 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTED: Turn Emphasis with Dialogue Feature Attention for Emotion Recognition in Conversation
Jan 02, 2025Emotion recognition in conversation (ERC) has been attracting attention by methods for modeling multi-turn contexts. The multi-turn input to a pretraining model implicitly assumes that the current turn and other turns are distinguished during the training process by inserting special tokens into the input sequence. This paper proposes a priority-based attention method to distinguish each turn explicitly by adding dialogue features into the attention mechanism, called Turn Emphasis with Dialogue (TED). It has a priority for each turn according to turn position and speaker information as dialogue features. It takes multi-head self-attention between turn-based vectors for multi-turn input and adjusts attention scores with the dialogue features. We evaluate TED on four typical benchmarks. The experimental results demonstrate that TED has high overall performance in all datasets and achieves state-of-the-art performance on IEMOCAP with numerous turns.
On the Language Encoder of Contrastive Cross-modal Models
Oct 20, 2023



Contrastive cross-modal models such as CLIP and CLAP aid various vision-language (VL) and audio-language (AL) tasks. However, there has been limited investigation of and improvement in their language encoder, which is the central component of encoding natural language descriptions of image/audio into vector representations. We extensively evaluate how unsupervised and supervised sentence embedding training affect language encoder quality and cross-modal task performance. In VL pretraining, we found that sentence embedding training language encoder quality and aids in cross-modal tasks, improving contrastive VL models such as CyCLIP. In contrast, AL pretraining benefits less from sentence embedding training, which may result from the limited amount of pretraining data. We analyze the representation spaces to understand the strengths of sentence embedding training, and find that it improves text-space uniformity, at the cost of decreased cross-modal alignment.
Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association
Oct 02, 2023



Reporting bias arises when people assume that some knowledge is universally understood and hence, do not necessitate explicit elaboration. In this paper, we focus on the wide existence of reporting bias in visual-language datasets, embodied as the object-attribute association, which can subsequentially degrade models trained on them. To mitigate this bias, we propose a bimodal augmentation (BiAug) approach through object-attribute decoupling to flexibly synthesize visual-language examples with a rich array of object-attribute pairing and construct cross-modal hard negatives. We employ large language models (LLMs) in conjunction with a grounding object detector to extract target objects. Subsequently, the LLM generates a detailed attribute description for each object and produces a corresponding hard negative counterpart. An inpainting model is then used to create images based on these detailed object descriptions. By doing so, the synthesized examples explicitly complement omitted objects and attributes to learn, and the hard negative pairs steer the model to distinguish object attributes. Our experiments demonstrated that BiAug is superior in object-attribute understanding. In addition, BiAug also improves the performance on zero-shot retrieval tasks on general benchmarks like MSCOCO and Flickr30K. BiAug refines the way of collecting text-image datasets. Mitigating the reporting bias helps models achieve a deeper understanding of visual-language phenomena, expanding beyond mere frequent patterns to encompass the richness and diversity of real-world scenarios.
Hybrid Data-Model Parallel Training for Sequence-to-Sequence Recurrent Neural Network Machine Translation
Sep 09, 2019
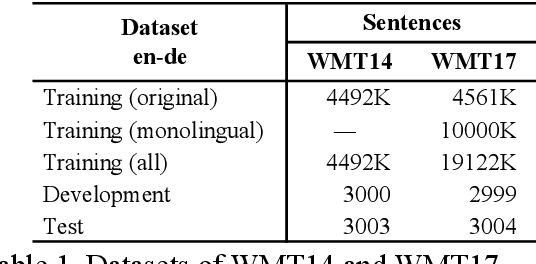

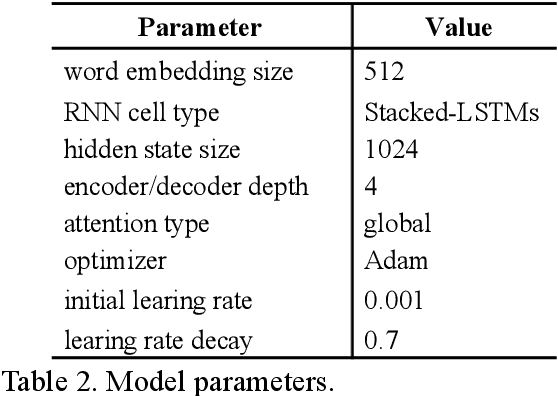
Reduction of training time is an important issue in many tasks like patent translation involving neural networks. Data parallelism and model parallelism are two common approaches for reducing training time using multiple graphics processing units (GPUs) on one machine. In this paper, we propose a hybrid data-model parallel approach for sequence-to-sequence (Seq2Seq) recurrent neural network (RNN) machine translation. We apply a model parallel approach to the RNN encoder-decoder part of the Seq2Seq model and a data parallel approach to the attention-softmax part of the model. We achieved a speed-up of 4.13 to 4.20 times when using 4 GPUs compared with the training speed when using 1 GPU without affecting machine translation accuracy as measured in terms of BLEU scores.