 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Foundational Audio Encoders Understand Music Structure?
Dec 19, 2025In music information retrieval (MIR) research, the use of pretrained foundational audio encoders (FAEs) has recently become a trend. FAEs pretrained on large amounts of music and audio data have been shown to improve performance on MIR tasks such as music tagging and automatic music transcription. However, their use for music structure analysis (MSA) remains underexplored. Although many open-source FAE models are available, only a small subset has been examined for MSA, and the impact of factors such as learning methods, training data, and model context length on MSA performance remains unclear. In this study, we conduct comprehensive experiments on 11 types of FAEs to investigate how these factors affect MSA performance. Our results demonstrate that FAEs using selfsupervised learning with masked language modeling on music data are particularly effective for MSA. These findings pave the way for future research in MSA.
FoleyBench: A Benchmark For Video-to-Audio Models
Nov 17, 2025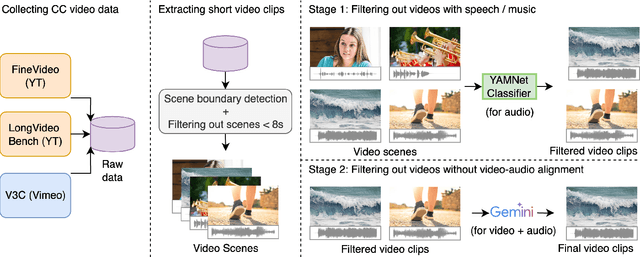
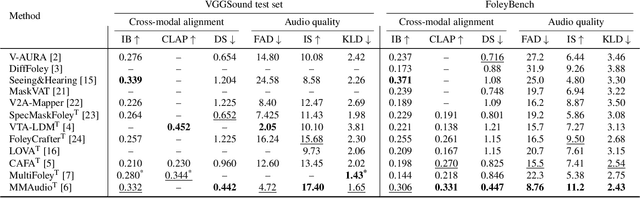
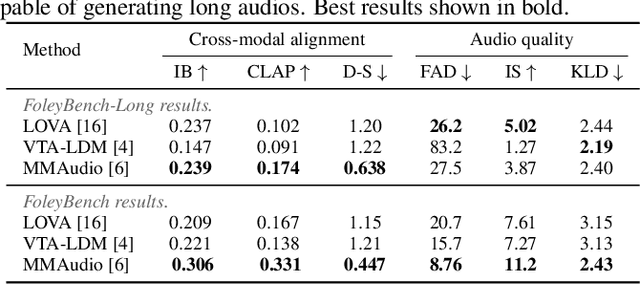

Video-to-audio generation (V2A) is of increasing importance in domains such as film post-production, AR/VR, and sound design, particularly for the creation of Foley sound effects synchronized with on-screen actions. Foley requires generating audio that is both semantically aligned with visible events and temporally aligned with their timing. Yet, there is a mismatch between evaluation and downstream applications due to the absence of a benchmark tailored to Foley-style scenarios. We find that 74% of videos from past evaluation datasets have poor audio-visual correspondence. Moreover, they are dominated by speech and music, domains that lie outside the use case for Foley. To address this gap, we introduce FoleyBench, the first large-scale benchmark explicitly designed for Foley-style V2A evaluation. FoleyBench contains 5,000 (video, ground-truth audio, text caption) triplets, each featuring visible sound sources with audio causally tied to on-screen events. The dataset is built using an automated, scalable pipeline applied to in-the-wild internet videos from YouTube-based and Vimeo-based sources. Compared to past datasets, we show that videos from FoleyBench have stronger coverage of sound categories from a taxonomy specifically designed for Foley sound. Each clip is further labeled with metadata capturing source complexity, UCS/AudioSet category, and video length, enabling fine-grained analysis of model performance and failure modes. We benchmark several state-of-the-art V2A models, evaluating them on audio quality, audio-video alignment, temporal synchronization, and audio-text consistency. Samples are available at: https://gclef-cmu.org/foleybench
SoundReactor: Frame-level Online Video-to-Audio Generation
Oct 02, 2025



