 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Maximum Likelihood Training for Transducer-based Streaming Speech Recognition
Nov 26, 2024

Transducer neural networks have emerged as the mainstream approach for streaming automatic speech recognition (ASR), offering state-of-the-art performance in balancing accuracy and latency. In the conventional framework, streaming transducer models are trained to maximize the likelihood function based on non-streaming recursion rules. However, this approach leads to a mismatch between training and inference, resulting in the issue of deformed likelihood and consequently suboptimal ASR accuracy. We introduce a mathematical quantification of the gap between the actual likelihood and the deformed likelihood, namely forward variable causal compensation (FoCC). We also present its estimator, FoCCE, as a solution to estimate the exact likelihood. Through experiments on the LibriSpeech dataset, we show that FoCCE training improves the accuracy of the streaming transducers.
TiVaT: Joint-Axis Attention for Time Series Forecasting with Lead-Lag Dynamics
Oct 02, 2024Multivariate time series (MTS) forecasting plays a crucial role in various real-world applications, yet simultaneously capturing both temporal and inter-variable dependencies remains a challenge. Conventional Channel-Dependent (CD) models handle these dependencies separately, limiting their ability to model complex interactions such as lead-lag dynamics. To address these limitations, we propose TiVaT (Time-Variable Transformer), a novel architecture that integrates temporal and variate dependencies through its Joint-Axis (JA) attention mechanism. TiVaT's ability to capture intricate variate-temporal dependencies, including asynchronous interactions, is further enhanced by the incorporation of Distance-aware Time-Variable (DTV) Sampling, which reduces noise and improves accuracy through a learned 2D map that focuses on key interactions. TiVaT effectively models both temporal and variate dependencies, consistently delivering strong performance across diverse datasets. Notably, it excels in capturing complex patterns within multivariate time series, enabling it to surpass or remain competitive with state-of-the-art methods. This positions TiVaT as a new benchmark in MTS forecasting, particularly in handling datasets characterized by intricate and challenging dependencies.
Two-Pass End-to-End ASR Model Compression
Jan 08, 2022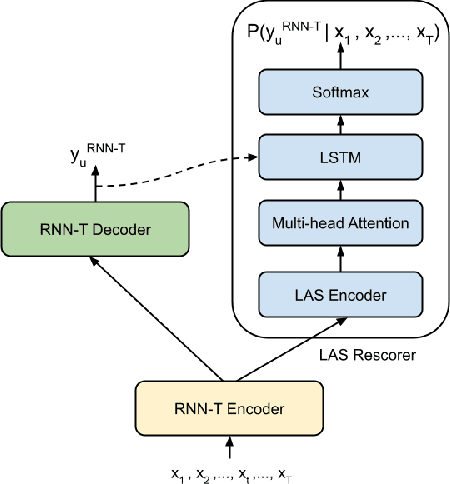

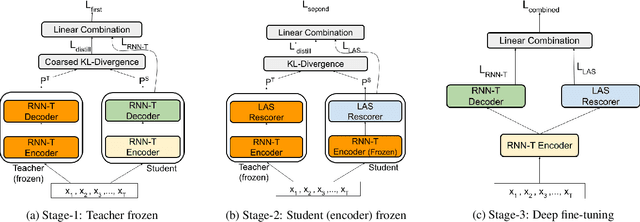
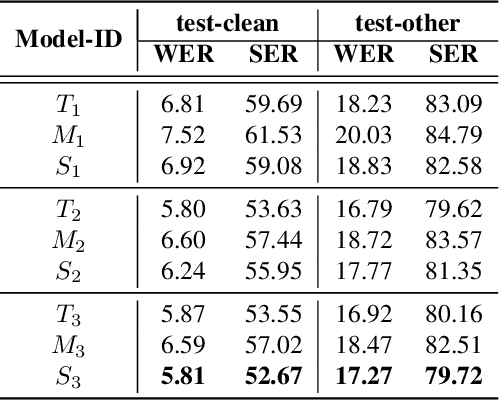
