 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Scaled Logit Distillation for Ternary Weight Generative Language Models
Aug 13, 2023Generative Language Models (GLMs) have shown impressive performance in tasks such as text generation, understanding, and reasoning. However, the large model size poses challenges for practical deployment. To solve this problem, Quantization-Aware Training (QAT) has become increasingly popular. However, current QAT methods for generative models have resulted in a noticeable loss of accuracy. To counteract this issue, we propose a novel knowledge distillation method specifically designed for GLMs. Our method, called token-scaled logit distillation, prevents overfitting and provides superior learning from the teacher model and ground truth. This research marks the first evaluation of ternary weight quantization-aware training of large-scale GLMs with less than 1.0 degradation in perplexity and no loss of accuracy in a reasoning task.
Understanding and Improving Knowledge Distillation for Quantization-Aware Training of Large Transformer Encoders
Nov 20, 2022



Knowledge distillation (KD) has been a ubiquitous method for model compression to strengthen the capability of a lightweight model with the transferred knowledge from the teacher. In particular, KD has been employed in quantization-aware training (QAT) of Transformer encoders like BERT to improve the accuracy of the student model with the reduced-precision weight parameters. However, little is understood about which of the various KD approaches best fits the QAT of Transformers. In this work, we provide an in-depth analysis of the mechanism of KD on attention recovery of quantized large Transformers. In particular, we reveal that the previously adopted MSE loss on the attention score is insufficient for recovering the self-attention information. Therefore, we propose two KD methods; attention-map and attention-output losses. Furthermore, we explore the unification of both losses to address task-dependent preference between attention-map and output losses. The experimental results on various Transformer encoder models demonstrate that the proposed KD methods achieve state-of-the-art accuracy for QAT with sub-2-bit weight quantization.
NN-LUT: Neural Approximation of Non-Linear Operations for Efficient Transformer Inference
Dec 03, 2021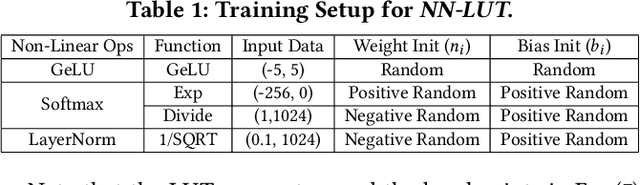
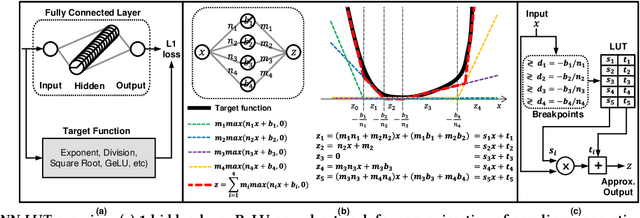
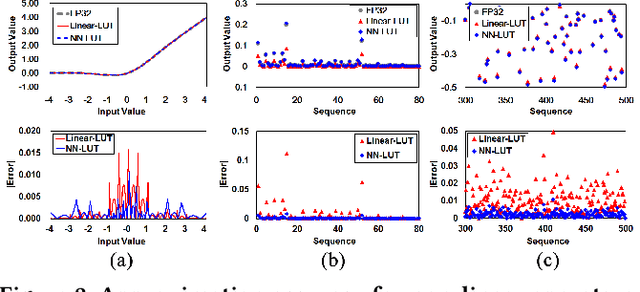
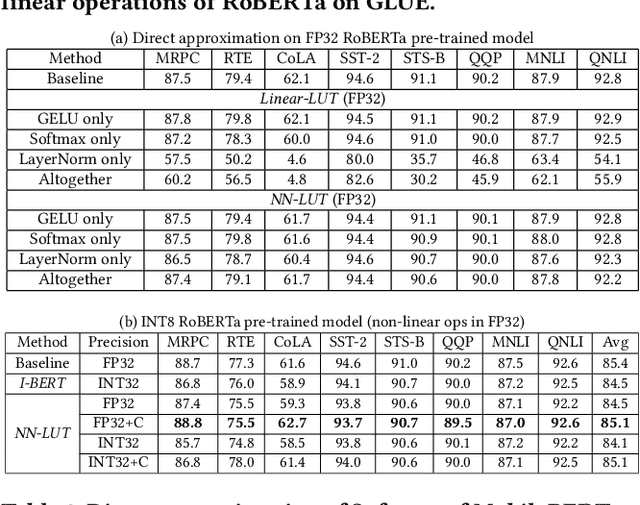
Non-linear operations such as GELU, Layer normalization, and Softmax are essential yet costly building blocks of Transformer models. Several prior works simplified these operations with look-up tables or integer computations, but such approximations suffer inferior accuracy or considerable hardware cost with long latency. This paper proposes an accurate and hardware-friendly approximation framework for efficient Transformer inference. Our framework employs a simple neural network as a universal approximator with its structure equivalently transformed into a LUT. The proposed framework called NN-LUT can accurately replace all the non-linear operations in popular BERT models with significant reductions in area, power consumption, and latency.