 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization
Nov 09, 2023
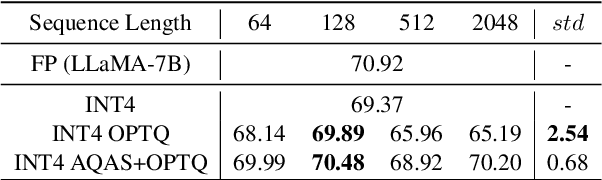

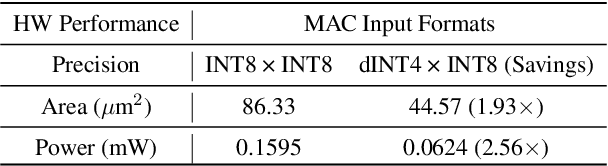
Large Language Models (LLMs) are proficient in natural language processing tasks, but their deployment is often restricted by extensive parameter sizes and computational demands. This paper focuses on post-training quantization (PTQ) in LLMs, specifically 4-bit weight and 8-bit activation (W4A8) quantization, to enhance computational efficiency -- a topic less explored compared to weight-only quantization. We present two innovative techniques: activation-quantization-aware scaling (AQAS) and sequence-length-aware calibration (SLAC) to enhance PTQ by considering the combined effects on weights and activations and aligning calibration sequence lengths to target tasks. Moreover, we introduce dINT, a hybrid data format combining integer and denormal representations, to address the underflow issue in W4A8 quantization, where small values are rounded to zero. Through rigorous evaluations of LLMs, including OPT and LLaMA, we demonstrate that our techniques significantly boost task accuracies to levels comparable with full-precision models. By developing arithmetic units compatible with dINT, we further confirm that our methods yield a 2$\times$ hardware efficiency improvement compared to 8-bit integer MAC unit.
Token-Scaled Logit Distillation for Ternary Weight Generative Language Models
Aug 13, 2023Generative Language Models (GLMs) have shown impressive performance in tasks such as text generation, understanding, and reasoning. However, the large model size poses challenges for practical deployment. To solve this problem, Quantization-Aware Training (QAT) has become increasingly popular. However, current QAT methods for generative models have resulted in a noticeable loss of accuracy. To counteract this issue, we propose a novel knowledge distillation method specifically designed for GLMs. Our method, called token-scaled logit distillation, prevents overfitting and provides superior learning from the teacher model and ground truth. This research marks the first evaluation of ternary weight quantization-aware training of large-scale GLMs with less than 1.0 degradation in perplexity and no loss of accuracy in a reasoning task.
Teacher Intervention: Improving Convergence of Quantization Aware Training for Ultra-Low Precision Transformers
Feb 23, 2023Pre-trained Transformer models such as BERT have shown great success in a wide range of applications, but at the cost of substantial increases in model complexity. Quantization-aware training (QAT) is a promising method to lower the implementation cost and energy consumption. However, aggressive quantization below 2-bit causes considerable accuracy degradation due to unstable convergence, especially when the downstream dataset is not abundant. This work proposes a proactive knowledge distillation method called Teacher Intervention (TI) for fast converging QAT of ultra-low precision pre-trained Transformers. TI intervenes layer-wise signal propagation with the intact signal from the teacher to remove the interference of propagated quantization errors, smoothing loss surface of QAT and expediting the convergence. Furthermore, we propose a gradual intervention mechanism to stabilize the recovery of subsections of Transformer layers from quantization. The proposed schemes enable fast convergence of QAT and improve the model accuracy regardless of the diverse characteristics of downstream fine-tuning tasks. We demonstrate that TI consistently achieves superior accuracy with significantly lower fine-tuning iterations on well-known Transformers of natural language processing as well as computer vision compared to the state-of-the-art QAT methods.
Sleep Model -- A Sequence Model for Predicting the Next Sleep Stage
Feb 17, 2023As sleep disorders are becoming more prevalent there is an urgent need to classify sleep stages in a less disturbing way.In particular, sleep-stage classification using simple sensors, such as single-channel electroencephalography (EEG), electrooculography (EOG), electromyography (EMG), or electrocardiography (ECG) has gained substantial interest. In this study, we proposed a sleep model that predicts the next sleep stage and used it to improve sleep classification accuracy. The sleep models were built using sleep-sequence data and employed either statistical $n$-gram or deep neural network-based models. We developed beam-search decoding to combine the information from the sensor and the sleep models. Furthermore, we evaluated the performance of the $n$-gram and long short-term memory (LSTM) recurrent neural network (RNN)-based sleep models and demonstrated the improvement of sleep-stage classification using an EOG sensor. The developed sleep models significantly improved the accuracy of sleep-stage classification, particularly in the absence of an EEG sensor.
