 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Macro-block dropout for improved regularization in training end-to-end speech recognition models
Dec 29, 2022



This paper proposes a new regularization algorithm referred to as macro-block dropout. The overfitting issue has been a difficult problem in training large neural network models. The dropout technique has proven to be simple yet very effective for regularization by preventing complex co-adaptations during training. In our work, we define a macro-block that contains a large number of units from the input to a Recurrent Neural Network (RNN). Rather than applying dropout to each unit, we apply random dropout to each macro-block. This algorithm has the effect of applying different drop out rates for each layer even if we keep a constant average dropout rate, which has better regularization effects. In our experiments using Recurrent Neural Network-Transducer (RNN-T), this algorithm shows relatively 4.30 % and 6.13 % Word Error Rates (WERs) improvement over the conventional dropout on LibriSpeech test-clean and test-other. With an Attention-based Encoder-Decoder (AED) model, this algorithm shows relatively 4.36 % and 5.85 % WERs improvement over the conventional dropout on the same test sets.
S-SGD: Symmetrical Stochastic Gradient Descent with Weight Noise Injection for Reaching Flat Minima
Sep 05, 2020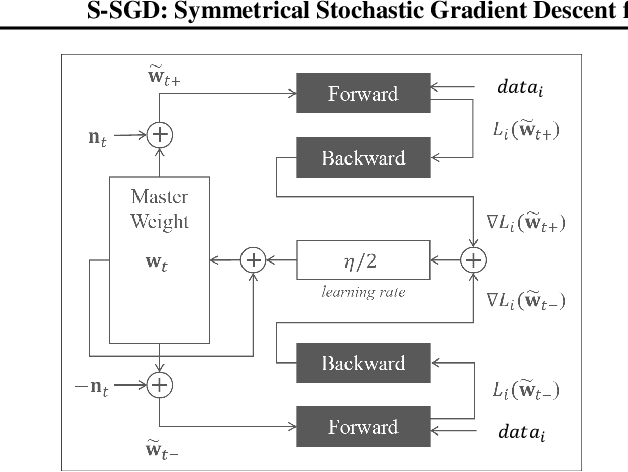
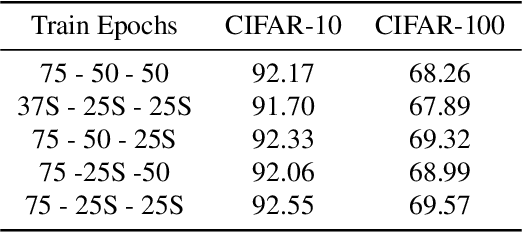
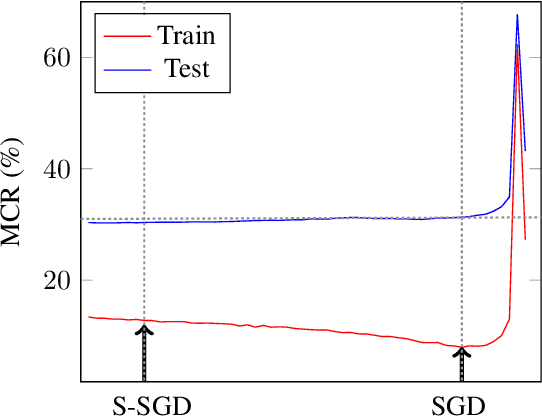
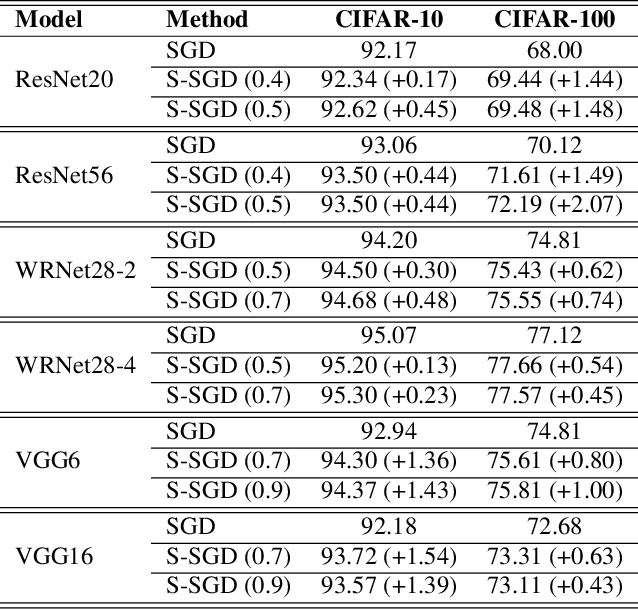
The stochastic gradient descent (SGD) method is most widely used for deep neural network (DNN) training. However, the method does not always converge to a flat minimum of the loss surface that can demonstrate high generalization capability. Weight noise injection has been extensively studied for finding flat minima using the SGD method. We devise a new weight-noise injection-based SGD method that adds symmetrical noises to the DNN weights. The training with symmetrical noise evaluates the loss surface at two adjacent points, by which convergence to sharp minima can be avoided. Fixed-magnitude symmetric noises are added to minimize training instability. The proposed method is compared with the conventional SGD method and previous weight-noise injection algorithms using convolutional neural networks for image classification. Particularly, performance improvements in large batch training are demonstrated. This method shows superior performance compared with conventional SGD and weight-noise injection methods regardless of the batch-size and learning rate scheduling algorithms.
