonyResearch/wm_robustness_eval.
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-Guided and Personalized Music Editing
Apr 15, 2025Music editing is an important step in music production, which has broad applications, including game development and film production. Most existing zero-shot text-guided methods rely on pretrained diffusion models by involving forward-backward diffusion processes for editing. However, these methods often struggle to maintain the music content consistency. Additionally, text instructions alone usually fail to accurately describe the desired music. In this paper, we propose two music editing methods that enhance the consistency between the original and edited music by leveraging score distillation. The first method, SteerMusic, is a coarse-grained zero-shot editing approach using delta denoising score. The second method, SteerMusic+, enables fine-grained personalized music editing by manipulating a concept token that represents a user-defined musical style. SteerMusic+ allows for the editing of music into any user-defined musical styles that cannot be achieved by the text instructions alone. Experimental results show that our methods outperform existing approaches in preserving both music content consistency and editing fidelity. User studies further validate that our methods achieve superior music editing quality. Audio examples are available on https://steermusic.pages.dev/.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024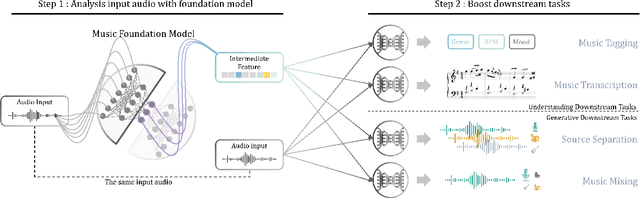


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
DisMix: Disentangling Mixtures of Musical Instruments for Source-level Pitch and Timbre Manipulation
Aug 20, 2024



Existing work on pitch and timbre disentanglement has been mostly focused on single-instrument music audio, excluding the cases where multiple instruments are presented. To fill the gap, we propose DisMix, a generative framework in which the pitch and timbre representations act as modular building blocks for constructing the melody and instrument of a source, and the collection of which forms a set of per-instrument latent representations underlying the observed mixture. By manipulating the representations, our model samples mixtures with novel combinations of pitch and timbre of the constituent instruments. We can jointly learn the disentangled pitch-timbre representations and a latent diffusion transformer that reconstructs the mixture conditioned on the set of source-level representations. We evaluate the model using both a simple dataset of isolated chords and a realistic four-part chorales in the style of J.S. Bach, identify the key components for the success of disentanglement, and demonstrate the application of mixture transformation based on source-level attribute manipulation.
Improving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Jun 22, 2024



Recent years have seen increasing interest in applying deep learning methods to the modeling of guitar amplifiers or effect pedals. Existing methods are mainly based on the supervised approach, requiring temporally-aligned data pairs of unprocessed and rendered audio. However, this approach does not scale well, due to the complicated process involved in creating the data pairs. A very recent work done by Wright et al. has explored the potential of leveraging unpaired data for training, using a generative adversarial network (GAN)-based framework. This paper extends their work by using more advanced discriminators in the GAN, and using more unpaired data for training. Specifically, drawing inspiration from recent advancements in neural vocoders, we employ in our GAN-based model for guitar amplifier modeling two sets of discriminators, one based on multi-scale discriminator (MSD) and the other multi-period discriminator (MPD). Moreover, we experiment with adding unprocessed audio signals that do not have the corresponding rendered audio of a target tone to the training data, to see how much the GAN model benefits from the unpaired data. Our experiments show that the proposed two extensions contribute to the modeling of both low-gain and high-gain guitar amplifiers.
Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
May 29, 2024



Recent advances in text-to-music editing, which employ text queries to modify music (e.g.\ by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.