 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Improving Speech Prosody of Audiobook Text-to-Speech Synthesis with Acoustic and Textual Contexts
Nov 04, 2022



We present a multi-speaker Japanese audiobook text-to-speech (TTS) system that leverages multimodal context information of preceding acoustic context and bilateral textual context to improve the prosody of synthetic speech. Previous work either uses unilateral or single-modality context, which does not fully represent the context information. The proposed method uses an acoustic context encoder and a textual context encoder to aggregate context information and feeds it to the TTS model, which enables the model to predict context-dependent prosody. We conducted comprehensive objective and subjective evaluations on a multi-speaker Japanese audiobook dataset. Experimental results demonstrate that the proposed method significantly outperforms two previous works. Additionally, we present insights about the different choices of context - modalities, lateral information and length - for audiobook TTS that have never been discussed in the literature before.
Context-based out-of-vocabulary word recovery for ASR systems in Indian languages
Jun 09, 2022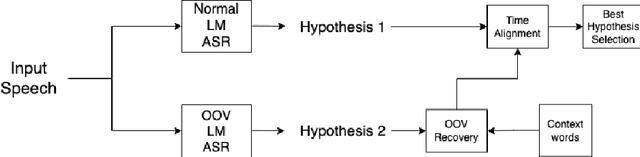
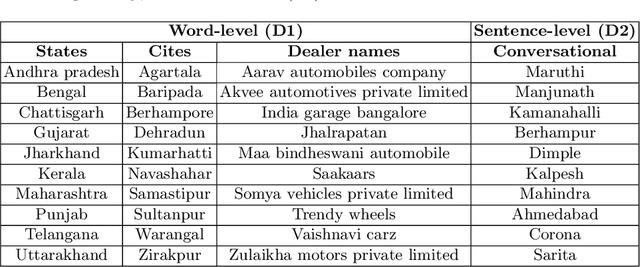
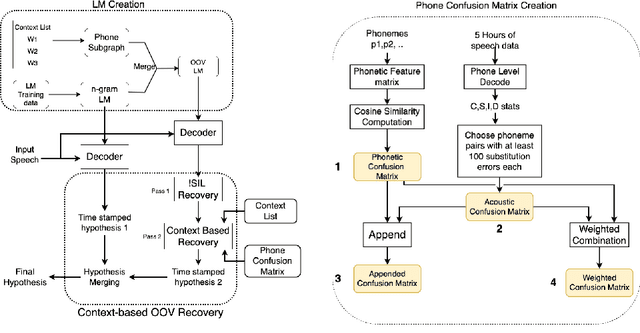
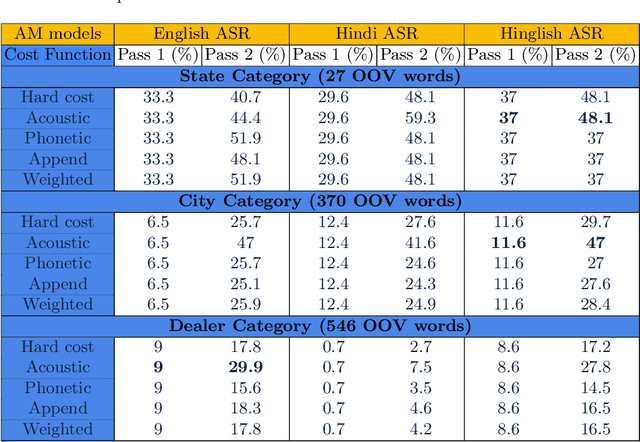
Detecting and recovering out-of-vocabulary (OOV) words is always challenging for Automatic Speech Recognition (ASR) systems. Many existing methods focus on modeling OOV words by modifying acoustic and language models and integrating context words cleverly into models. To train such complex models, we need a large amount of data with context words, additional training time, and increased model size. However, after getting the ASR transcription to recover context-based OOV words, the post-processing method has not been explored much. In this work, we propose a post-processing technique to improve the performance of context-based OOV recovery. We