 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Sensitivity for Tree Ensembles: A symbolic and compositional approach
May 13, 2026Decision tree ensembles (DTE) are a popular model for a wide range of AI classification tasks, used in multiple safety critical domains, and hence verifying properties on these models has been an active topic of study over the last decade. One such verification question is the problem of sensitivity, which asks, given a DTE, whether a small change in subset of features can lead to misclassification of the input. In this work, our focus is to build a quantitative notion of sensitivity, tailored to DTEs, by discretizing the input space of the model and enumerating the regions which are susceptible to sensitivity. We propose a novel algorithmic technique that can perform this computation efficiently, within a certified error and confidence bound. Our approach is based on encoding the problem as an algebraic decision diagram (ADD), and further splitting it into subproblems that can be solved efficiently and make the computation compositional and scalable. We evaluate the performance of our technique over benchmarks of varying size in terms of number of trees and depth, comparing it against the performance of model counters over the same problem encoding. Experimental results show that our tool XCount achieves significant speedup over other approaches and can scale well with the increasing sizes of the ensembles.
Data-Aware and Scalable Sensitivity Analysis for Decision Tree Ensembles
Feb 07, 2026Decision tree ensembles are widely used in critical domains, making robustness and sensitivity analysis essential to their trustworthiness. We study the feature sensitivity problem, which asks whether an ensemble is sensitive to a specified subset of features -- such as protected attributes -- whose manipulation can alter model predictions. Existing approaches often yield examples of sensitivity that lie far from the training distribution, limiting their interpretability and practical value. We propose a data-aware sensitivity framework that constrains the sensitive examples to remain close to the dataset, thereby producing realistic and interpretable evidence of model weaknesses. To this end, we develop novel techniques for data-aware search using a combination of mixed-integer linear programming (MILP) and satisfiability modulo theories (SMT) encodings. Our contributions are fourfold. First, we strengthen the NP-hardness result for sensitivity verification, showing it holds even for trees of depth 1. Second, we develop MILP-optimizations that significantly speed up sensitivity verification for single ensembles and for the first time can also handle multiclass tree ensembles. Third, we introduce a data-aware framework generating realistic examples close to the training distribution. Finally, we conduct an extensive experimental evaluation on large tree ensembles, demonstrating scalability to ensembles with up to 800 trees of depth 8, achieving substantial improvements over the state of the art. This framework provides a practical foundation for analyzing the reliability and fairness of tree-based models in high-stakes applications.
Verifying rich robustness properties for neural networks
Nov 10, 2025Robustness is a important problem in AI alignment and safety, with models such as neural networks being increasingly used in safety-critical systems. In the last decade, a large body of work has emerged on local robustness, i.e., checking if the decision of a neural network remains unchanged when the input is slightly perturbed. However, many of these approaches require specialized encoding and often ignore the confidence of a neural network on its output. In this paper, our goal is to build a generalized framework to specify and verify variants of robustness in neural network verification. We propose a specification framework using a simple grammar, which is flexible enough to capture most existing variants. This allows us to introduce new variants of robustness that take into account the confidence of the neural network in its outputs. Next, we develop a novel and powerful unified technique to verify all such variants in a homogeneous way, viz., by adding a few additional layers to the neural network. This enables us to use any state-of-the-art neural network verification tool, without having to tinker with the encoding within, while incurring an approximation error that we show is bounded. We perform an extensive experimental evaluation over a large suite of 8870 benchmarks having 138M parameters in a largest network, and show that we are able to capture a wide set of robustness variants and outperform direct encoding approaches by a significant margin.
A Sinkhorn Regularized Adversarial Network for Image Guided DEM Super-resolution using Frequency Selective Hybrid Graph Transformer
Sep 21, 2024Digital Elevation Model (DEM) is an essential aspect in the remote sensing (RS) domain to analyze various applications related to surface elevations. Here, we address the generation of high-resolution (HR) DEMs using HR multi-spectral (MX) satellite imagery as a guide by introducing a novel hybrid transformer model consisting of Densely connected Multi-Residual Block (DMRB) and multi-headed Frequency Selective Graph Attention (M-FSGA). To promptly regulate this process, we utilize the notion of discriminator spatial maps as the conditional attention to the MX guide. Further, we present a novel adversarial objective related to optimizing Sinkhorn distance with classical GAN. In this regard, we provide both theoretical and empirical substantiation of better performance in terms of vanishing gradient issues and numerical convergence. Based on our experiments on 4 different DEM datasets, we demonstrate both qualitative and quantitative comparisons with available baseline methods and show that the performance of our proposed model is superior to others with sharper details and minimal errors.
