 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundReactor: Frame-level Online Video-to-Audio Generation
Oct 02, 2025



Prevailing Video-to-Audio (V2A) generation models operate offline, assuming an entire video sequence or chunks of frames are available beforehand. This critically limits their use in interactive applications such as live content creation and emerging generative world models. To address this gap, we introduce the novel task of frame-level online V2A generation, where a model autoregressively generates audio from video without access to future video frames. Furthermore, we propose SoundReactor, which, to the best of our knowledge, is the first simple yet effective framework explicitly tailored for this task. Our design enforces end-to-end causality and targets low per-frame latency with audio-visual synchronization. Our model's backbone is a decoder-only causal transformer over continuous audio latents. For vision conditioning, it leverages grid (patch) features extracted from the smallest variant of the DINOv2 vision encoder, which are aggregated into a single token per frame to maintain end-to-end causality and efficiency. The model is trained through a diffusion pre-training followed by consistency fine-tuning to accelerate the diffusion head decoding. On a benchmark of diverse gameplay videos from AAA titles, our model successfully generates semantically and temporally aligned, high-quality full-band stereo audio, validated by both objective and human evaluations. Furthermore, our model achieves low per-frame waveform-level latency (26.3ms with the head NFE=1, 31.5ms with NFE=4) on 30FPS, 480p videos using a single H100. Demo samples are available at https://koichi-saito-sony.github.io/soundreactor/.
Combining Deterministic Enhanced Conditions with Dual-Streaming Encoding for Diffusion-Based Speech Enhancement
May 20, 2025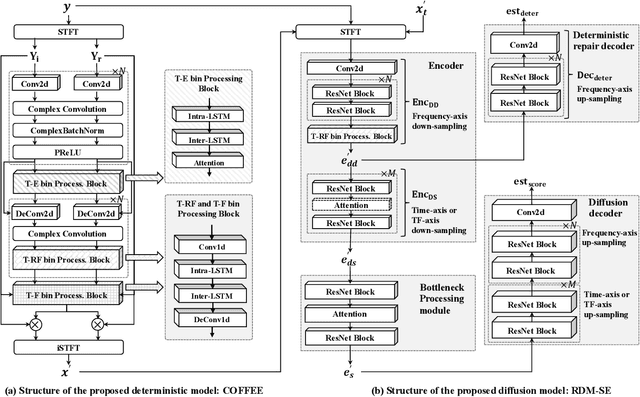
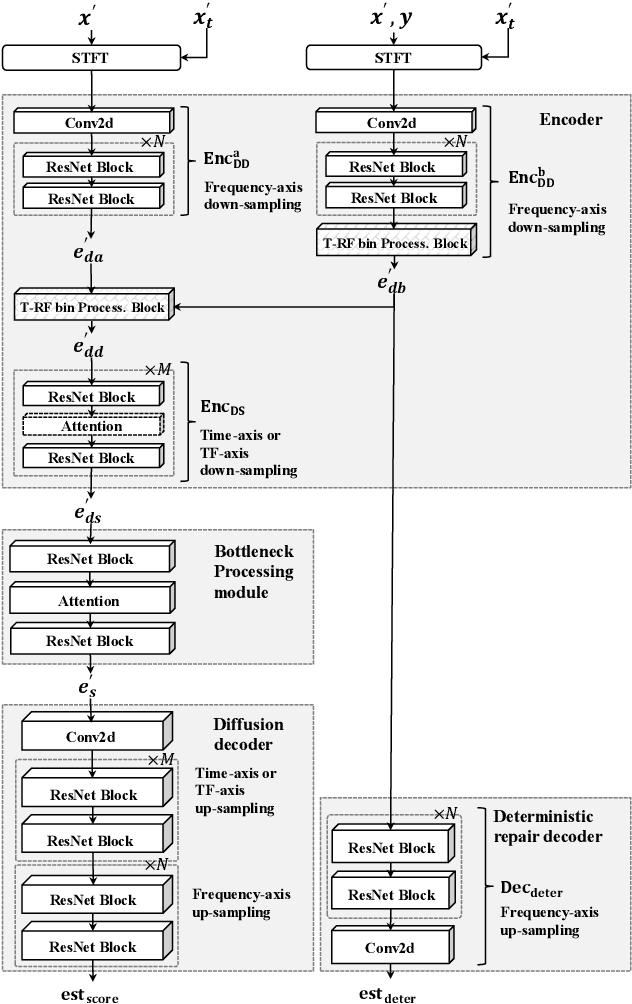
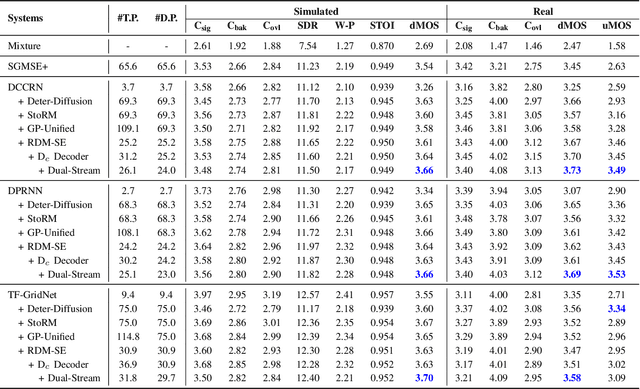
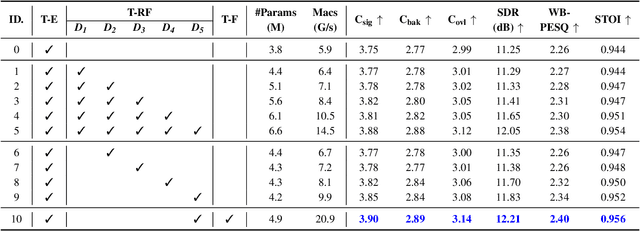
Diffusion-based speech enhancement (SE) models need to incorporate correct prior knowledge as reliable conditions to generate accurate predictions. However, providing reliable conditions using noisy features is challenging. One solution is to use features enhanced by deterministic methods as conditions. However, the information distortion and loss caused by deterministic methods might affect the diffusion process. In this paper, we