 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCStereo: Audio-Visual Contextual and Contrastive Learning for Binaural Audio Generation
Jan 06, 2025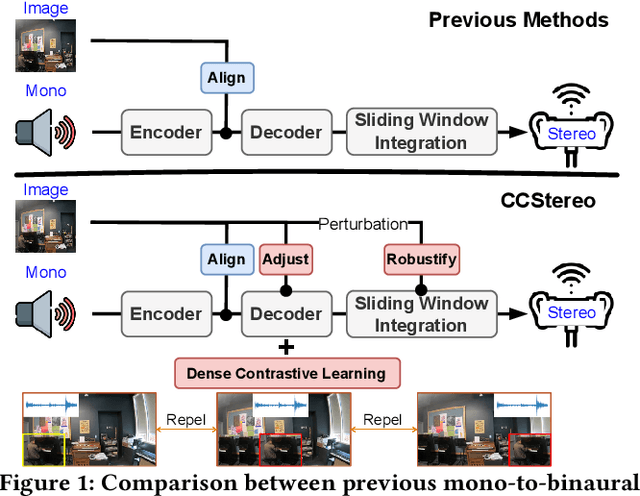
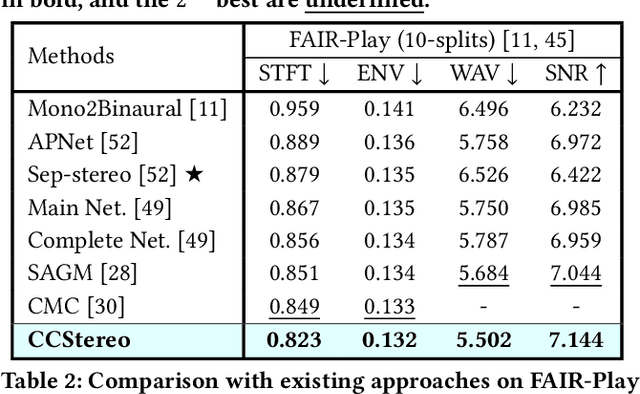
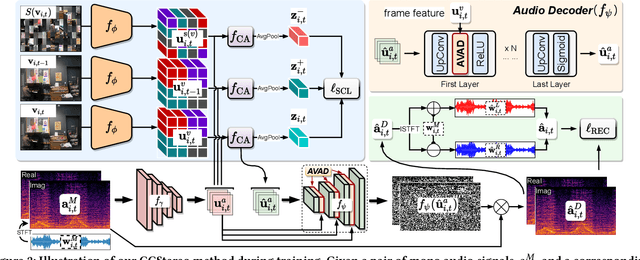
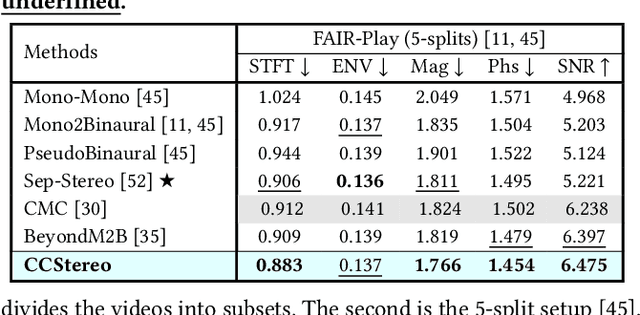
Binaural audio generation (BAG) aims to convert monaural audio to stereo audio using visual prompts, requiring a deep understanding of spatial and semantic information. However, current models risk overfitting to room environments and lose fine-grained spatial details. In this paper, we propose a new audio-visual binaural generation model incorporating an audio-visual conditional normalisation layer that dynamically aligns the mean and variance of the target difference audio features using visual context, along with a new contrastive learning method to enhance spatial sensitivity by mining negative samples from shuffled visual features. We also introduce a cost-efficient way to utilise test-time augmentation in video data to enhance performance. Our approach achieves state-of-the-art generation accuracy on the FAIR-Play and MUSIC-Stereo benchmarks.
Music Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024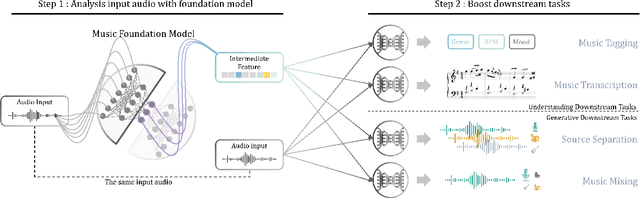


