 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Effects of Knowledge Distillation and Structured Pruning for Self-Supervised Speech Models
Feb 09, 2025Traditionally, Knowledge Distillation (KD) is used for model compression, often leading to suboptimal performance. In this paper, we evaluate the impact of combining KD loss with alternative pruning techniques, including Low-Rank Factorization (LRF) and l0 regularization, on a conformer-based pre-trained network under the paradigm of Self-Supervised Learning (SSL). We also propose a strategy to jointly prune and train an RNN-T-based ASR model, demonstrating that this approach yields superior performance compared to pruning a pre-trained network first and then using it for ASR training. This approach led to a significant reduction in word error rate: l0 and KD combination achieves the best non-streaming performance, with a 8.9% Relative Word Error Rate (RWER) improvement over the baseline, while LRF and KD combination yields the best results for streaming ASR, improving RWER by 13.4%.
On the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Context-based out-of-vocabulary word recovery for ASR systems in Indian languages
Jun 09, 2022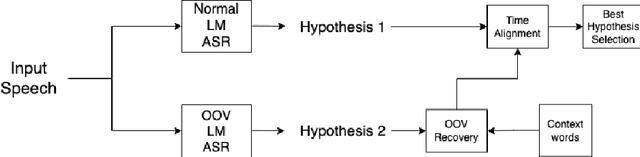
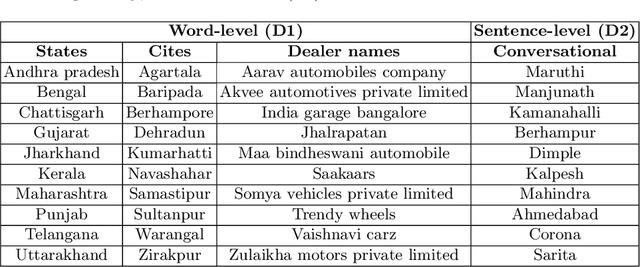
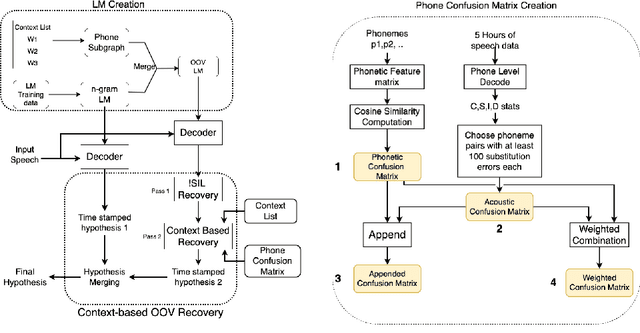
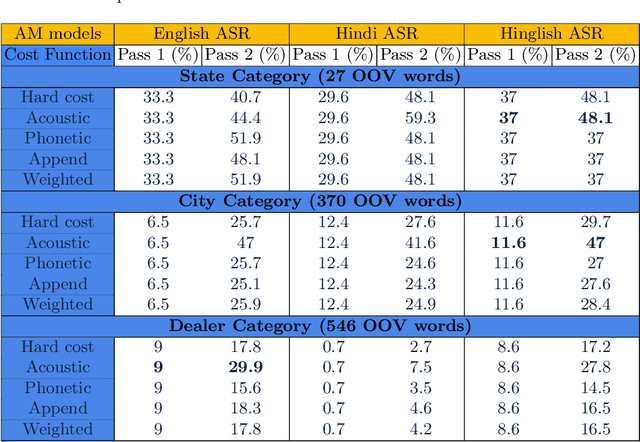
Detecting and recovering out-of-vocabulary (OOV) words is always challenging for Automatic Speech Recognition (ASR) systems. Many existing methods focus on modeling OOV words by modifying acoustic and language models and integrating context words cleverly into models. To train such complex models, we need a large amount of data with context words, additional training time, and increased model size. However, after getting the ASR transcription to recover context-based OOV words, the post-processing method has not been explored much. In this work, we propose a post-processing technique to improve the performance of context-based OOV recovery. We created an acoustically boosted language model with a sub-graph made at phone level with an OOV words list. We proposed two methods to determine a suitable cost function to retrieve the OOV words based on the context. The cost function is defined based on phonetic and acoustic knowledge for matching and recovering the correct context words in the decode. The effectiveness of the proposed cost function is evaluated at both word-level and sentence-level. The evaluation results show that this approach can recover an average of 50% context-based OOV words across multiple categories.