first investigate the effects of using different deterministic SE models as conditions for diffusion. We validate two conditions depending on whether the noisy feature was used as part of the condition: one using only the deterministic feature (deterministic-only), and the other using both deterministic and noisy features (deterministic-noisy). Preliminary investigation found that using deterministic enhanced conditions improves hearing experiences on real data, while the choice between using deterministic-only or deterministic-noisy conditions depends on the deterministic models. Based on these findings, we propose a dual-streaming encoding Repair-Diffusion Model for SE (DERDM-SE) to more effectively utilize both conditions. Moreover, we found that fine-grained deterministic models have greater potential in objective evaluation metrics, while UNet-based deterministic models provide more stable diffusion performance. Therefore, in the DERDM-SE, we propose a deterministic model that combines coarse- and fine-grained processing. Experimental results on CHiME4 show that the proposed models effectively leverage deterministic models to achieve better SE evaluation scores, along with more stable performance compared to other diffusion-based SE models.
CCStereo: Audio-Visual Contextual and Contrastive Learning for Binaural Audio Generation
Jan 06, 2025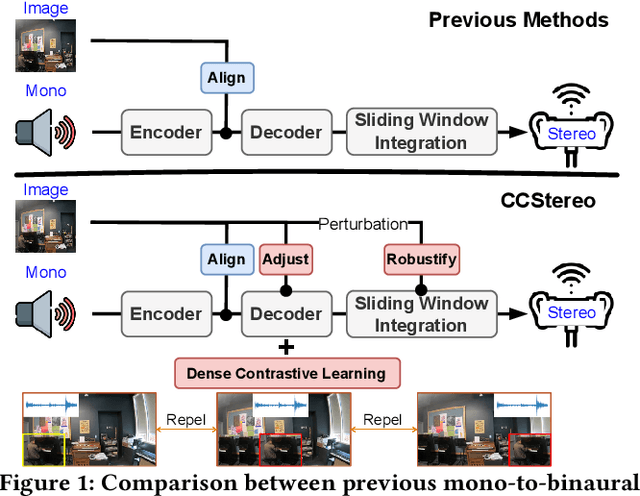
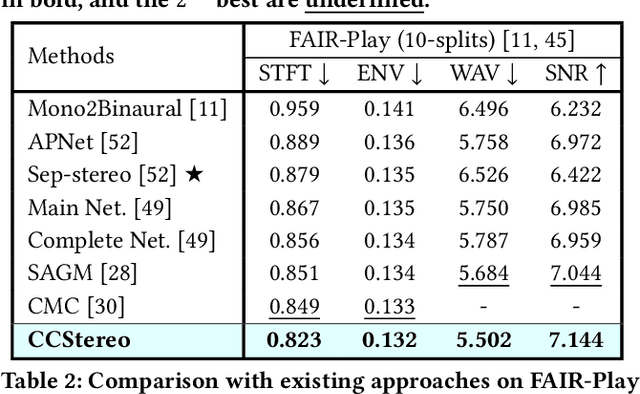
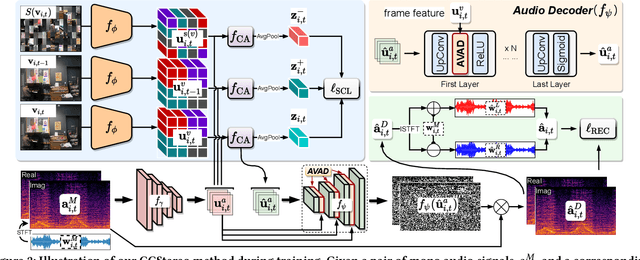
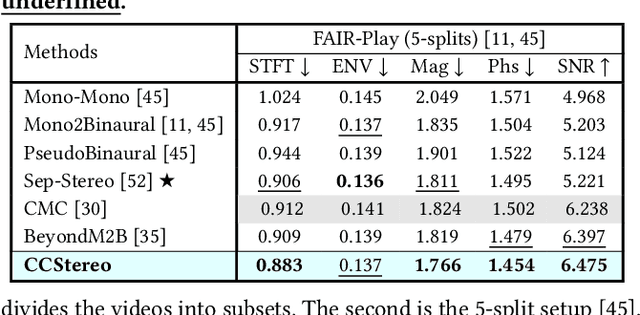
Binaural audio generation (BAG) aims to convert monaural audio to stereo audio using visual prompts, requiring a deep understanding of spatial and semantic information. However, current models risk overfitting to room environments and lose fine-grained spatial details. In this paper, we propose a new audio-visual binaural generation model incorporating an audio-visual conditional normalisation layer that dynamically aligns the mean and variance of the target difference audio features using visual context, along with a new contrastive learning method to enhance spatial sensitivity by mining negative samples from shuffled visual features. We also introduce a cost-efficient way to utilise test-time augmentation in video data to enhance performance. Our approach achieves state-of-the-art generation accuracy on the FAIR-Play and MUSIC-Stereo benchmarks.
SAVGBench: Benchmarking Spatially Aligned Audio-Video Generation
Dec 18, 2024



