 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Effects of Knowledge Distillation and Structured Pruning for Self-Supervised Speech Models
Feb 09, 2025Traditionally, Knowledge Distillation (KD) is used for model compression, often leading to suboptimal performance. In this paper, we evaluate the impact of combining KD loss with alternative pruning techniques, including Low-Rank Factorization (LRF) and l0 regularization, on a conformer-based pre-trained network under the paradigm of Self-Supervised Learning (SSL). We also propose a strategy to jointly prune and train an RNN-T-based ASR model, demonstrating that this approach yields superior performance compared to pruning a pre-trained network first and then using it for ASR training. This approach led to a significant reduction in word error rate: l0 and KD combination achieves the best non-streaming performance, with a 8.9% Relative Word Error Rate (RWER) improvement over the baseline, while LRF and KD combination yields the best results for streaming ASR, improving RWER by 13.4%.
On the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Multi-stage Progressive Compression of Conformer Transducer for On-device Speech Recognition
Oct 01, 2022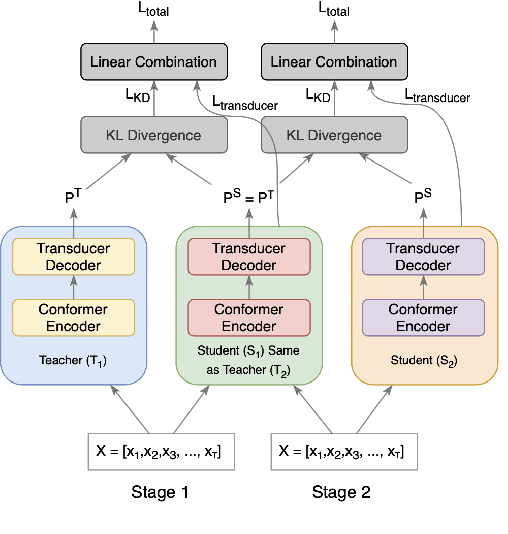
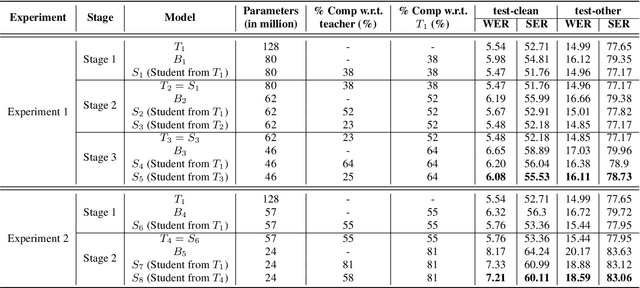
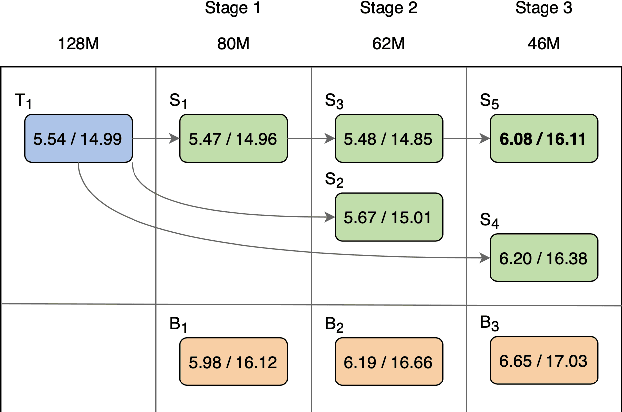
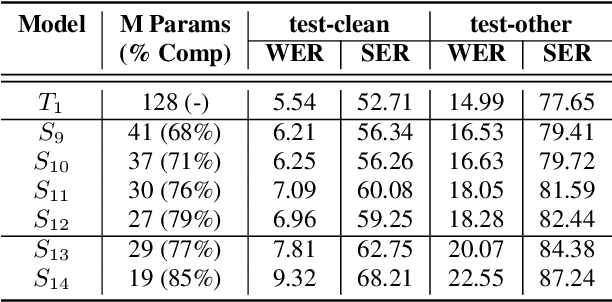
The smaller memory bandwidth in smart devices prompts development of smaller Automatic Speech Recognition (ASR) models. To obtain a smaller model, one can employ the model compression techniques. Knowledge distillation (KD) is a popular model compression approach that has shown to achieve smaller model size with relatively lesser degradation in the model performance. In this approach, knowledge is distilled from a trained large size teacher model to a smaller size student model. Also, the transducer based models have recently shown to perform well for on-device streaming ASR task, while the conformer models are efficient in handling long term dependencies. Hence in this work we employ a streaming transducer architecture with conformer as the encoder. We propose a multi-stage progressive approach to compress the conformer transducer model using KD. We progressively update our teacher model with the distilled student model in a multi-stage setup. On standard LibriSpeech dataset, our experimental results have successfully achieved compression rates greater than 60% without significant degradation in the performance compared to the larger teacher model.