created an acoustically boosted language model with a sub-graph made at phone level with an OOV words list. We proposed two methods to determine a suitable cost function to retrieve the OOV words based on the context. The cost function is defined based on phonetic and acoustic knowledge for matching and recovering the correct context words in the decode. The effectiveness of the proposed cost function is evaluated at both word-level and sentence-level. The evaluation results show that this approach can recover an average of 50% context-based OOV words across multiple categories.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022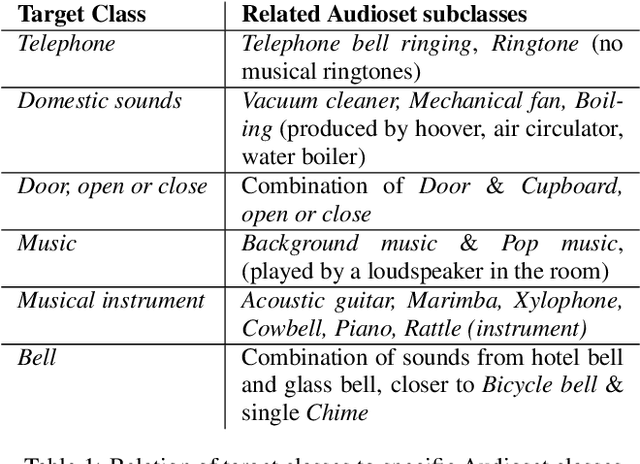
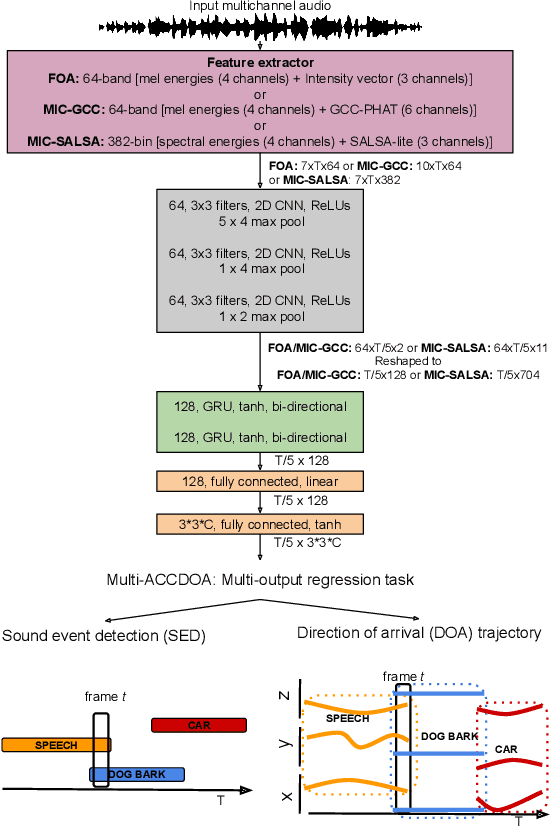
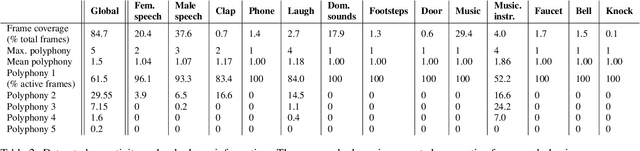

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
Differentiable Tracking-Based Training of Deep Learning Sound Source Localizers
Oct 29, 2021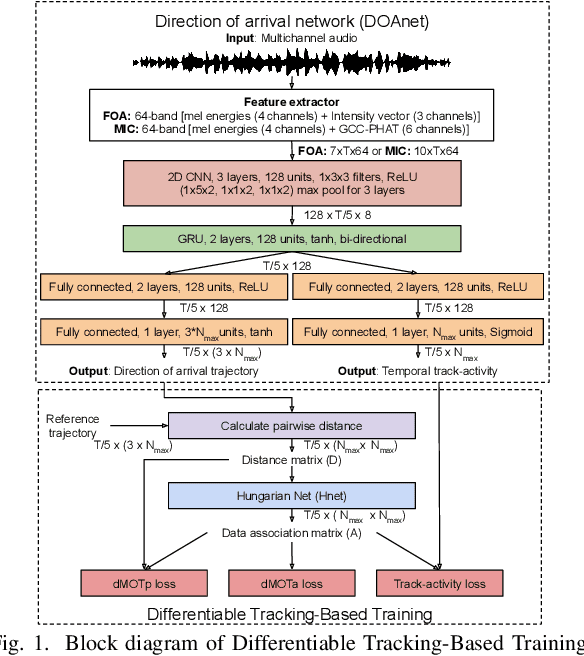
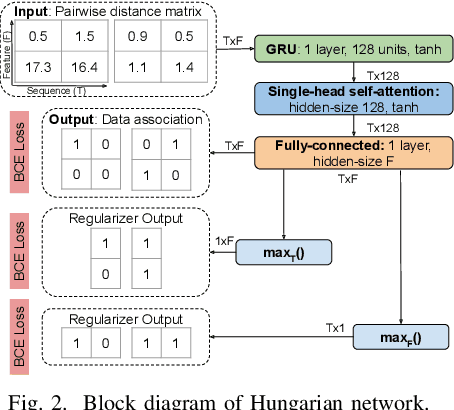
Data-based and learning-based sound source localization (SSL) has shown promising results in challenging conditions, and is commonly set as a classification or a regression problem. Regression-based approaches have certain advantages over classification-based, such as continuous direction-of-arrival estimation of static and moving sources. However, multi-source scenarios require multiple regressors without a clear training strategy up-to-date, that does not rely on auxiliary information such as simultaneous sound classification. We investigate end-to-end training of such methods with a technique recently proposed for video object detectors, adapted to the SSL setting. A differentiable network is constructed that can be plugged to the output of the localizer to solve the optimal assignment between predictions and references, optimizing directly the popular CLEAR-MOT tracking metrics. Results indicate large improvements over directly optimizing mean squared errors, in terms of localization error, detection metrics, and tracking capabilities.