Single Stream Parallelization of Recurrent Neural Networks for Low Power and Fast Inference
Mar 30, 2018

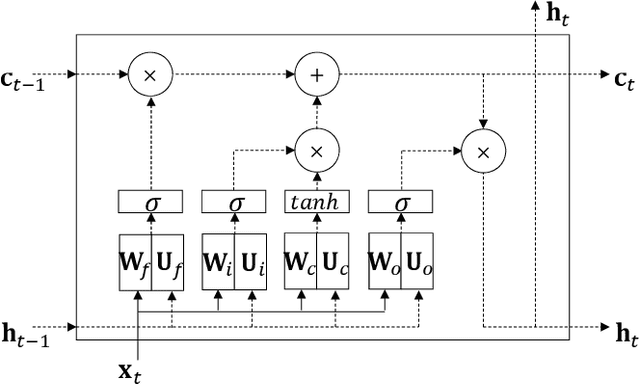

As neural network algorithms show high performance in many applications, their efficient inference on mobile and embedded systems are of great interests. When a single stream recurrent neural network (RNN) is executed for a personal user in embedded systems, it demands a large amount of DRAM accesses because the network size is usually much bigger than the cache size and the weights of an RNN are used only once at each time step. We overcome this problem by parallelizing the algorithm and executing it multiple time steps at a time. This approach also reduces the power consumption by lowering the number of DRAM accesses. QRNN (Quasi Recurrent Neural Networks) and SRU (Simple Recurrent Unit) based recurrent neural networks are used for implementation. The experiments for SRU showed about 300% and 930% of speed-up when the numbers of multi time steps are 4 and 16, respectively, in an ARM CPU based system.
FPGA-Based Low-Power Speech Recognition with Recurrent Neural Networks
Sep 30, 2016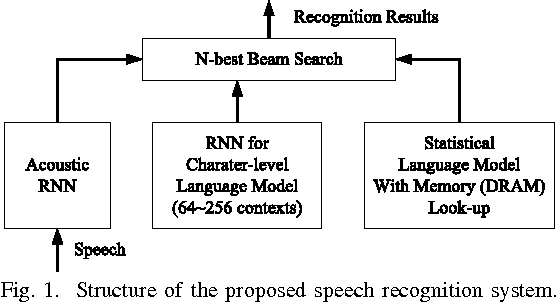
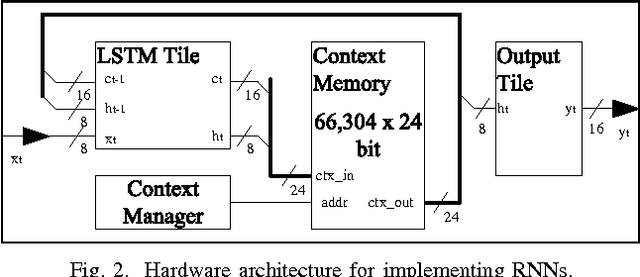
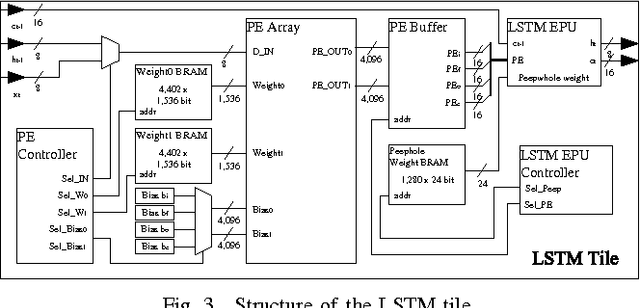
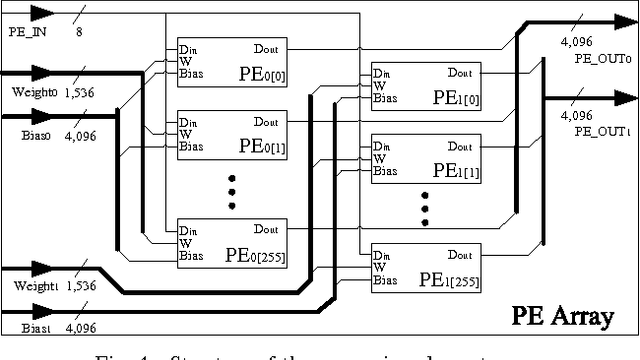
In this paper, a neural network based real-time speech recognition (SR) system is developed using an FPGA for very low-power operation. The implemented system employs two recurrent neural networks (RNNs); one is a speech-to-character RNN for acoustic modeling (AM) and the other is for character-level language modeling (LM). The system also employs a