 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring trust in recommendation systems from brain, behavioural, and physiological data
Oct 31, 2025As people nowadays increasingly rely on artificial intelligence (AI) to curate information and make decisions, assigning the appropriate amount of trust in automated intelligent systems has become ever more important. However, current measurements of trust in automation still largely rely on self-reports that are subjective and disruptive to the user. Here, we take music recommendation as a model to investigate the neural and cognitive processes underlying trust in automation. We observed that system accuracy was directly related to users' trust and modulated the influence of recommendation cues on music preference. Modelling users' reward encoding process with a reinforcement learning model further revealed that system accuracy, expected reward, and prediction error were related to oscillatory neural activity recorded via EEG and changes in pupil diameter. Our results provide a neurally grounded account of calibrating trust in automation and highlight the promises of a multimodal approach towards developing trustable AI systems.
Schrödinger Bridge Consistency Trajectory Models for Speech Enhancement
Jul 16, 2025Speech enhancement (SE) utilizing diffusion models is a promising technology that improves speech quality in noisy speech data. Furthermore, the Schr\"odinger bridge (SB) has recently been used in diffusion-based SE to improve speech quality by resolving a mismatch between the endpoint of the forward process and the starting point of the reverse process. However, the SB still exhibits slow inference owing to the necessity of a large number of function evaluations (NFE) for inference to obtain high-quality results. While Consistency Models (CMs) address this issue by employing consistency training that uses distillation from pretrained models in the field of image generation, it does not improve generation quality when the number of steps increases. As a solution to this problem, Consistency Trajectory Models (CTMs) not only accelerate inference speed but also maintain a favorable trade-off between quality and speed. Furthermore, SoundCTM demonstrates the applicability of CTM techniques to the field of sound generation. In this paper, we present Schr\"odinger bridge Consistency Trajectory Models (SBCTM) by applying the CTM's technique to the Schr\"odinger bridge for SE. Additionally, we introduce a novel auxiliary loss, including a perceptual loss, into the original CTM's training framework. As a result, SBCTM achieves an approximately 16x improvement in the real-time factor (RTF) compared to the conventional Schr\"odinger bridge for SE. Furthermore, the favorable trade-off between quality and speed in SBCTM allows for time-efficient inference by limiting multi-step refinement to cases where 1-step inference is insufficient. Our code, pretrained models, and audio samples are available at https://github.com/sony/sbctm/.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Cinematic Demixing Track
Aug 14, 2023
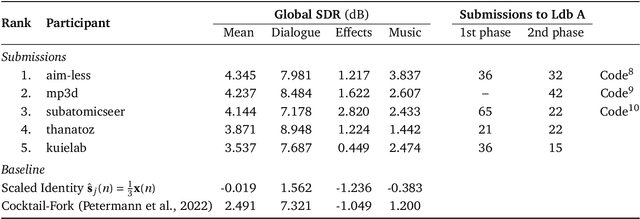


This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8dB in SDR whereas the top performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7dB.
Diffusion-Based Speech Enhancement with Joint Generative and Predictive Decoders
May 18, 2023



Diffusion-based speech enhancement (SE) has been investigated recently, but its decoding is very time-consuming. One solution is to initialize the decoding process with the enhanced feature estimated by a predictive SE system. However, this two-stage method ignores the complementarity between predictive and diffusion SE. In this paper, we propose a unified system that integrates these two SE modules. The system encodes both generative and predictive information, and then applies both generative and predictive decoders, whose outputs are fused. Specifically, the two SE modules are fused in the first and final diffusion steps: the first step fusion initializes the diffusion process with the predictive SE for improving the convergence, and the final step fusion combines the two complementary SE outputs to improve the SE performance. Experiments on the Voice-Bank dataset show that the diffusion score estimation can benefit from the predictive information and speed up the decoding.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023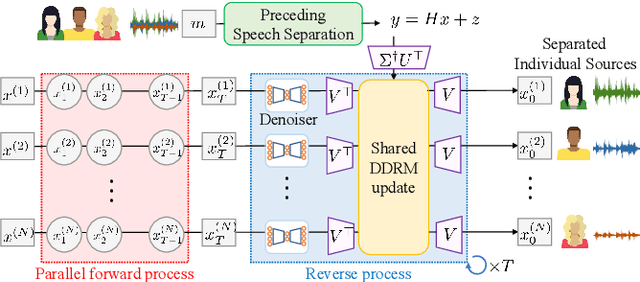



We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
Extending Audio Masked Autoencoders Toward Audio Restoration
May 11, 2023



Audio classification and restoration are among major downstream tasks in audio signal processing. However, restoration derives less of a benefit from pretrained models compared to the overwhelming success of pretrained models in classification tasks. Due to such unbalanced benefits, there has been rising interest in how to improve the performance of pretrained models for restoration tasks such as speech enhancement (SE). Previous works have shown that the features extracted by pretrained audio encoders are effective for SE tasks, but these speech-specific encoder-only models usually require extra decoders to become compatible with SE tasks, and involve complicated pretraining procedures or complex data augmentation. Therefore, in pursuit of a universal audio model, the audio masked autoencoder (MAE) whose backbone is the autoencoder of Vision Transformers (ViT-AE), is extended from audio classification toward restoration tasks in this paper. ViT-AE naturally learns mel-to-mel mapping that is compatible with restoration tasks during pretraining. Among many restoration tasks, SE is chosen due to its well-established evaluation metrics and test data. We propose variations of ViT-AE to improve the SE performance, where the mel-to-mel variations yield high scores for non-intrusive metrics and the STFT-oriented variation is effective at standard intrusive metrics such as PESQ. Different variations can be used in accordance with the scenarios. Comprehensive evaluations and ablation studies show that MAE pretraining is also beneficial to SE tasks and help the ViT-AE to better generalize to out-of-domain distortions. We further found that large-scale noisy data of general audio sources, rather than clean speech, is sufficiently effective for pretraining.
An Attention-based Approach to Hierarchical Multi-label Music Instrument Classification
Feb 16, 2023


Although music is typically multi-label, many works have studied hierarchical music tagging with simplified settings such as single-label data. Moreover, there lacks a framework to describe various joint training methods under the multi-label setting. In order to discuss the above topics, we introduce hierarchical multi-label music instrument classification task. The task provides a realistic setting where multi-instrument real music data is assumed. Various hierarchical methods that jointly train a DNN are summarized and explored in the context of the fusion of deep learning and conventional techniques. For the effective joint training in the multi-label setting, we propose two methods to model the connection between fine- and coarse-level tags, where one uses rule-based grouped max-pooling, the other one uses the attention mechanism obtained in a data-driven manner. Our evaluation reveals that the proposed methods have advantages over the method without joint training. In addition, the decision procedure within the proposed methods can be interpreted by visualizing attention maps or referring to fixed rules.