* 25 pages, 19 figures. arXiv admin note: substantial text overlap with arXiv:2311.16490
F2former: When Fractional Fourier Meets Deep Wiener Deconvolution and Selective Frequency Transformer for Image Deblurring
Sep 03, 2024Recent progress in image deblurring techniques focuses mainly on operating in both frequency and spatial domains using the Fourier transform (FT) properties. However, their performance is limited due to the dependency of FT on stationary signals and its lack of capability to extract spatial-frequency properties. In this paper, we propose a novel approach based on the Fractional Fourier Transform (FRFT), a unified spatial-frequency representation leveraging both spatial and frequency components simultaneously, making it ideal for processing non-stationary signals like images. Specifically, we introduce a Fractional Fourier Transformer (F2former), where we combine the classical fractional Fourier based Wiener deconvolution (F2WD) as well as a multi-branch encoder-decoder transformer based on a new fractional frequency aware transformer block (F2TB). We design F2TB consisting of a fractional frequency aware self-attention (F2SA) to estimate element-wise product attention based on important frequency components and a novel feed-forward network based on frequency division multiplexing (FM-FFN) to refine high and low frequency features separately for efficient latent clear image restoration. Experimental results for the cases of both motion deblurring as well as defocus deblurring show that the performance of our proposed method is superior to other state-of-the-art (SOTA) approaches.
Learning Decentralized Multi-Biped Control for Payload Transport
Jun 25, 2024
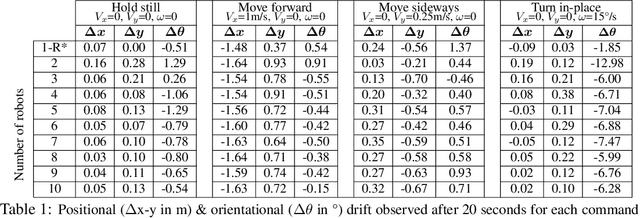


Payload transport over flat terrain via multi-wheel robot carriers is well-understood, highly effective, and configurable. In this paper, our goal is to provide similar effectiveness and configurability for transport over rough terrain that is more suitable for legs rather than wheels. For this purpose, we consider multi-biped robot carriers, where wheels are replaced by multiple bipedal robots attached to the carrier. Our main contribution is to design a decentralized controller for such systems that can be effectively applied to varying numbers and configurations of rigidly attached bipedal robots without retraining. We present a reinforcement learning approach for training the controller in simulation that supports transfer to the real world. Our experiments in simulation provide quantitative metrics showing the effectiveness of the approach over a wide variety of simulated transport scenarios. In addition, we demonstrate the controller in the real-world for systems composed of two and three Cassie robots. To our knowledge, this is the first example of a scalable multi-biped payload transport system.
Integrating Explanations in Learning LTL Specifications from Demonstrations
Apr 03, 2024This paper investigates whether recent advances in Large Language Models (LLMs) can assist in translating human explanations into a format that can robustly support learning Linear Temporal Logic (LTL) from demonstrations. Both LLMs and optimization-based methods can extract LTL specifications from demonstrations; however, they have distinct limitations. LLMs can quickly generate solutions and incorporate human explanations, but their lack of consistency and reliability hampers their applicability in safety-critical domains. On the other hand, optimization-based methods do provide formal guarantees but cannot process natural language explanations and face scalability challenges. We present a principled approach to combining LLMs and optimization-based methods to faithfully translate human explanations and demonstrations into LTL specifications. We have implemented a tool called Janaka based on our approach. Our experiments demonstrate the effectiveness of combining explanations with demonstrations in learning LTL specifications through several case studies.
CLiSA: A Hierarchical Hybrid Transformer Model using Orthogonal Cross Attention for Satellite Image Cloud Segmentation
Dec 01, 2023Clouds in optical satellite images are a major concern since their presence hinders the ability to carry accurate analysis as well as processing. Presence of clouds also affects the image tasking schedule and results in wastage of valuable storage space on ground as well as space-based systems. Due to these reasons, deriving accurate cloud masks from optical remote-sensing images is an important task. Traditional methods such as threshold-based, spatial filtering for cloud detection in satellite images suffer from lack of accuracy. In recent years, deep learning algorithms have emerged as a promising approach to solve image segmentation problems as it allows pixel-level classification and semantic-level segmentation. In this paper, we introduce a deep-learning model based on hybrid transformer architecture for effective cloud mask generation named CLiSA - Cloud segmentation via Lipschitz Stable Attention network. In this context, we propose an concept of orthogonal self-attention combined with hierarchical cross attention model, and we validate its Lipschitz stability theoretically and empirically. We design the whole setup under adversarial setting in presence of Lov\'asz-Softmax loss. We demonstrate both qualitative and quantitative outcomes for multiple satellite image datasets including Landsat-8, Sentinel-2, and Cartosat-2s. Performing comparative study we show that our model performs preferably against other state-of-the-art methods and also provides better generalization in precise cloud extraction from satellite multi-spectral (MX) images. We also showcase different ablation studies to endorse our choices corresponding to different architectural elements and objective functions.