A Dataset of Dynamic Reverberant Sound Scenes with Directional Interferers for Sound Event Localization and Detection
Jul 04, 2021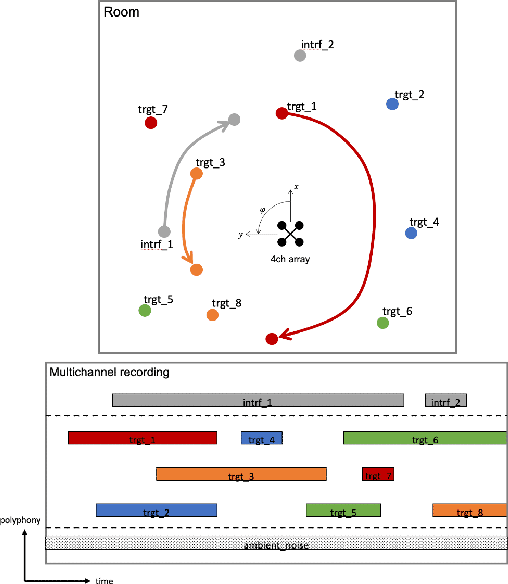

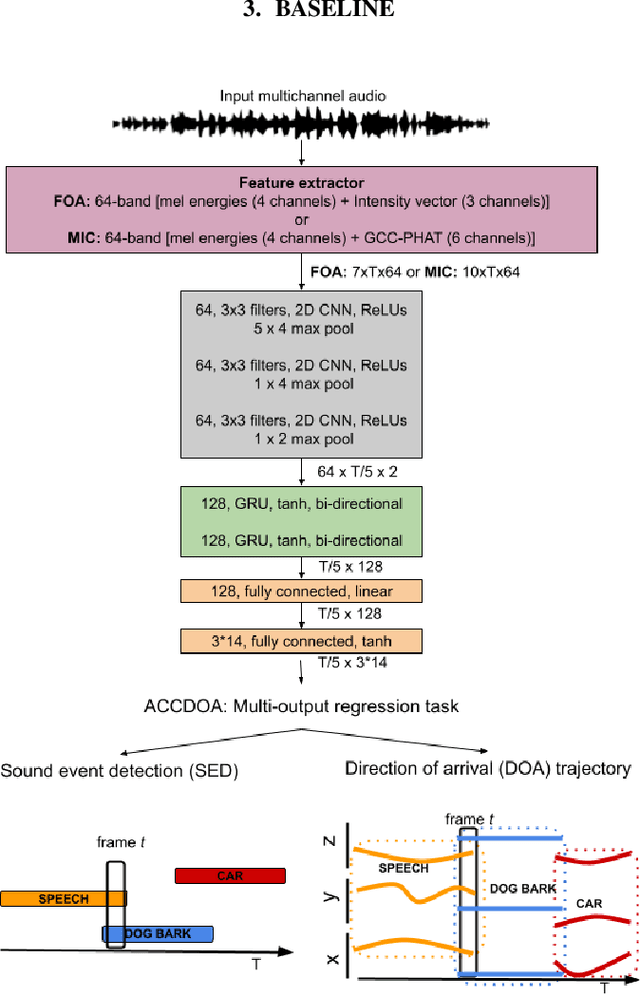
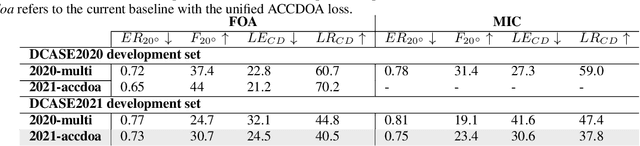
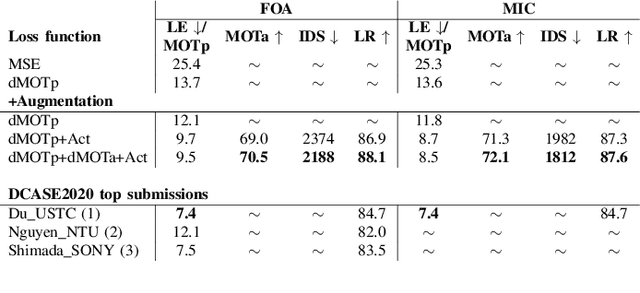
This report presents the dataset and baseline of Task 3 of the DCASE2021 Challenge on Sound Event Localization and Detection (SELD). The dataset is based on emulation of real recordings of static or moving sound events under real conditions of reverberation and ambient noise, using spatial room impulse responses captured in a variety of rooms and delivered in two spatial formats. The acoustical synthesis remains the same as in the previous iteration of the challenge, however the new dataset brings more challenging conditions of polyphony and overlapping instances of the same class. The most important difference of the new dataset is the introduction of directional interferers, meaning sound events that are localized in space but do not belong to the target classes to be detected and are not annotated. Since such interfering events are expected in