Prevailing Video-to-Audio (V2A) generation models operate offline, assuming an entire video sequence or chunks of frames are available beforehand. This critically limits their use in interactive applications such as live content creation and emerging generative world models. To address this gap, we introduce the novel task of frame-level online V2A generation, where a model autoregressively generates audio from video without access to future video frames. Furthermore, we propose SoundReactor, which, to the best of our knowledge, is the first simple yet effective framework explicitly tailored for this task. Our design enforces end-to-end causality and targets low per-frame latency with audio-visual synchronization. Our model's backbone is a decoder-only causal transformer over continuous audio latents. For vision conditioning, it leverages grid (patch) features extracted from the smallest variant of the DINOv2 vision encoder, which are aggregated into a single token per frame to maintain end-to-end causality and efficiency. The model is trained through a diffusion pre-training followed by consistency fine-tuning to accelerate the diffusion head decoding. On a benchmark of diverse gameplay videos from AAA titles, our model successfully generates semantically and temporally aligned, high-quality full-band stereo audio, validated by both objective and human evaluations. Furthermore, our model achieves low per-frame waveform-level latency (26.3ms with the head NFE=1, 31.5ms with NFE=4) on 30FPS, 480p videos using a single H100. Demo samples are available at https://koichi-saito-sony.github.io/soundreactor/.
TITAN-Guide: Taming Inference-Time AligNment for Guided Text-to-Video Diffusion Models
Aug 01, 2025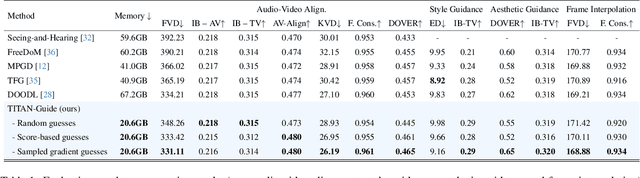