SIRAN: Sinkhorn Distance Regularized Adversarial Network for DEM Super-resolution using Discriminative Spatial Self-attention
Nov 27, 2023



Digital Elevation Model (DEM) is an essential aspect in the remote sensing domain to analyze and explore different applications related to surface elevation information. In this study, we intend to address the generation of high-resolution DEMs using high-resolution multi-spectral (MX) satellite imagery by incorporating adversarial learning. To promptly regulate this process, we utilize the notion of polarized self-attention of discriminator spatial maps as well as introduce a Densely connected Multi-Residual Block (DMRB) module to assist in efficient gradient flow. Further, we present an objective function related to optimizing Sinkhorn distance with traditional GAN to improve the stability of adversarial learning. In this regard, we provide both theoretical and empirical substantiation of better performance in terms of vanishing gradient issues and numerical convergence. We demonstrate both qualitative and quantitative outcomes with available state-of-the-art methods. Based on our experiments on DEM datasets of Shuttle Radar Topographic Mission (SRTM) and Cartosat-1, we show that the proposed model performs preferably against other learning-based state-of-the-art methods. We also generate and visualize several high-resolution DEMs covering terrains with diverse signatures to show the performance of our model.
iPAL: A Machine Learning Based Smart Healthcare Framework For Automatic Diagnosis Of Attention Deficit/Hyperactivity Disorder (ADHD)
Feb 01, 2023
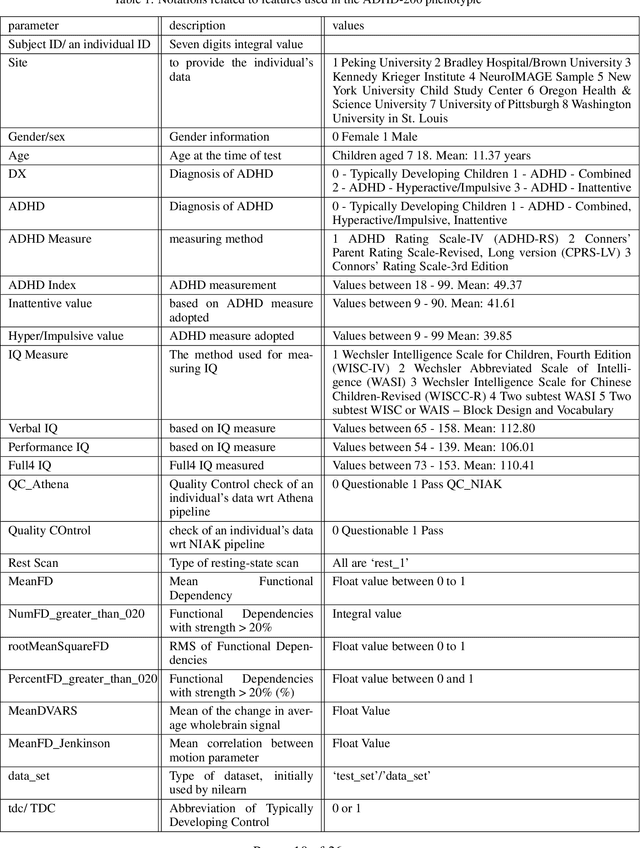
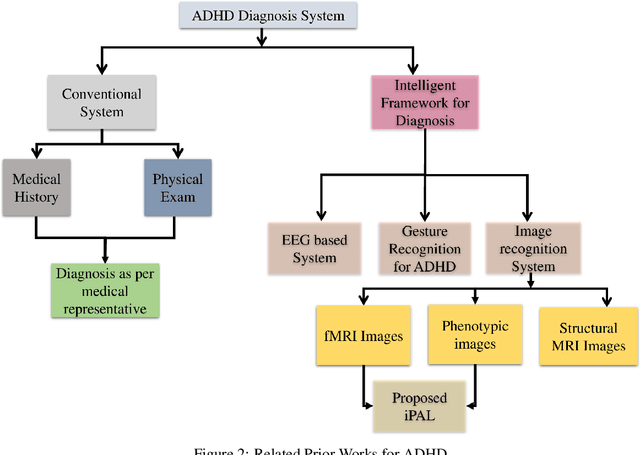

ADHD is a prevalent disorder among the younger population. Standard evaluation techniques currently use evaluation forms, interviews with the patient, and more. However, its symptoms are similar to those of many other disorders like depression, conduct disorder, and oppositional defiant disorder, and these current diagnosis techniques are not very effective. Thus, a sophisticated computing model holds the potential to provide a promising diagnosis solution to this problem. This work attempts to explore methods to diagnose ADHD using combinations of multiple established machine learning techniques like neural networks and SVM models on the ADHD200 dataset and explore the field of neuroscience. In this work, multiclass classification is performed on phenotypic data using an SVM model. The better results have been analyzed on the phenotypic data compared to other supervised learning techniques like Logistic regression, KNN, AdaBoost, etc. In addition, neural networks have been implemented on functional connectivity from the MRI data of a sample of 40 subjects provided to achieve high accuracy without prior knowledge of neuroscience. It is combined with the phenotypic classifier using the ensemble technique to get a binary classifier. It is further trained and tested on 400 out of 824 subjects from the ADHD200 data set and achieved an accuracy of 92.5% for binary classification The training and testing accuracy has been achieved upto 99% using ensemble classifier.