Non-native English lexicon creation for bilingual speech synthesis
Jun 21, 2021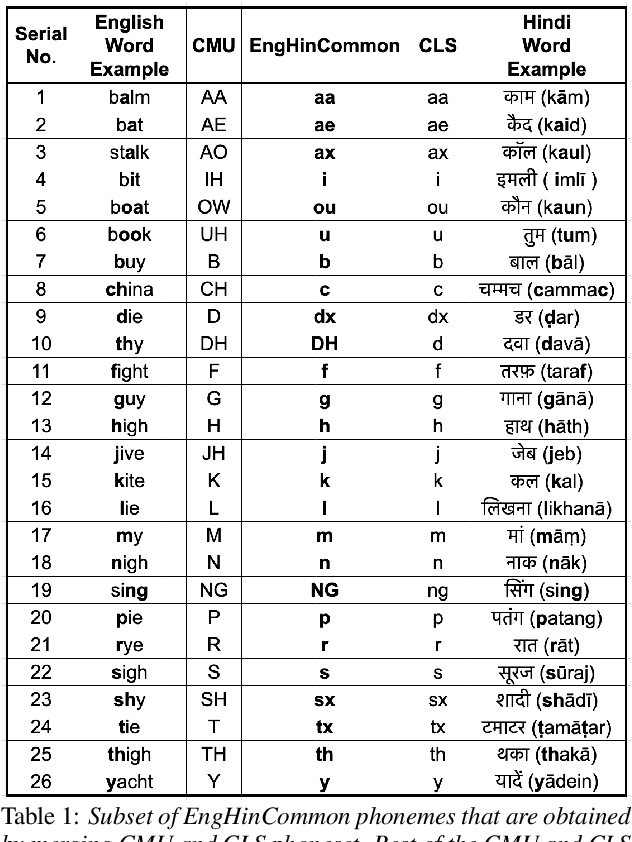
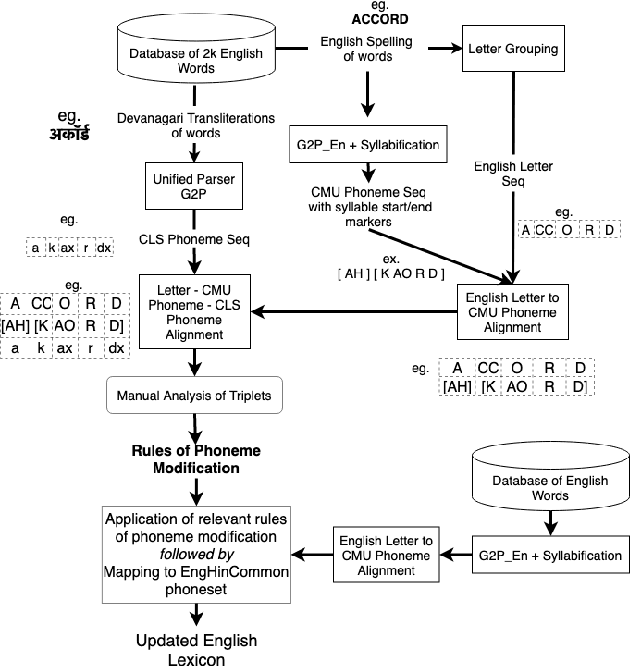
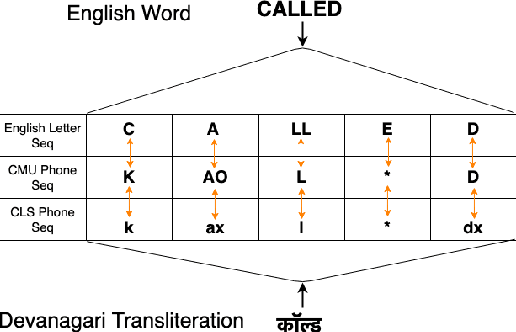
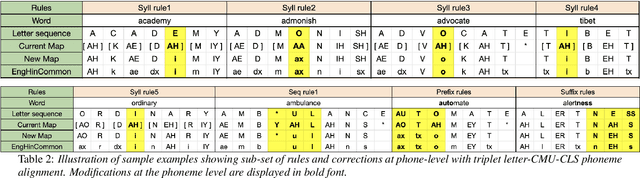
Bilingual English speakers speak English as one of their languages. Their English is of a non-native kind, and their conversations are of a code-mixed fashion. The intelligibility of a bilingual text-to-speech (TTS) system for such non-native English speakers depends on a lexicon that captures the phoneme sequence used by non-native speakers. However, due to the lack of non-native English lexicon, existing bilingual TTS systems employ native English lexicons that are widely available, in addition to their native language lexicon. Due to the inconsistency between the non-native English pronunciation in the audio and native English lexicon in the text, the intelligibility of synthesized speech in such TTS systems is significantly reduced. This paper is motivated by the knowledge that the native language of the speaker highly influences non-native English pronunciation. We propose a generic approach to obtain rules based on letter to phoneme alignment to map native English lexicon to their non-native version. The effectiveness of such mapping is studied by comparing bilingual (Indian English and Hindi) TTS systems trained with and without the proposed rules. The subjective evaluation shows that the bilingual TTS system trained with the proposed non-native English lexicon rules obtains a 6% absolute improvement in preference.