In the recent development of conditional diffusion models still require heavy supervised fine-tuning for performing control on a category of tasks. Training-free conditioning via guidance with off-the-shelf models is a favorable alternative to avoid further fine-tuning on the base model. However, the existing training-free guidance frameworks either have heavy memory requirements or offer sub-optimal control due to rough estimation. These shortcomings limit the applicability to control diffusion models that require intense computation, such as Text-to-Video (T2V) diffusion models. In this work, we propose Taming Inference Time Alignment for Guided Text-to-Video Diffusion Model, so-called TITAN-Guide, which overcomes memory space issues, and provides more optimal control in the guidance process compared to the counterparts. In particular, we develop an efficient method for optimizing diffusion latents without backpropagation from a discriminative guiding model. In particular, we study forward gradient descents for guided diffusion tasks with various options on directional directives. In our experiments, we demonstrate the effectiveness of our approach in efficiently managing memory during latent optimization, while previous methods fall short. Our proposed approach not only minimizes memory requirements but also significantly enhances T2V performance across a range of diffusion guidance benchmarks. Code, models, and demo are available at https://titanguide.github.io.
SpecMaskFoley: Steering Pretrained Spectral Masked Generative Transformer Toward Synchronized Video-to-audio Synthesis via ControlNet
May 22, 2025Foley synthesis aims to synthesize high-quality audio that is both semantically and temporally aligned with video frames. Given its broad application in creative industries, the task has gained increasing attention in the research community. To avoid the non-trivial task of training audio generative models from scratch, adapting pretrained audio generative models for video-synchronized foley synthesis presents an attractive direction. ControlNet, a method for adding fine-grained controls to pretrained generative models, has been applied to foley synthesis, but its use has been limited to handcrafted human-readable temporal conditions. In contrast, from-scratch models achieved success by leveraging high-dimensional deep features extracted using pretrained video encoders. We have observed a performance gap between ControlNet-based and from-scratch foley models. To narrow this gap, we propose SpecMaskFoley, a method that steers the pretrained SpecMaskGIT model toward video-synchronized foley synthesis via ControlNet. To unlock the potential of a single ControlNet branch, we resolve the discrepancy between the temporal video features and the time-frequency nature of the pretrained SpecMaskGIT via a frequency-aware temporal feature aligner, eliminating the need for complicated conditioning mechanisms widely used in prior arts. Evaluations on a common foley synthesis benchmark demonstrate that SpecMaskFoley could even outperform strong from-scratch baselines, substantially advancing the development of ControlNet-based foley synthesis models. Demo page: https://zzaudio.github.io/SpecMaskFoley_Demo/
Cross-Modal Learning for Music-to-Music-Video Description Generation
Mar 14, 2025Music-to-music-video generation is a challenging task due to the intrinsic differences between the music and video modalities. The advent of powerful text-to-video diffusion models has opened a promising pathway for music-video (MV) generation by first addressing the music-to-MV description task and subsequently leveraging these models for video generation. In this study, we focus on the MV description generation task and propose a comprehensive pipeline encompassing training data construction and multimodal model fine-tuning. We fine-tune existing pre-trained multimodal models on our newly constructed music-to-MV description dataset based on the Music4All dataset, which integrates both musical and visual information. Our experimental results demonstrate that music representations can be effectively mapped to textual domains, enabling the generation of meaningful MV description directly from music inputs. We also identify key components in the dataset construction pipeline that critically impact the quality of MV description and highlight specific musical attributes that warrant greater focus for improved MV description generation.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024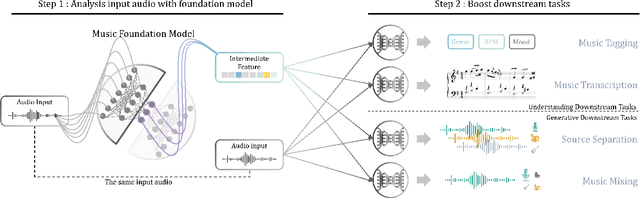

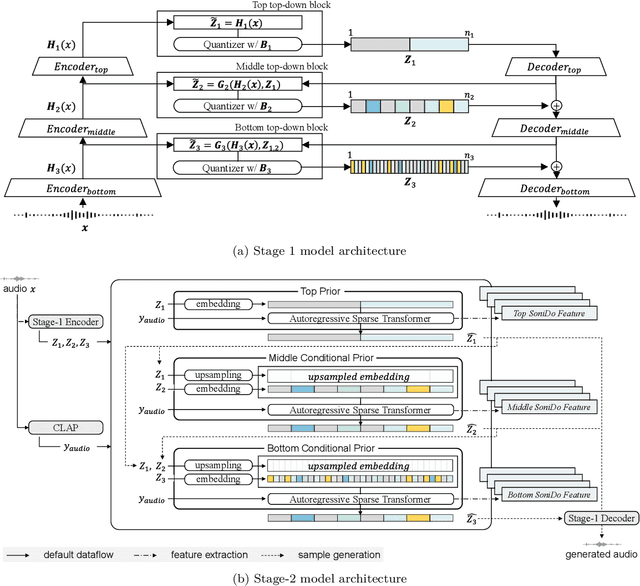

We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
OpenMU: Your Swiss Army Knife for Music Understanding
Oct 21, 2024



We present OpenMU-Bench, a large-scale benchmark suite for addressing the data scarcity issue in training multimodal language models to understand music. To construct OpenMU-Bench, we leveraged existing datasets and bootstrapped new annotations. OpenMU-Bench also broadens the scope of music understanding by including lyrics understanding and music tool usage. Using OpenMU-Bench, we trained our music understanding model, OpenMU, with extensive ablations, demonstrating that OpenMU outperforms baseline models such as MU-Llama. Both OpenMU and OpenMU-Bench are open-sourced to facilitate future research in music understanding and to enhance creative music production efficiency.
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.