every real-world scenario of SELD, the new dataset aims to promote systems that deal with this condition effectively. A modified SELDnet baseline employing the recent ACCDOA representation of SELD problems accompanies the dataset and it is shown to outperform the previous one. The new dataset is shown to be significantly more challenging for both baselines according to all considered metrics. To investigate the individual and combined effects of ambient noise, interferers, and reverberation, we study the performance of the baseline on different versions of the dataset excluding or including combinations of these factors. The results indicate that by far the most detrimental effects are caused by directional interferers.
Non-native English lexicon creation for bilingual speech synthesis
Jun 21, 2021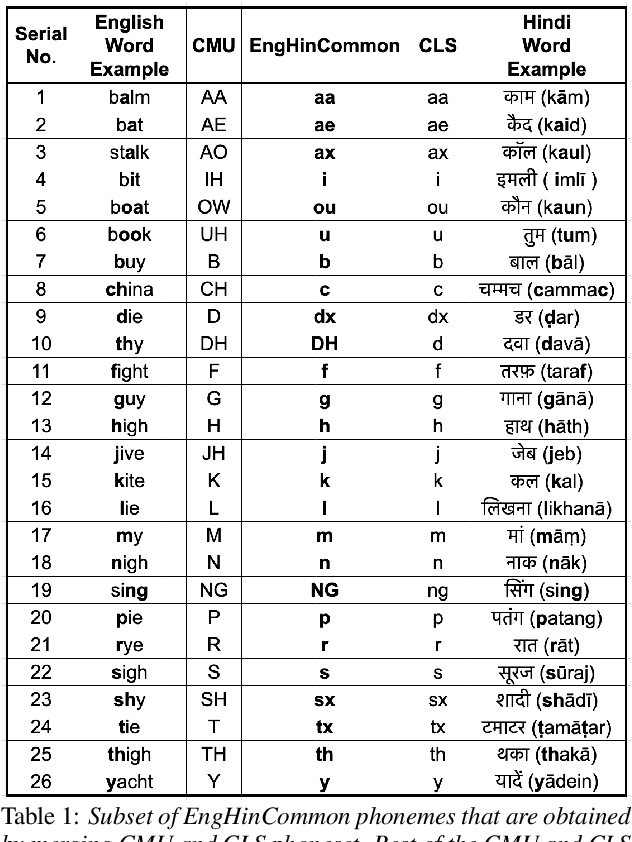
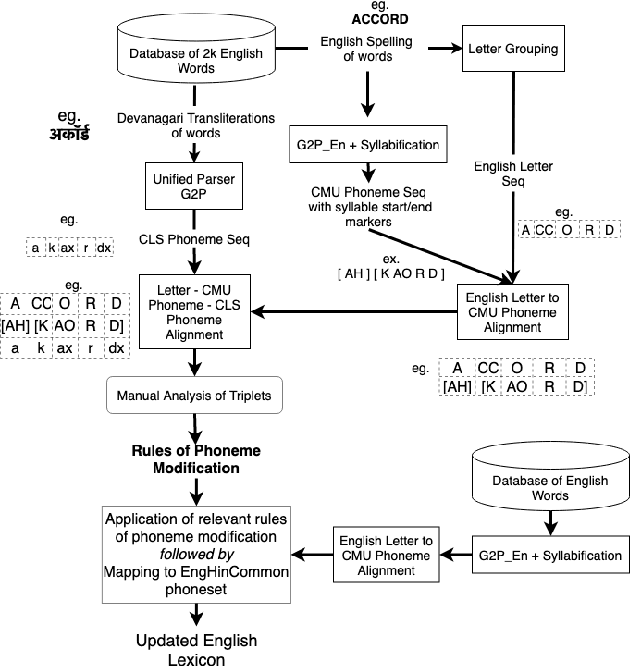
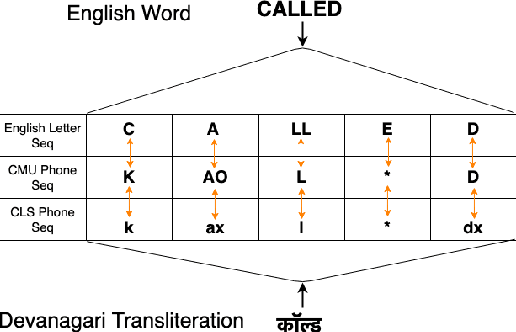
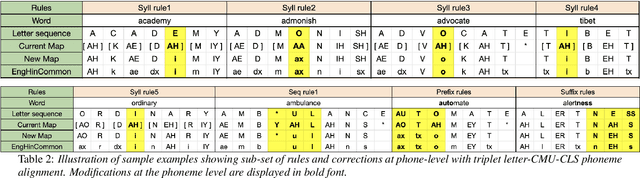
Bilingual English speakers speak English as one of their languages. Their English is of a non-native kind, and their conversations are of a code-mixed fashion. The intelligibility of a bilingual text-to-speech (TTS) system for such non-native English speakers depends on a lexicon that captures the phoneme sequence used by non-native speakers. However, due to the lack of non-native English lexicon, existing bilingual TTS systems employ native English lexicons that are widely available, in addition to their native language lexicon. Due to the inconsistency between the non-native English pronunciation in the audio and native English lexicon in the text, the intelligibility of synthesized speech in such TTS systems is significantly reduced. This paper is motivated by the knowledge that the native language of the speaker highly influences non-native English pronunciation. We propose a generic approach to obtain rules based on letter to phoneme alignment to map native English lexicon to their non-native version. The effectiveness of such mapping is studied by comparing bilingual (Indian English and Hindi) TTS systems trained with and without the proposed rules. The subjective evaluation shows that the bilingual TTS system trained with the proposed non-native English lexicon rules obtains a 6% absolute improvement in preference.
