 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleep Model -- A Sequence Model for Predicting the Next Sleep Stage
Feb 17, 2023As sleep disorders are becoming more prevalent there is an urgent need to classify sleep stages in a less disturbing way.In particular, sleep-stage classification using simple sensors, such as single-channel electroencephalography (EEG), electrooculography (EOG), electromyography (EMG), or electrocardiography (ECG) has gained substantial interest. In this study, we proposed a sleep model that predicts the next sleep stage and used it to improve sleep classification accuracy. The sleep models were built using sleep-sequence data and employed either statistical $n$-gram or deep neural network-based models. We developed beam-search decoding to combine the information from the sensor and the sleep models. Furthermore, we evaluated the performance of the $n$-gram and long short-term memory (LSTM) recurrent neural network (RNN)-based sleep models and demonstrated the improvement of sleep-stage classification using an EOG sensor. The developed sleep models significantly improved the accuracy of sleep-stage classification, particularly in the absence of an EEG sensor.
Layer-wise Pruning of Transformer Attention Heads for Efficient Language Modeling
Oct 07, 2021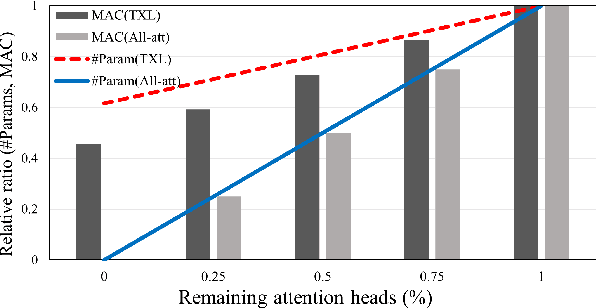
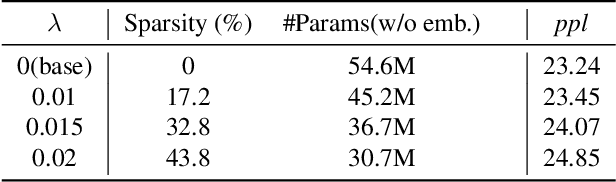
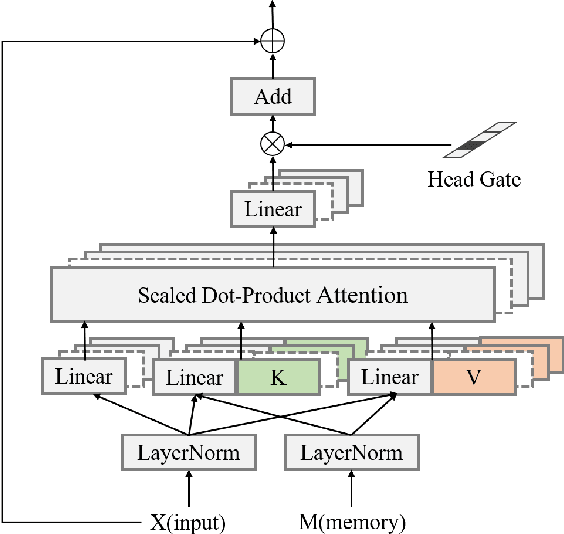
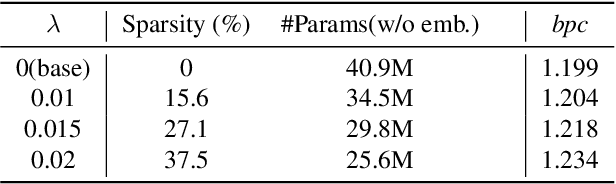
While Transformer-based models have shown impressive language modeling performance, the large computation cost is often prohibitive for practical use. Attention head pruning, which removes unnecessary attention heads in the multihead attention, is a promising technique to solve this problem. However, it does not evenly reduce the overall load because the heavy feedforward module is not affected by head pruning. In this paper, we apply layer-wise attention head pruning on All-attention Transformer so that the entire computation and the number of parameters can be reduced proportionally to the number of pruned heads. While the architecture has the potential to fully utilize head pruning, we propose three training methods that are especially helpful to minimize performance degradation and stabilize the pruning process. Our pruned model shows consistently lower perplexity within a comparable parameter size than Transformer-XL on WikiText-103 language modeling benchmark.