Exploring Attention Map Reuse for Efficient Transformer Neural Networks
Jan 29, 2023



Transformer-based deep neural networks have achieved great success in various sequence applications due to their powerful ability to model long-range dependency. The key module of Transformer is self-attention (SA) which extracts features from the entire sequence regardless of the distance between positions. Although SA helps Transformer performs particularly well on long-range tasks, SA requires quadratic computation and memory complexity with the input sequence length. Recently, attention map reuse, which groups multiple SA layers to share one attention map, has been proposed and achieved significant speedup for speech recognition models. In this paper, we provide a comprehensive study on attention map reuse focusing on its ability to accelerate inference. We compare the method with other SA compression techniques and conduct a breakdown analysis of its advantages for a long sequence. We demonstrate the effectiveness of attention map reuse by measuring the latency on both CPU and GPU platforms.
Macro-block dropout for improved regularization in training end-to-end speech recognition models
Dec 29, 2022



This paper proposes a new regularization algorithm referred to as macro-block dropout. The overfitting issue has been a difficult problem in training large neural network models. The dropout technique has proven to be simple yet very effective for regularization by preventing complex co-adaptations during training. In our work, we define a macro-block that contains a large number of units from the input to a Recurrent Neural Network (RNN). Rather than applying dropout to each unit, we apply random dropout to each macro-block. This algorithm has the effect of applying different drop out rates for each layer even if we keep a constant average dropout rate, which has better regularization effects. In our experiments using Recurrent Neural Network-Transducer (RNN-T), this algorithm shows relatively 4.30 % and 6.13 % Word Error Rates (WERs) improvement over the conventional dropout on LibriSpeech test-clean and test-other. With an Attention-based Encoder-Decoder (AED) model, this algorithm shows relatively 4.36 % and 5.85 % WERs improvement over the conventional dropout on the same test sets.
A Comparison of Transformer, Convolutional, and Recurrent Neural Networks on Phoneme Recognition
Oct 01, 2022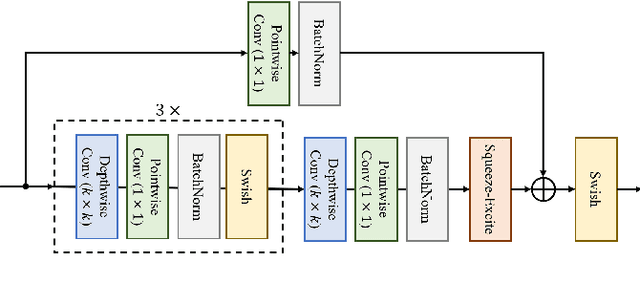
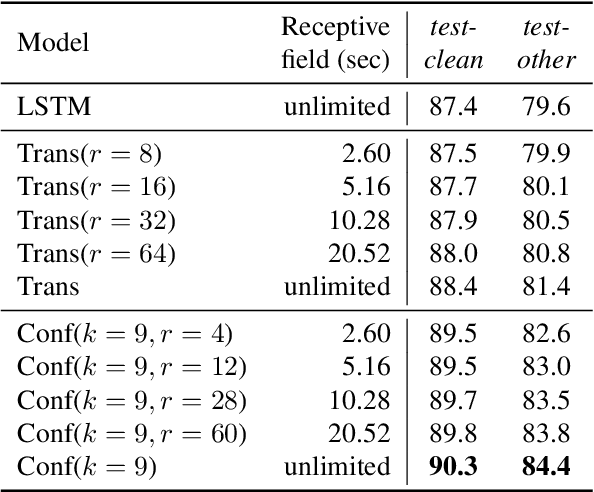
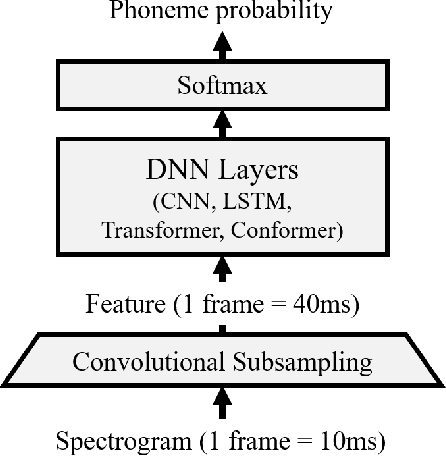
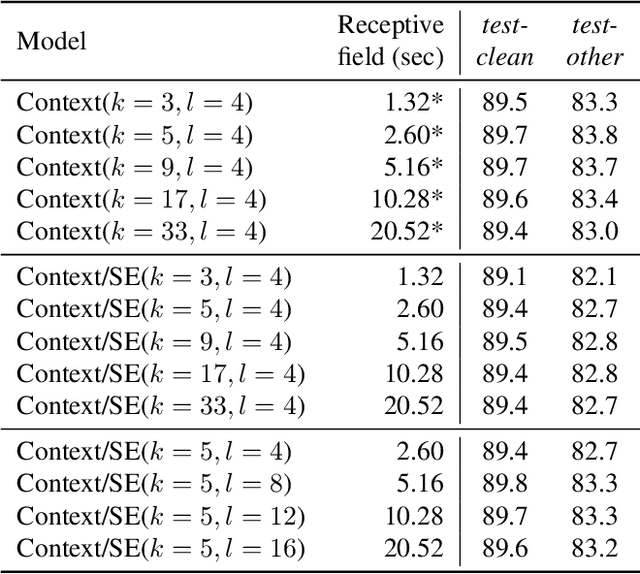
Phoneme recognition is a very important part of speech recognition that requires the ability to extract phonetic features from multiple frames. In this paper, we compare and analyze CNN, RNN, Transformer, and Conformer models using phoneme recognition. For CNN, the ContextNet model is used for the experiments. First, we compare the accuracy of various architectures under different constraints, such as the receptive field length, parameter size, and layer depth. Second, we interpret the performance difference of these models, especially when the observable sequence length varies. Our analyses show that Transformer and Conformer models benefit from the long-range accessibility of self-attention through input frames.