Localization, Detection and Tracking of Multiple Moving Sound Sources with a Convolutional Recurrent Neural Network
Apr 29, 2019
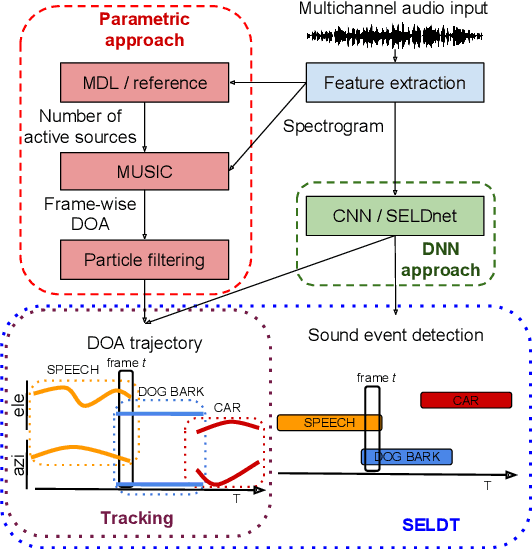
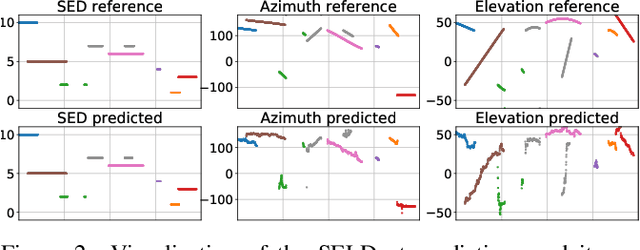
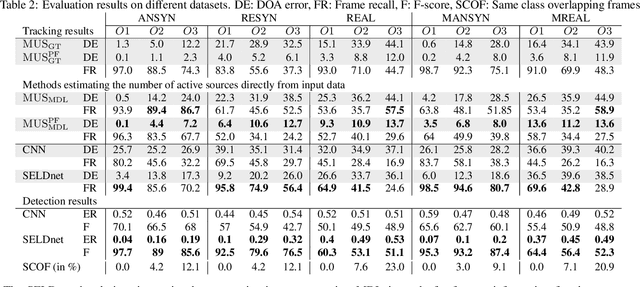
This paper investigates the joint localization, detection, and tracking of sound events using a convolutional recurrent neural network (CRNN). We use a CRNN previously proposed for the localization and detection of stationary sources, and show that the recurrent layers enable the spatial tracking of moving sources when trained with dynamic scenes. The tracking performance of the CRNN is compared with a stand-alone tracking method that combines a multi-source (DOA) estimator and a particle filter. Their respective performance is evaluated in various acoustic conditions such as anechoic and reverberant scenarios, stationary and moving sources at several angular velocities, and with a varying number of overlapping sources. The results show that the CRNN manages to track multiple sources more consistently than the parametric method across acoustic scenarios, but at the cost of higher localization error.
Direction of arrival estimation for multiple sound sources using convolutional recurrent neural network
Aug 05, 2018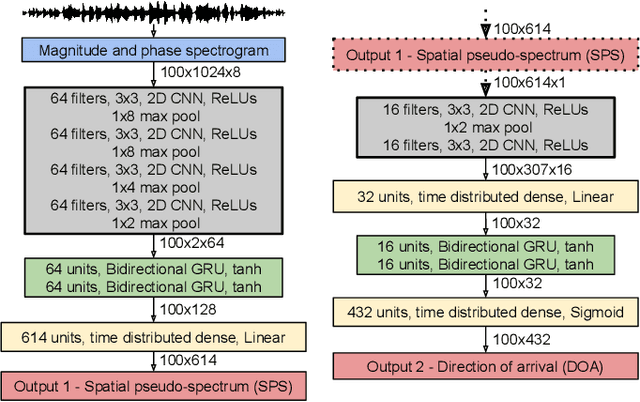
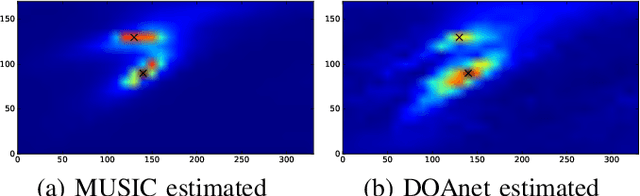
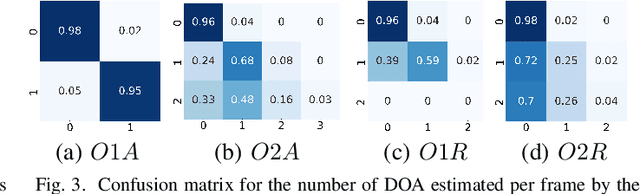
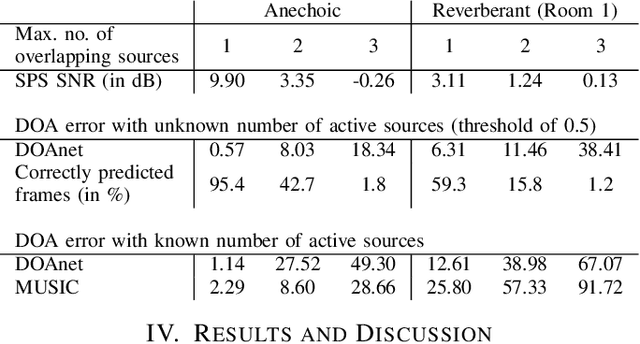
This paper proposes a deep neural network for estimating the directions of arrival (DOA) of multiple sound sources. The proposed stacked convolutional and recurrent neural network (DOAnet) generates a spatial pseudo-spectrum (SPS) along with the DOA estimates in both azimuth and elevation. We avoid any explicit feature extraction step by using the magnitudes and phases of the spectrograms of all the channels as input to the network. The proposed DOAnet is evaluated by estimating the DOAs of multiple concurrently present sources in anechoic, matched and unmatched reverberant conditions. The results show that the proposed DOAnet is capable of estimating the number of sources and their respective DOAs with good precision and generate SPS with high signal-to-noise ratio.