S-SGD: Symmetrical Stochastic Gradient Descent with Weight Noise Injection for Reaching Flat Minima
Sep 05, 2020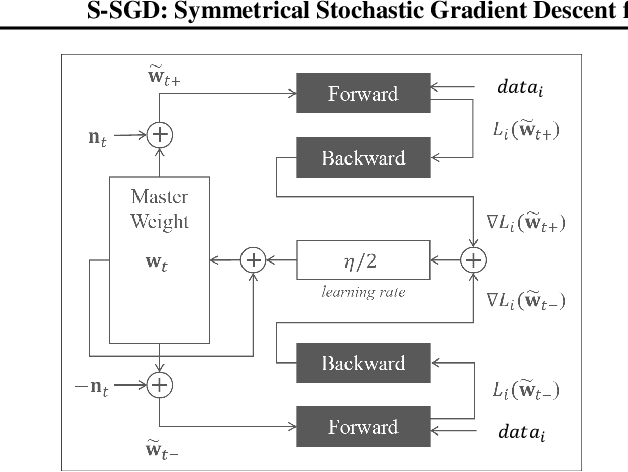
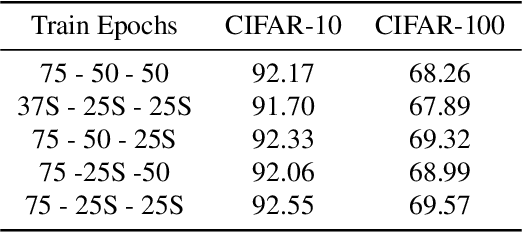
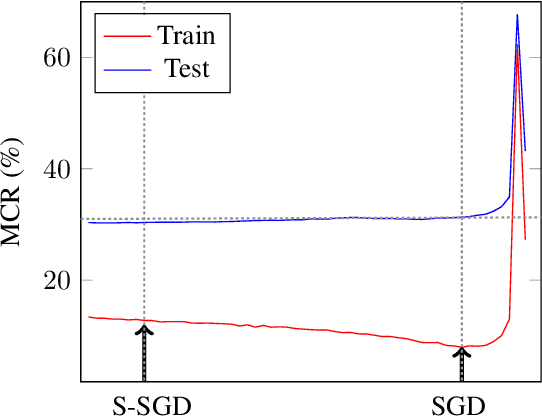
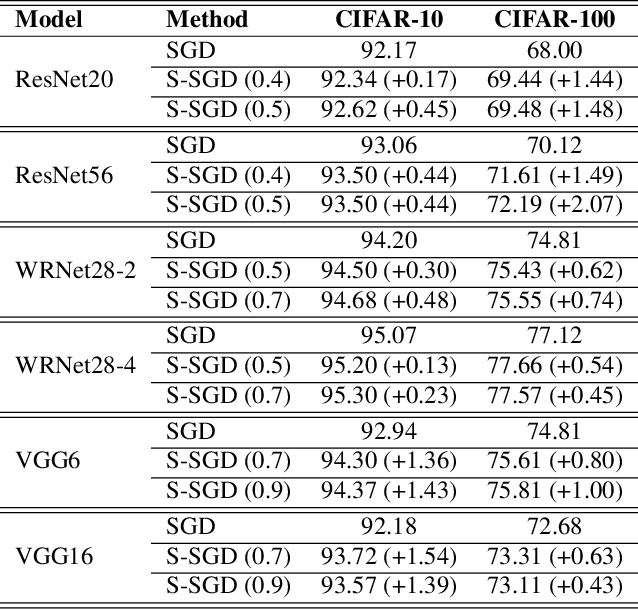
The stochastic gradient descent (SGD) method is most widely used for deep neural network (DNN) training. However, the method does not always converge to a flat minimum of the loss surface that can demonstrate high generalization capability. Weight noise injection has been extensively studied for finding flat minima using the SGD method. We devise a new weight-noise injection-based SGD method that adds symmetrical noises to the DNN weights. The training with symmetrical noise evaluates the loss surface at two adjacent points, by which convergence to sharp minima can be avoided. Fixed-magnitude symmetric noises are added to minimize training instability. The proposed method is compared with the conventional SGD method and previous weight-noise injection algorithms using convolutional neural networks for image classification. Particularly, performance improvements in large batch training are demonstrated. This method shows superior performance compared with conventional SGD and weight-noise injection methods regardless of the batch-size and learning rate scheduling algorithms.