Speech recognition on smart devices is challenging owing to the small memory footprint. Hence small size ASR models are desirable. With the use of popular transducer-based models, it has become possible to practically deploy streaming speech recognition models on small devices [1]. Recently, the two-pass model [2] combining RNN-T and LAS modules has shown exceptional performance for streaming on-device speech recognition. In this work, we propose a simple and effective approach to reduce the size of the two-pass model for memory-constrained devices. We employ a popular knowledge distillation approach in three stages using the Teacher-Student training technique. In the first stage, we use a trained RNN-T model as a teacher model and perform knowledge distillation to train the student RNN-T model. The second stage uses the shared encoder and trains a LAS rescorer for student model using the trained RNN-T+LAS teacher model. Finally, we perform deep-finetuning for the student model with a shared RNN-T encoder, RNN-T decoder, and LAS rescorer. Our experimental results on standard LibriSpeech dataset show that our system can achieve a high compression rate of 55% without significant degradation in the WER compared to the two-pass teacher model.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 19, 2020



In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
Sequential Routing Framework: Fully Capsule Network-based Speech Recognition
Jul 23, 2020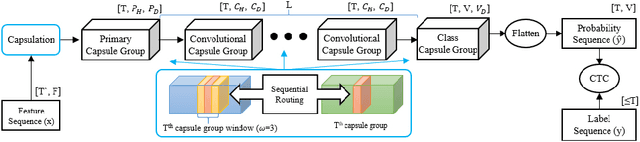
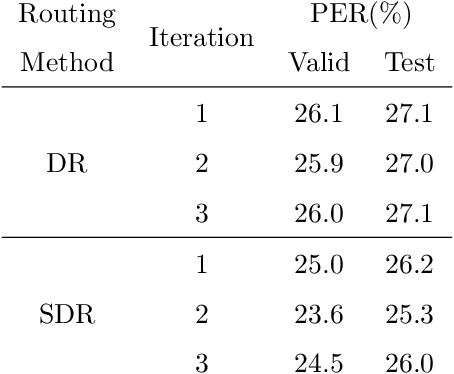
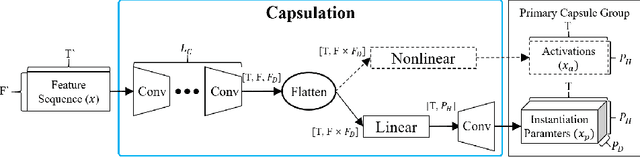
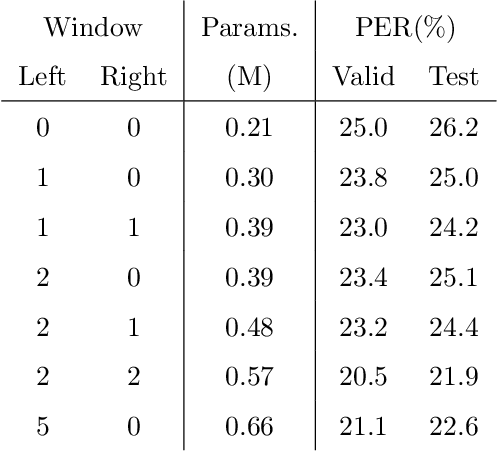
Capsule networks (CapsNets) have recently gotten attention as alternatives for convolutional neural networks (CNNs) with their greater hierarchical representation capabilities. In this paper, we introduce the sequential routing framework (SRF) which we believe is the first method to adapt a CapsNet-only structure to sequence-to-sequence recognition. In SRF, input sequences are capsulized then sliced by the window size. Each sliced window is classified to a label at the corresponding time through iterative routing mechanisms. Afterwards, training losses are computed using connectionist temporal classification (CTC). During routing, two kinds of information, learnable weights and iteration outputs are shared across the slices. By sharing the information, the required parameter numbers can be controlled by the given window size regardless of the length of sequences. Moreover, the method can minimize decoding speed degradation caused by the routing iterations since it can operate in a non-iterative manner at inference time without dropping accuracy. We empirically proved the validity of our method by performing phoneme sequence recognition tasks on the TIMIT corpus. The proposed method attains an 82.6% phoneme recognition rate. It is 0.8% more accurate than that of CNN-based CTC networks and on par with that of recurrent neural network transducers (RNN-Ts). Even more, the method requires less than half the parameters compared to the two architectures.