Korean Tokenization for Beam Search Rescoring in Speech Recognition
Mar 28, 2022
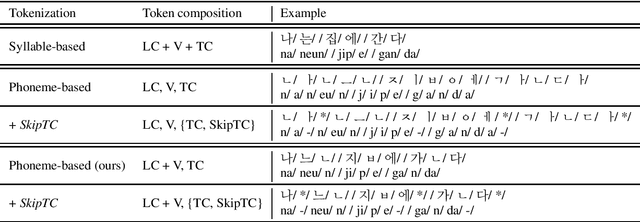
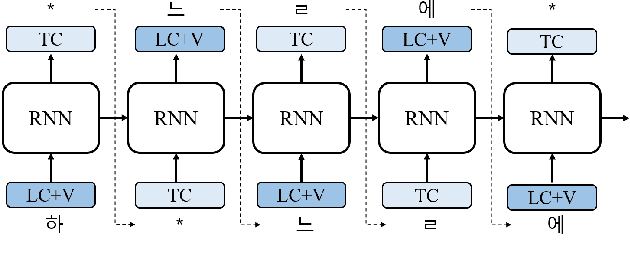
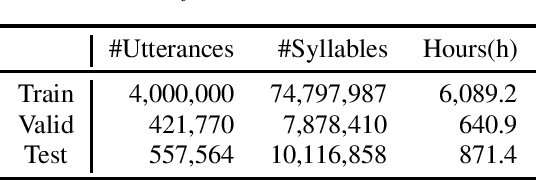
The performance of automatic speech recognition (ASR) models can be greatly improved by proper beam-search decoding with external language model (LM). There has been an increasing interest in Korean speech recognition, but not many studies have been focused on the decoding procedure. In this paper, we propose a Korean tokenization method for neural network-based LM used for Korean ASR. Although the common approach is to use the same tokenization method for external LM as the ASR model, we show that it may not be the best choice for Korean. We propose a new tokenization method that inserts a special token, SkipTC, when there is no trailing consonant in a Korean syllable. By utilizing the proposed SkipTC token, the input sequence for LM becomes very regularly patterned so that the LM can better learn the linguistic characteristics. Our experiments show that the proposed approach achieves a lower word error rate compared to the same LM model without SkipTC. In addition, we are the first to report the ASR performance for the recently introduced large-scale 7,600h Korean speech dataset.
