 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReTreVal: Reasoning Tree with Validation -- A Hybrid Framework for Enhanced LLM Multi-Step Reasoning
Jan 06, 2026Multi-step reasoning remains a key challenge for Large Language Models (LLMs), particularly in complex domains such as mathematics and creative writing. While recent approaches including ReAct, Reflexion, and Self-Refine improve reasoning through iterative refinement and reflection, they often lack structured exploration of alternative solution paths and persistent learning across problems. We propose ReTreVal (Reasoning Tree with Validation), a hybrid framework that integrates Tree-of-Thoughts exploration, self-refinement, LLM-based critique scoring, and reflexion memory to enable bounded and validated multi-step reasoning. ReTreVal constructs a structured reasoning tree with adaptive depth based on problem complexity, where each node undergoes iterative self-critique and refinement guided by explicit LLM-generated feedback. A dual validation mechanism evaluates reasoning quality, coherence, and correctness at each node while persistently storing insights from successful reasoning paths and failure patterns in a reflexion memory buffer, enabling cross-problem learning. Critique-based pruning retains only the top-k highest-scoring nodes at each level, controlling computational cost while preserving high-quality solution paths. We evaluate ReTreVal against ReAct, Reflexion, and Self-Refine across 500 mathematical problems and creative writing tasks using Qwen 2.5 7B as the underlying LLM, and demonstrate that ReTreVal consistently outperforms existing methods through its combination of structured exploration, critique-driven refinement, and cross-problem memory, making it particularly effective for tasks requiring exploratory reasoning, rigorous verification, and knowledge transfer.
iPAL: A Machine Learning Based Smart Healthcare Framework For Automatic Diagnosis Of Attention Deficit/Hyperactivity Disorder (ADHD)
Feb 01, 2023
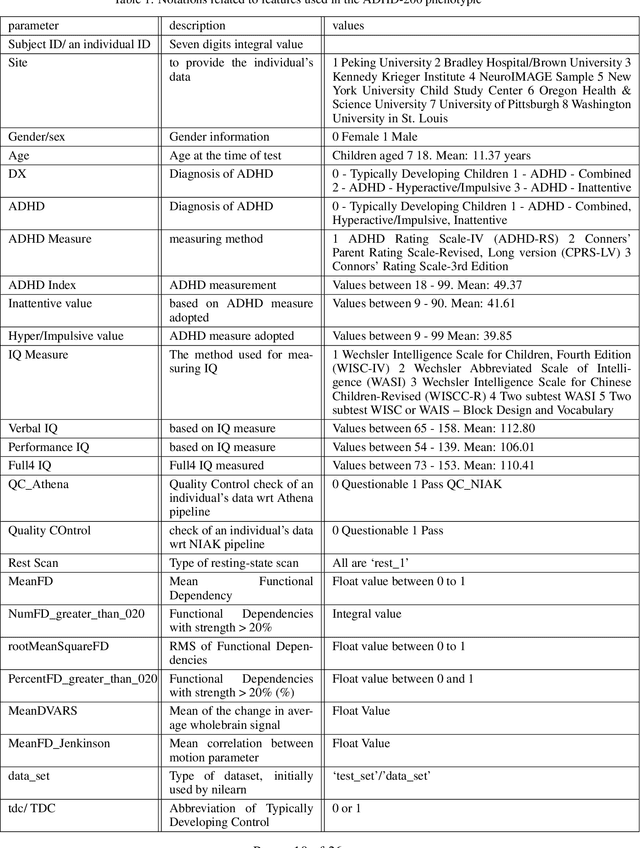

ADHD is a prevalent disorder among the younger population. Standard evaluation techniques currently use evaluation forms, interviews with the patient, and more. However, its symptoms are similar to those of many other disorders like depression, conduct disorder, and oppositional defiant disorder, and these current diagnosis techniques are not very effective. Thus, a sophisticated computing model holds the potential to provide a promising diagnosis solution to this problem. This work attempts to explore methods to diagnose ADHD using combinations of multiple established machine learning techniques like neural networks and SVM models on the ADHD200 dataset and explore the field of neuroscience. In this work, multiclass classification is performed on phenotypic data using an SVM model. The better results have been analyzed on the phenotypic data compared to other supervised learning techniques like Logistic regression, KNN, AdaBoost, etc. In addition, neural networks have been implemented on functional connectivity from the MRI data of a sample of 40 subjects provided to achieve high accuracy without prior knowledge of neuroscience. It is combined with the phenotypic classifier using the ensemble technique to get a binary classifier. It is further trained and tested on 400 out of 824 subjects from the ADHD200 data set and achieved an accuracy of 92.5% for binary classification The training and testing accuracy has been achieved upto 99% using ensemble classifier.