A non-causal FFTNet architecture for speech enhancement
Jun 08, 2020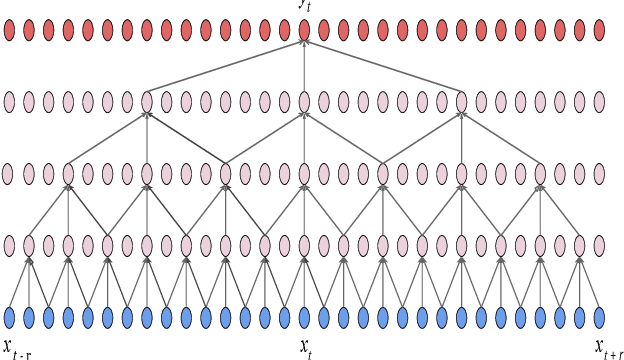
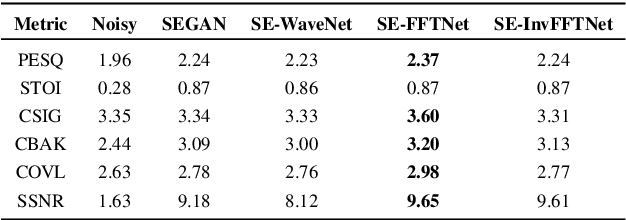
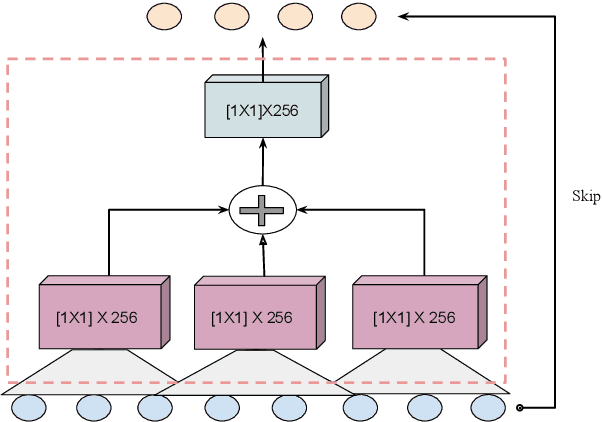

In this paper, we suggest a new parallel, non-causal and shallow waveform domain architecture for speech enhancement based on FFTNet, a neural network for generating high quality audio waveform. In contrast to other waveform based approaches like WaveNet, FFTNet uses an initial wide dilation pattern. Such an architecture better represents the long term correlated structure of speech in the time domain, where noise is usually highly non-correlated, and therefore it is suitable for waveform domain based speech enhancement. To further strengthen this feature of FFTNet, we suggest a non-causal FFTNet architecture, where the present sample in each layer is estimated from the past and future samples of the previous layer. By suggesting a shallow network and applying non-causality within certain limits, the suggested FFTNet for speech enhancement (SE-FFTNet) uses much fewer parameters compared to other neural network based approaches for speech enhancement like WaveNet and SEGAN. Specifically, the suggested network has considerably reduced model parameters: 32% fewer compared to WaveNet and 87% fewer compared to SEGAN. Finally, based on subjective and objective metrics, SE-FFTNet outperforms WaveNet in terms of enhanced signal quality, while it provides equally good performance as SEGAN. A Tensorflow implementation of the architecture is provided at 1 .