Attention based on-device streaming speech recognition with large speech corpus
Jan 02, 2020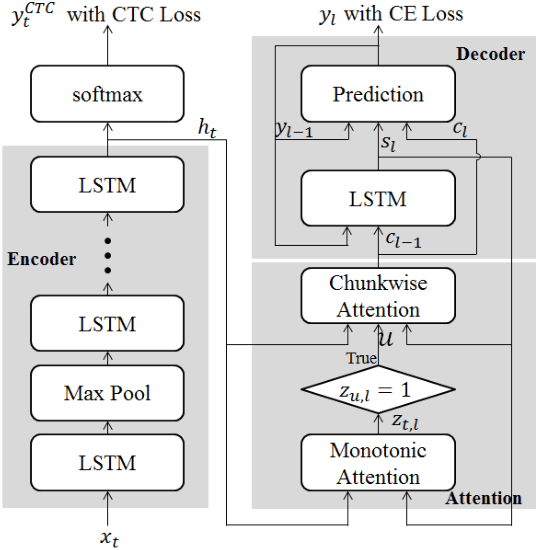
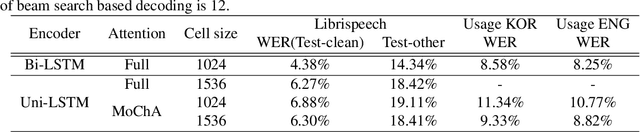

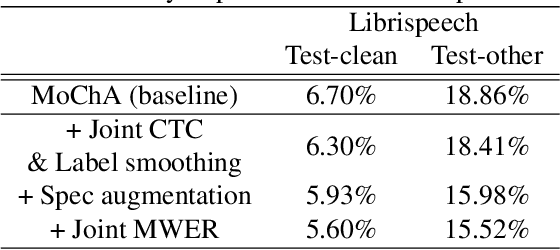
In this paper, we present a new on-device automatic speech recognition (ASR) system based on monotonic chunk-wise attention (MoChA) models trained with large (> 10K hours) corpus. We attained around 90% of a word recognition rate for general domain mainly by using joint training of connectionist temporal classifier (CTC) and cross entropy (CE) losses, minimum word error rate (MWER) training, layer-wise pre-training and data augmentation methods. In addition, we compressed our models by more than 3.4 times smaller using an iterative hyper low-rank approximation (LRA) method while minimizing the degradation in recognition accuracy. The memory footprint was further reduced with 8-bit quantization to bring down the final model size to lower than 39 MB. For on-demand adaptation, we fused the MoChA models with statistical n-gram models, and we could achieve a relatively 36% improvement on average in word error rate (WER) for target domains including the general domain.
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019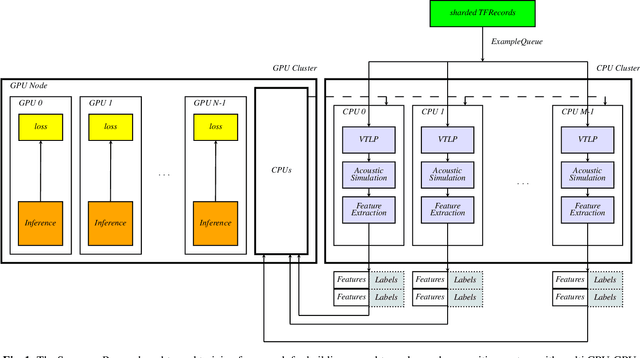
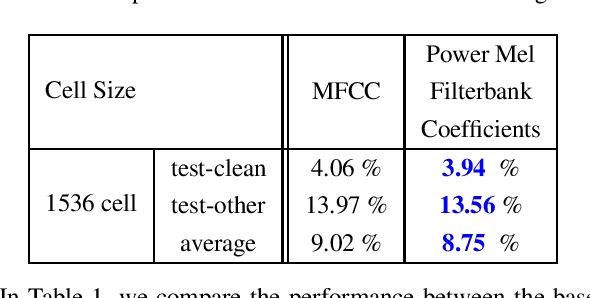
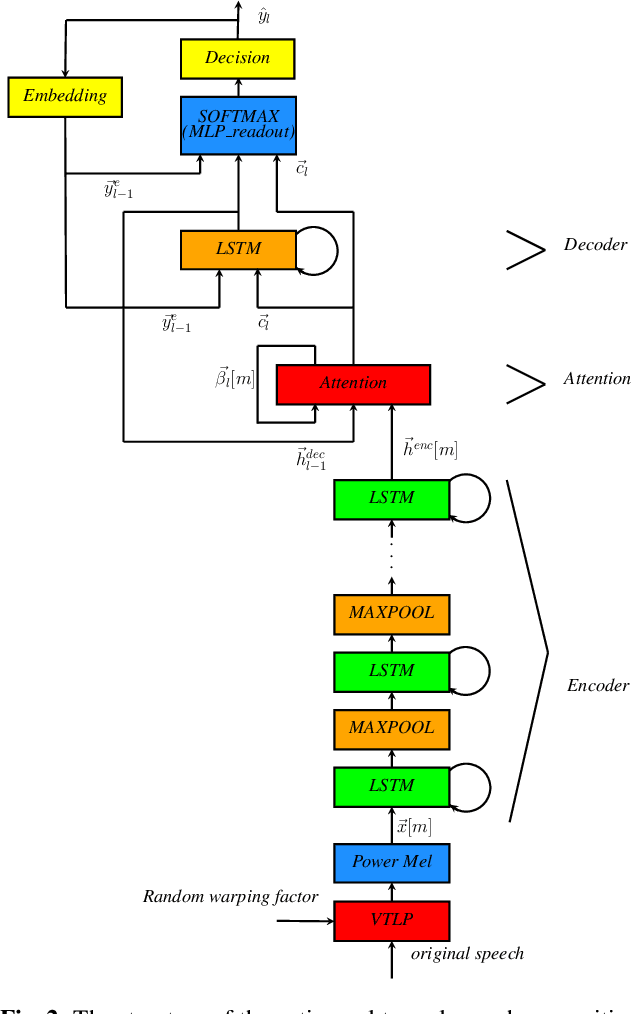
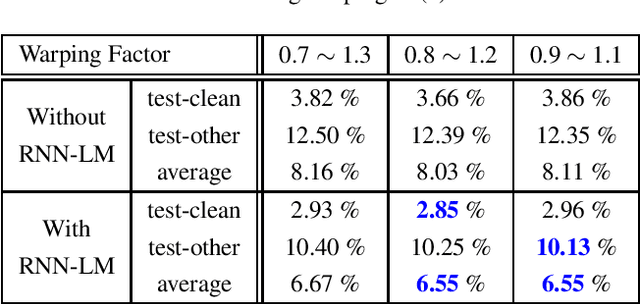