* Published in INTERSPEECH 2022
Two-Pass End-to-End ASR Model Compression
Jan 08, 2022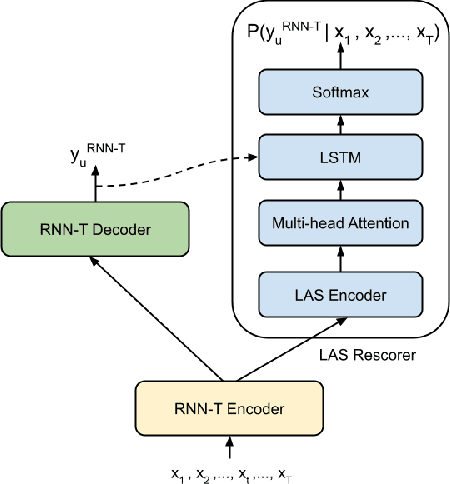

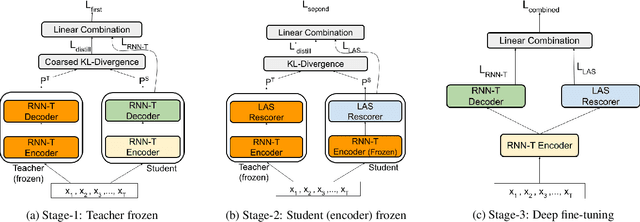
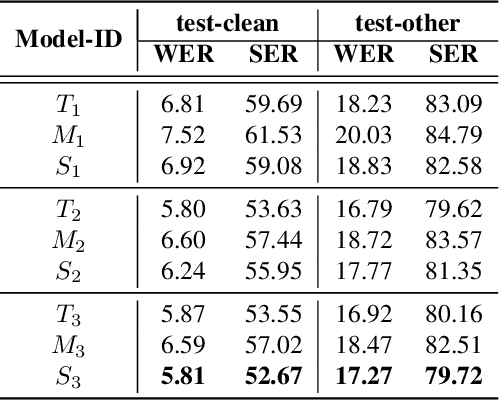
Speech recognition on smart devices is challenging owing to the small memory footprint. Hence small size ASR models are desirable. With the use of popular transducer-based models, it has become possible to practically deploy streaming speech recognition models on small devices [1]. Recently, the two-pass model [2] combining RNN-T and LAS modules has shown exceptional performance for streaming on-device speech recognition. In this work, we propose a simple and effective approach to reduce the size of the two-pass model for memory-constrained devices. We employ a popular knowledge distillation approach in three stages using the Teacher-Student training technique. In the first stage, we use a trained RNN-T model as a teacher model and perform knowledge distillation to train the student RNN-T model. The second stage uses the shared encoder and trains a LAS rescorer for student model using the trained RNN-T+LAS teacher model. Finally, we perform deep-finetuning for the student model with a shared RNN-T encoder, RNN-T decoder, and LAS rescorer. Our experimental results on standard LibriSpeech dataset show that our system can achieve a high compression rate of 55% without significant degradation in the WER compared to the two-pass teacher model.