We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
SpecMaskGIT: Masked Generative Modeling of Audio Spectrograms for Efficient Audio Synthesis and Beyond
Jun 26, 2024



Recent advances in generative models that iteratively synthesize audio clips sparked great success to text-to-audio synthesis (TTA), but with the cost of slow synthesis speed and heavy computation. Although there have been attempts to accelerate the iterative procedure, high-quality TTA systems remain inefficient due to hundreds of iterations required in the inference phase and large amount of model parameters. To address the challenges, we propose SpecMaskGIT, a light-weighted, efficient yet effective TTA model based on the masked generative modeling of spectrograms. First, SpecMaskGIT synthesizes a realistic 10s audio clip by less than 16 iterations, an order-of-magnitude less than previous iterative TTA methods. As a discrete model, SpecMaskGIT outperforms larger VQ-Diffusion and auto-regressive models in the TTA benchmark, while being real-time with only 4 CPU cores or even 30x faster with a GPU. Next, built upon a latent space of Mel-spectrogram, SpecMaskGIT has a wider range of applications (e.g., the zero-shot bandwidth extension) than similar methods built on the latent wave domain. Moreover, we interpret SpecMaskGIT as a generative extension to previous discriminative audio masked Transformers, and shed light on its audio representation learning potential. We hope our work inspires the exploration of masked audio modeling toward further diverse scenarios.
Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
May 29, 2024



Recent advances in text-to-music editing, which employ text queries to modify music (e.g.\ by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Feb 09, 2024



Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to \textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.
HQ-VAE: Hierarchical Discrete Representation Learning with Variational Bayes
Dec 31, 2023



Vector quantization (VQ) is a technique to deterministically learn features with discrete codebook representations. It is commonly performed with a variational autoencoding model, VQ-VAE, which can be further extended to hierarchical structures for making high-fidelity reconstructions. However, such hierarchical extensions of VQ-VAE often suffer from the codebook/layer collapse issue, where the codebook is not efficiently used to express the data, and hence degrades reconstruction accuracy. To mitigate this problem, we propose a novel unified framework to stochastically learn hierarchical discrete representation on the basis of the variational Bayes framework, called hierarchically quantized variational autoencoder (HQ-VAE). HQ-VAE naturally generalizes the hierarchical variants of VQ-VAE, such as VQ-VAE-2 and residual-quantized VAE (RQ-VAE), and provides them with a Bayesian training scheme. Our comprehensive experiments on image datasets show that HQ-VAE enhances codebook usage and improves reconstruction performance. We also validated HQ-VAE in terms of its applicability to a different modality with an audio dataset.
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
Jul 10, 2023Taking long-term spectral and temporal dependencies into account is essential for automatic piano transcription. This is especially helpful when determining the precise onset and offset for each note in the polyphonic piano content. In this case, we may rely on the capability of self-attention mechanism in Transformers to capture these long-term dependencies in the frequency and time axes. In this work, we propose hFT-Transformer, which is an automatic music transcription method that uses a two-level hierarchical frequency-time Transformer architecture. The first hierarchy includes a convolutional block in the time axis, a Transformer encoder in the frequency axis, and a Transformer decoder that converts the dimension in the frequency axis. The output is then fed into the second hierarchy which consists of another Transformer encoder in the time axis. We evaluated our method with the widely used MAPS and MAESTRO v3.0.0 datasets, and it demonstrated state-of-the-art performance on all the F1-scores of the metrics among Frame, Note, Note with Offset, and Note with Offset and Velocity estimations.