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.
Adversarial Video Compression Guided by Soft Edge Detection
Nov 26, 2018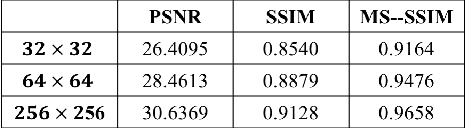
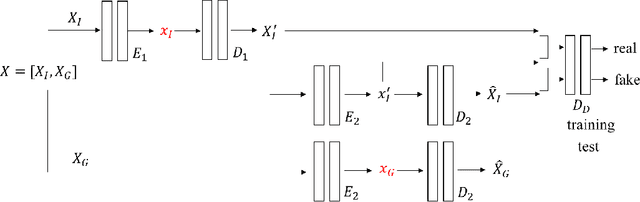
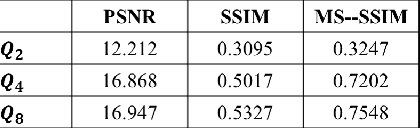
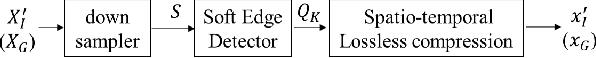
We propose a video compression framework using conditional Generative Adversarial Networks (GANs). We rely on two encoders: one that deploys a standard video codec and another which generates low-level maps via a pipeline of down-sampling, a newly devised soft edge detector, and a novel lossless compression scheme. For decoding, we use a standard video decoder as well as a neural network based one, which is trained using a conditional GAN. Recent "deep" approaches to video compression require multiple videos to pre-train generative networks to conduct interpolation. In contrast to this prior work, our scheme trains a generative decoder on pairs of a very limited number of key frames taken from a single video and corresponding low-level maps. The trained decoder produces reconstructed frames relying on a guidance of low-level maps, without any interpolation. Experiments on a diverse set of 131 videos demonstrate that our proposed GAN-based compression engine achieves much higher quality reconstructions at very low bitrates than prevailing standard codecs such as H.264 or HEVC.