Multichannel Sound Event Detection Using 3D Convolutional Neural Networks for Learning Inter-channel Features
Jan 29, 2018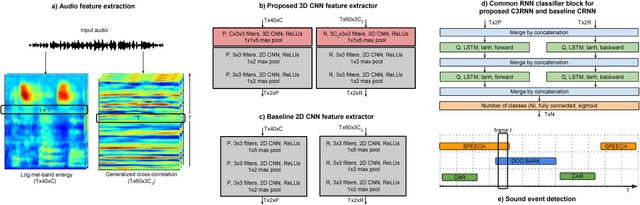
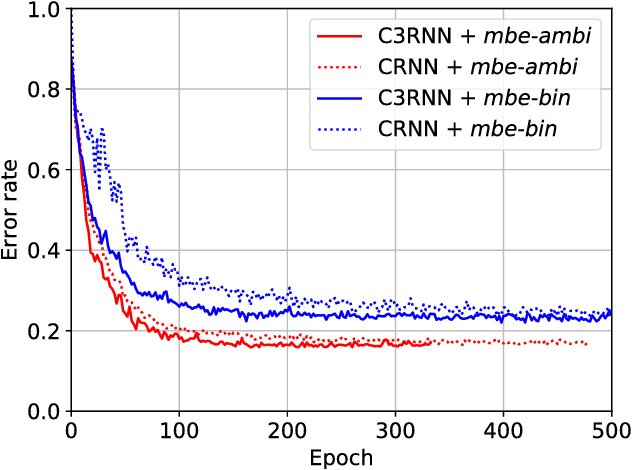
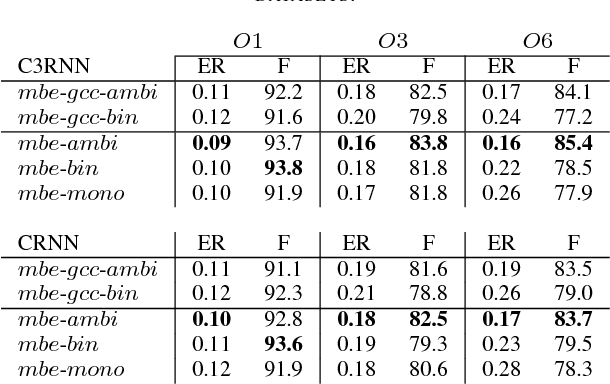
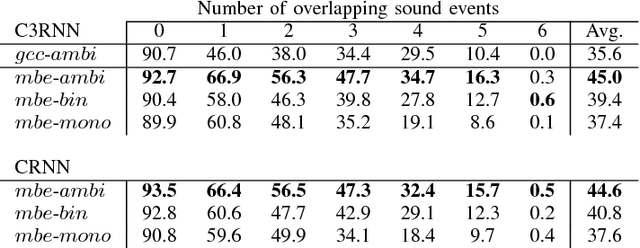
In this paper, we propose a stacked convolutional and recurrent neural network (CRNN) with a 3D convolutional neural network (CNN) in the first layer for the multichannel sound event detection (SED) task. The 3D CNN enables the network to simultaneously learn the inter- and intra-channel features from the input multichannel audio. In order to evaluate the proposed method, multichannel audio datasets with different number of overlapping sound sources are synthesized. Each of this dataset has a four-channel first-order Ambisonic, binaural, and single-channel versions, on which the performance of SED using the proposed method are compared to study the potential of SED using multichannel audio. A similar study is also done with the binaural and single-channel versions of the real-life recording TUT-SED 2017 development dataset. The proposed method learns to recognize overlapping sound events from multichannel features faster and performs better SED with a fewer number of training epochs. The results show that on using multichannel Ambisonic audio in place of single-channel audio we improve the overall F-score by 7.5%, overall error rate by 10% and recognize 15.6% more sound events in time frames with four overlapping sound sources.