 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Live Music Song Identification Using Multi-level Deep Sequence Similarity Learning
Jan 14, 2025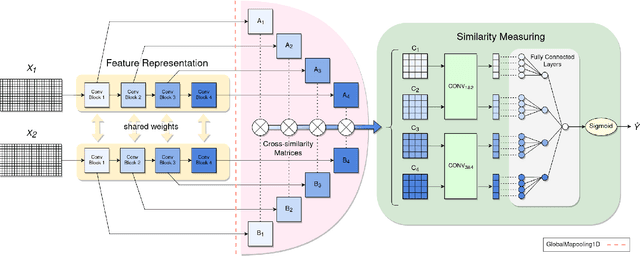
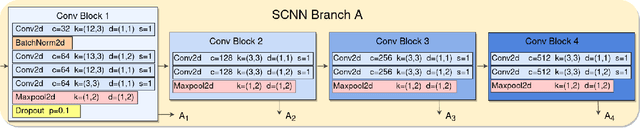
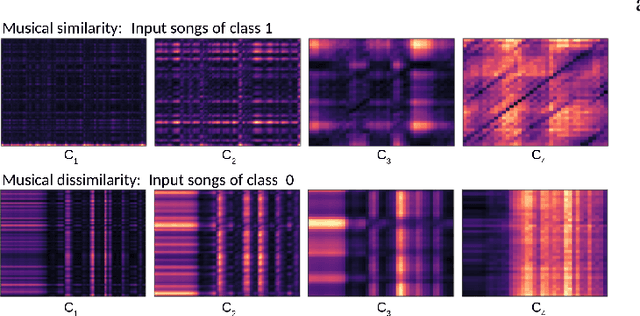
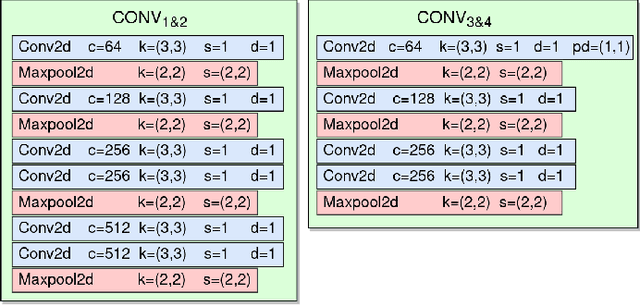
This paper studies the novel problem of automatic live music song identification, where the goal is, given a live recording of a song, to retrieve the corresponding studio version of the song from a music database. We propose a system based on similarity learning and a Siamese convolutional neural network-based model. The model uses cross-similarity matrices of multi-level deep sequences to measure musical similarity between different audio tracks. A manually collected custom live music dataset is used to test the performance of the system with live music. The results of the experiments show that the system is able to identify 87.4% of the given live music queries.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Mobile Microphone Array Speech Detection and Localization in Diverse Everyday Environments
Jun 28, 2021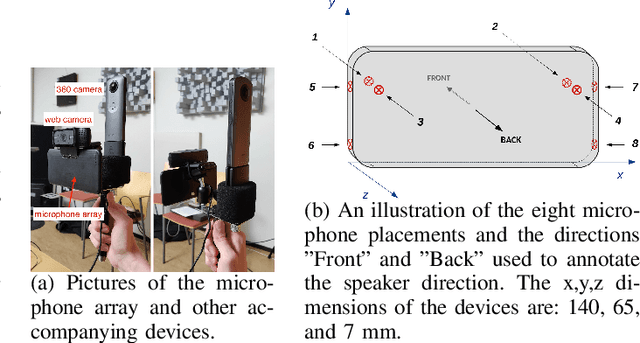
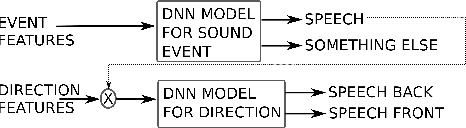
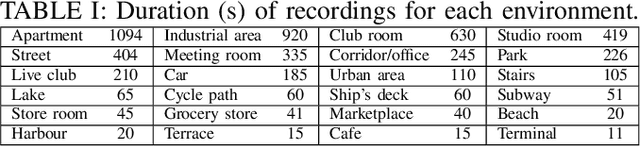
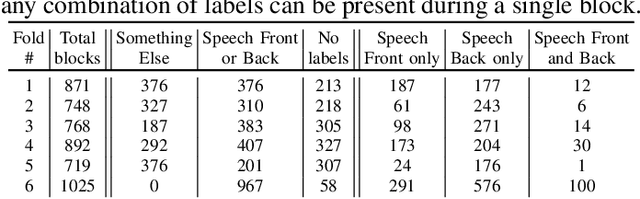
Joint sound event localization and detection (SELD) is an integral part of developing context awareness into communication interfaces of mobile robots, smartphones, and home assistants. For example, an automatic audio focus for video capture on a mobile phone requires robust detection of relevant acoustic events around the device and their direction. Existing SELD approaches have been evaluated using material produced in controlled indoor environments, or the audio is simulated by mixing isolated sounds to different spatial locations. This paper studies SELD of speech in diverse everyday environments, where the audio corresponds to typical usage scenarios of handheld mobile devices. In order to allow weighting the relative importance of localization vs. detection, we will propose a two-stage hierarchical system, where the first stage is to detect the target events, and the second stage is to localize them. The proposed method utilizes convolutional recurrent neural network (CRNN) and is evaluated on a database of manually annotated microphone array recordings from various acoustic conditions. The array is embedded in a contemporary mobile phone form factor. The obtained results show good speech detection and localization accuracy of the proposed method in contrast to a non-hierarchical flat classification model.