statistical word-level LM to improve the recognition accuracy. The results of the AM, the character-level LM, and the word-level LM are combined using a fairly simple N-best search algorithm instead of the hidden Markov model (HMM) based network. The RNNs are implemented using massively parallel processing elements (PEs) for low latency and high throughput. The weights are quantized to 6 bits to store all of them in the on-chip memory of an FPGA. The proposed algorithm is implemented on a Xilinx XC7Z045, and the system can operate much faster than real-time.
FPGA Based Implementation of Deep Neural Networks Using On-chip Memory Only
Aug 29, 2016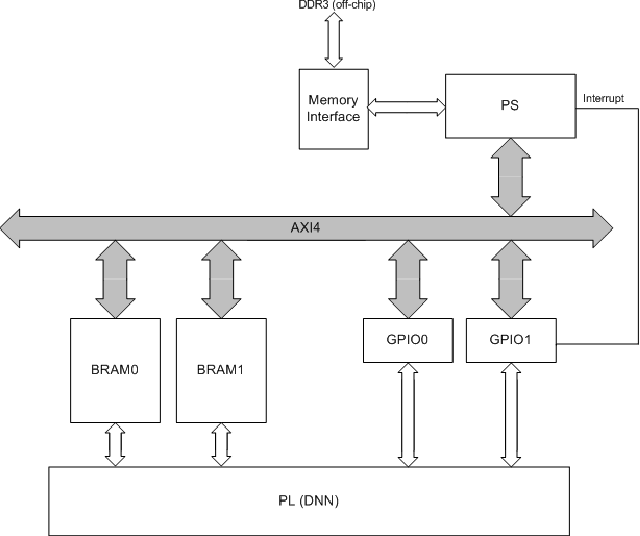



Deep neural networks (DNNs) demand a very large amount of computation and weight storage, and thus efficient implementation using special purpose hardware is highly desired. In this work, we have developed an FPGA based fixed-point DNN system using only on-chip memory not to access external DRAM. The execution time and energy consumption of the developed system is compared with a GPU based implementation. Since the capacity of memory in FPGA is limited, only 3-bit weights are used for this implementation, and training based fixed-point weight optimization is employed. The implementation using Xilinx XC7Z045 is tested for the MNIST handwritten digit recognition benchmark and a phoneme recognition task on TIMIT corpus. The obtained speed is about one quarter of a GPU based implementation and much better than that of a PC based one. The power consumption is less than 5 Watt at the full speed operation resulting in much higher efficiency compared to GPU based systems.