Dropout Inference with Non-Uniform Weight Scaling
Apr 27, 2022
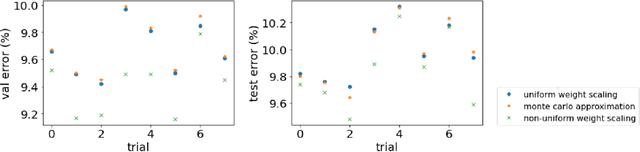

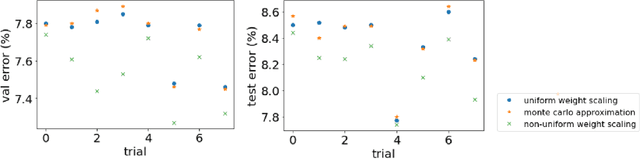
Dropout as regularization has been used extensively to prevent overfitting for training neural networks. During training, units and their connections are randomly dropped, which could be considered as sampling many different submodels from the original model. At test time, weight scaling and Monte Carlo approximation are two widely applied approaches to approximate the outputs. Both approaches work well practically when all submodels are low-bias complex learners. However, in this work, we demonstrate scenarios where some submodels behave closer to high-bias models and a non-uniform weight scaling is a better approximation for inference.
Design Rule Checking with a CNN Based Feature Extractor
Dec 21, 2020
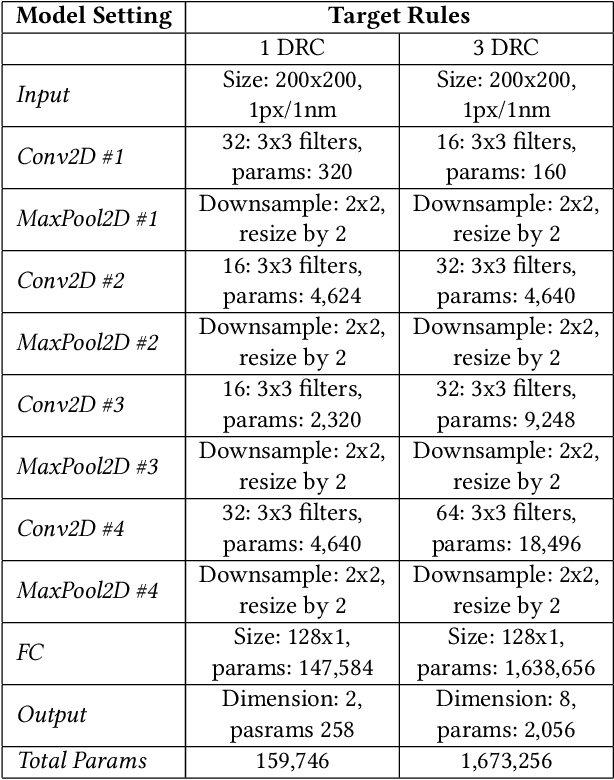
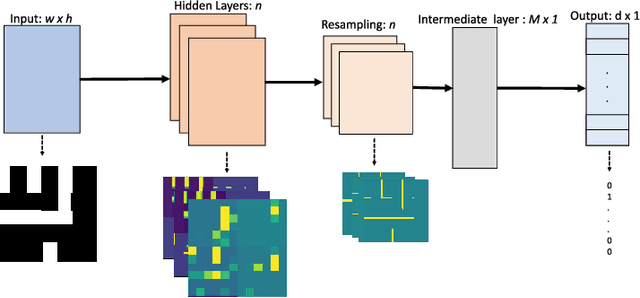
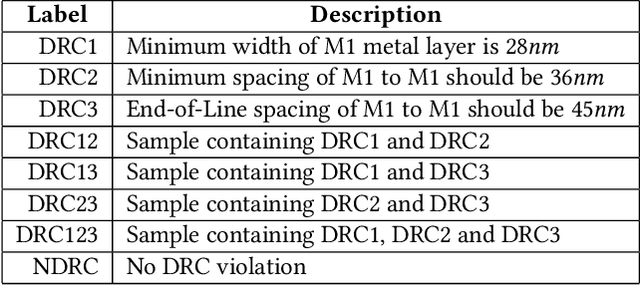
Design rule checking (DRC) is getting increasingly complex in advanced nodes technologies. It would be highly desirable to have a fast interactive DRC engine that could be used during layout. In this work, we establish the proof of feasibility for such an engine. The proposed model consists of a convolutional neural network (CNN) trained to detect DRC violations. The model was trained with artificial data that was derived from a set of $50$ SRAM designs. The focus in this demonstration was metal 1 rules. Using this solution, we can detect multiple DRC violations 32x faster than Boolean checkers with an accuracy of up to 92. The proposed solution can be easily expanded to a complete rule set.