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019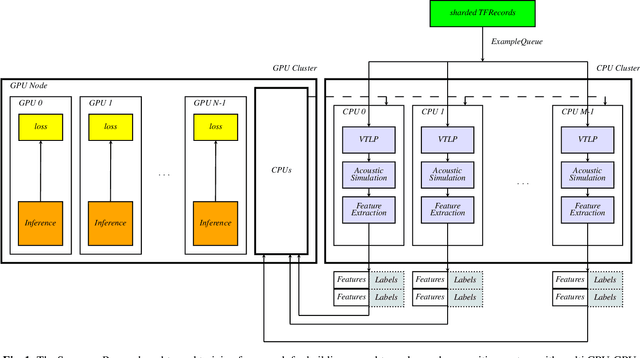
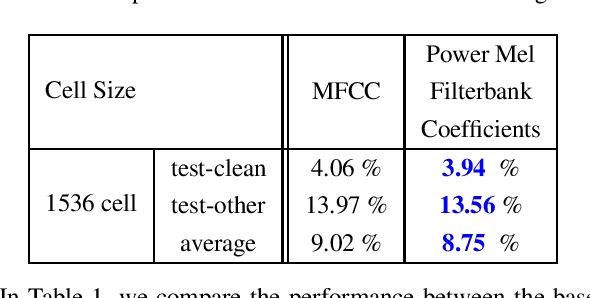
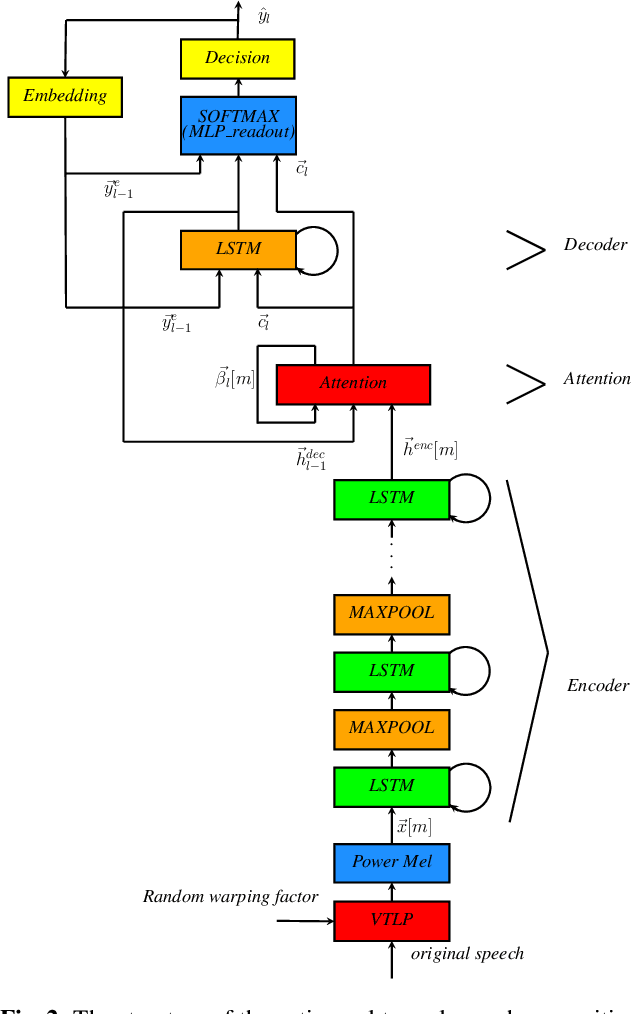
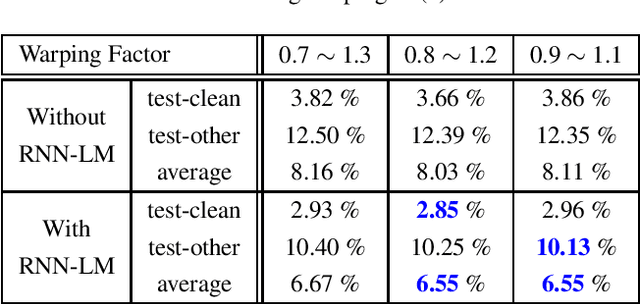
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.