Similarity and Content-based Phonetic Self Attention for Speech Recognition
Mar 28, 2022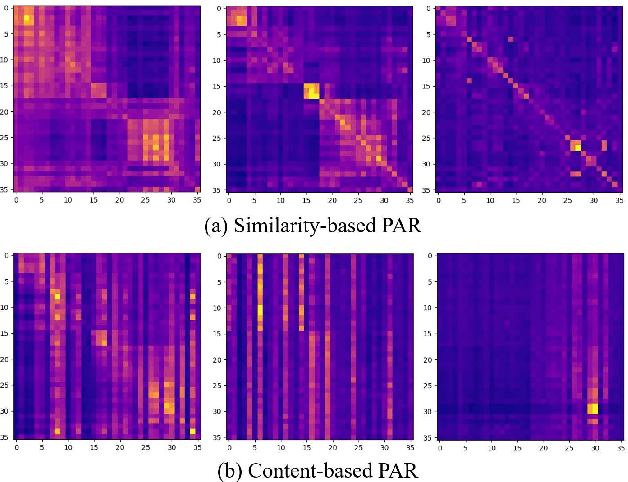
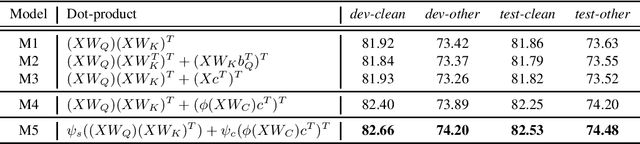
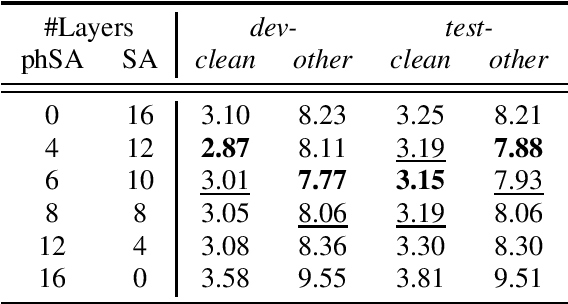

Transformer-based speech recognition models have achieved great success due to the self-attention (SA) mechanism that utilizes every frame in the feature extraction process. Especially, SA heads in lower layers capture various phonetic characteristics by the query-key dot product, which is designed to compute the pairwise relationship between frames. In this paper, we propose a variant of SA to extract more representative phonetic features. The proposed phonetic self-attention (phSA) is composed of two different types of phonetic attention; one is similarity-based and the other is content-based. In short, similarity-based attention utilizes the correlation between frames while content-based attention only considers each frame without being affected by others. We identify which parts of the original dot product are related to two different attention patterns and improve each part by simple modifications. Our experiments on phoneme classification and speech recognition show that replacing SA with phSA for lower layers improves the recognition performance without increasing the latency and the parameter size.
Layer-wise Pruning of Transformer Attention Heads for Efficient Language Modeling
Oct 07, 2021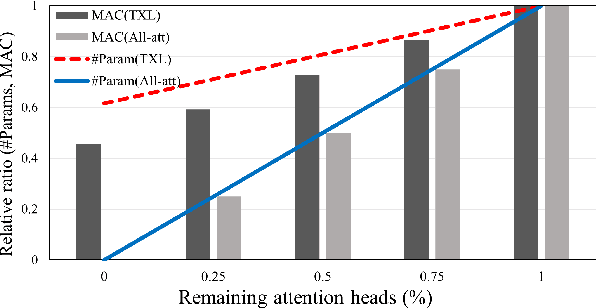
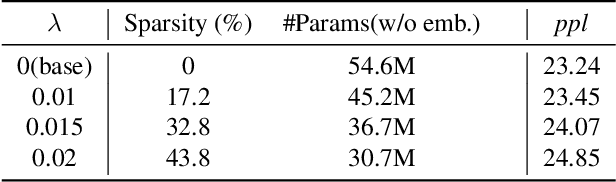
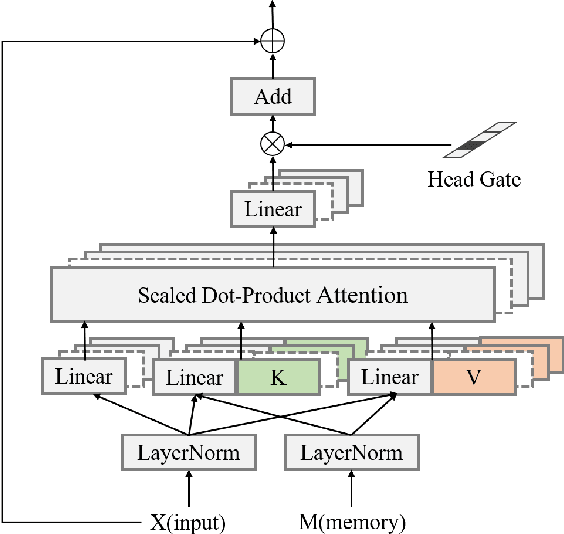
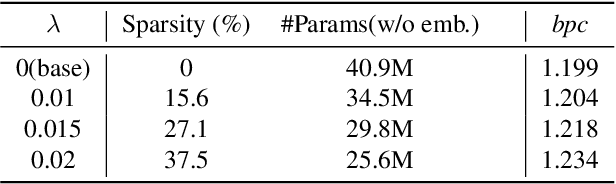
While Transformer-based models have shown impressive language modeling performance, the large computation cost is often prohibitive for practical use. Attention head pruning, which removes unnecessary attention heads in the multihead attention, is a promising technique to solve this problem. However, it does not evenly reduce the overall load because the heavy feedforward module is not affected by head pruning. In this paper, we apply layer-wise attention head pruning on All-attention Transformer so that the entire computation and the number of parameters can be reduced proportionally to the number of pruned heads. While the architecture has the potential to fully utilize head pruning, we propose three training methods that are especially helpful to minimize performance degradation and stabilize the pruning process. Our pruned model shows consistently lower perplexity within a comparable parameter size than Transformer-XL on WikiText-103 language modeling benchmark.