This work addresses the lack of multimodal generative models capable of producing high-quality videos with spatially aligned audio. While recent advancements in generative models have been successful in video generation, they often overlook the spatial alignment between audio and visuals, which is essential for immersive experiences. To tackle this problem, we establish a new research direction in benchmarking Spatially Aligned Audio-Video Generation (SAVG). We propose three key components for the benchmark: dataset, baseline, and metrics. We introduce a spatially aligned audio-visual dataset, derived from an audio-visual dataset consisting of multichannel audio, video, and spatiotemporal annotations of sound events. We propose a baseline audio-visual diffusion model focused on stereo audio-visual joint learning to accommodate spatial sound. Finally, we present metrics to evaluate video and spatial audio quality, including a new spatial audio-visual alignment metric. Our experimental result demonstrates that gaps exist between the baseline model and ground truth in terms of video and audio quality, and spatial alignment between both modalities.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024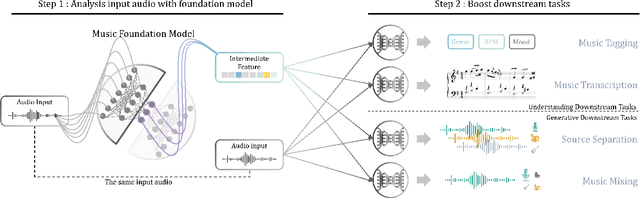


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
HQ-VAE: Hierarchical Discrete Representation Learning with Variational Bayes
Dec 31, 2023



Vector quantization (VQ) is a technique to deterministically learn features with discrete codebook representations. It is commonly performed with a variational autoencoding model, VQ-VAE, which can be further extended to hierarchical structures for making high-fidelity reconstructions. However, such hierarchical extensions of VQ-VAE often suffer from the codebook/layer collapse issue, where the codebook is not efficiently used to express the data, and hence degrades reconstruction accuracy. To mitigate this problem, we propose a novel unified framework to stochastically learn hierarchical discrete representation on the basis of the variational Bayes framework, called hierarchically quantized variational autoencoder (HQ-VAE). HQ-VAE naturally generalizes the hierarchical variants of VQ-VAE, such as VQ-VAE-2 and residual-quantized VAE (RQ-VAE), and provides them with a Bayesian training scheme. Our comprehensive experiments on image datasets show that HQ-VAE enhances codebook usage and improves reconstruction performance. We also validated HQ-VAE in terms of its applicability to a different modality with an audio dataset.
Zero- and Few-shot Sound Event Localization and Detection
Sep 17, 2023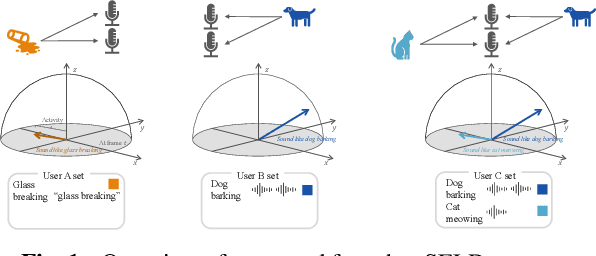



Sound event localization and detection (SELD) systems estimate direction-of-arrival (DOA) and temporal activation for sets of target classes. Neural network (NN)-based SELD systems have performed well in various sets of target classes, but they only output the DOA and temporal activation of preset classes that are trained before inference. To customize target classes after training, we tackle zero- and few-shot SELD tasks, in which we set new classes with a text sample or a few audio samples. While zero-shot sound classification tasks are achievable by embedding from contrastive language-audio pretraining (CLAP), zero-shot SELD tasks require assigning an activity and a DOA to each embedding, especially in overlapping cases. To tackle the assignment problem in overlapping cases, we propose an embed-ACCDOA model, which is trained to output track-wise CLAP embedding and corresponding activity-coupled Cartesian direction-of-arrival (ACCDOA). In our experimental evaluations on zero- and few-shot SELD tasks, the embed-ACCDOA model showed a better location-dependent scores than a straightforward combination of the CLAP audio encoder and a DOA estimation model. Moreover, the proposed combination of the embed-ACCDOA model and CLAP audio encoder with zero- or few-shot samples performed comparably to an official baseline system trained with complete train data in an evaluation dataset.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Diffusion-Based Speech Enhancement with Joint Generative and Predictive Decoders
May 18, 2023



Diffusion-based speech enhancement (SE) has been investigated recently, but its decoding is very time-consuming. One solution is to initialize the decoding process with the enhanced feature estimated by a predictive SE system. However, this two-stage method ignores the complementarity between predictive and diffusion SE. In this paper, we propose a unified system that integrates these two SE modules. The system encodes both generative and predictive information, and then applies both generative and predictive decoders, whose outputs are fused. Specifically, the two SE modules are fused in the first and final diffusion steps: the first step fusion initializes the diffusion process with the predictive SE for improving the convergence, and the final step fusion combines the two complementary SE outputs to improve the SE performance. Experiments on the Voice-Bank dataset show that the diffusion score estimation can benefit from the predictive information and speed up the decoding.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023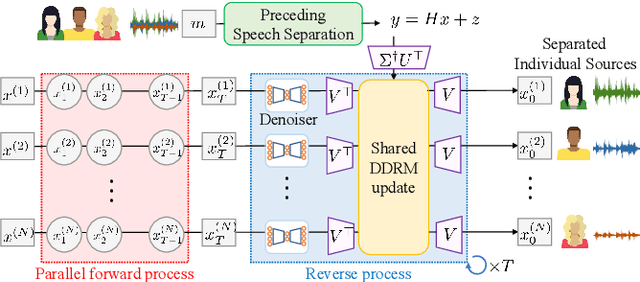



We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.