ORL: Reinforcement Learning Benchmarks for Online Stochastic Optimization Problems
Dec 01, 2019
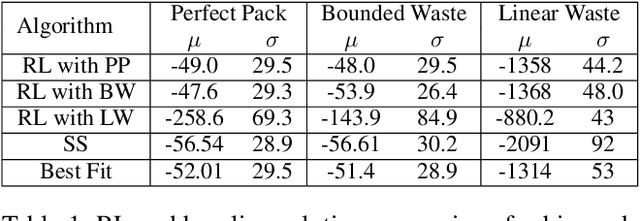
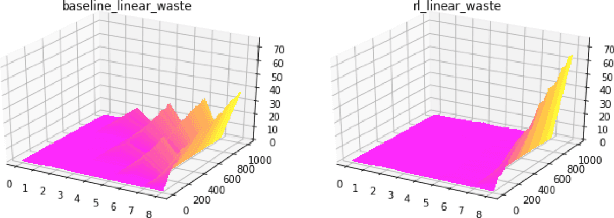
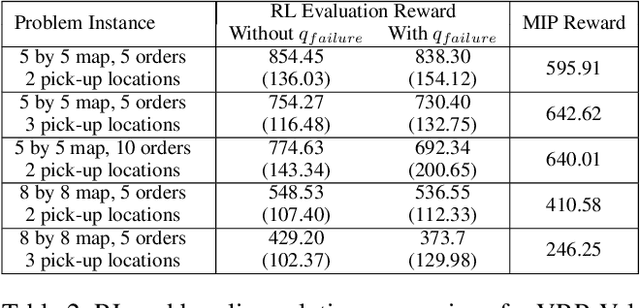
Reinforcement Learning (RL) has achieved state-of-the-art results in domains such as robotics and games. We build on this previous work by applying RL algorithms to a selection of canonical online stochastic optimization problems with a range of practical applications: Bin Packing, Newsvendor, and Vehicle Routing. While there is a nascent literature that applies RL to these problems, there are no commonly accepted benchmarks which can be used to compare proposed approaches rigorously in terms of performance, scale, or generalizability. This paper aims to fill that gap. For each problem we apply both standard approaches as well as newer RL algorithms and analyze results. In each case, the performance of the trained RL policy is competitive with or superior to the corresponding baselines, while not requiring much in the way of domain knowledge. This highlights the potential of RL in real-world dynamic resource allocation problems.
Regularizing deep networks using efficient layerwise adversarial training
May 29, 2018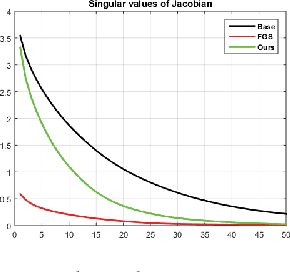
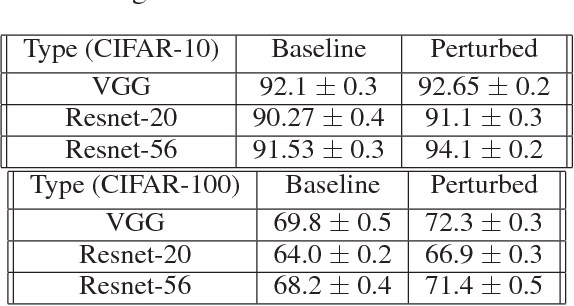
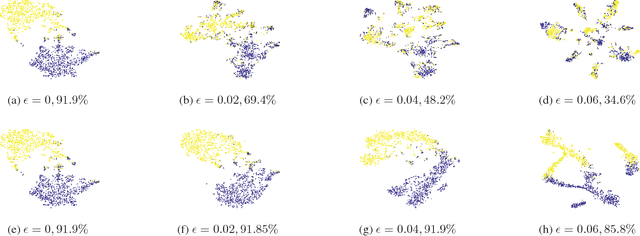
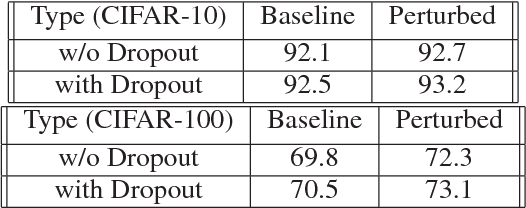
Adversarial training has been shown to regularize deep neural networks in addition to increasing their robustness to adversarial examples. However, its impact on very deep state of the art networks has not been fully investigated. In this paper, we present an efficient approach to perform adversarial training by perturbing intermediate layer activations and study the use of such perturbations as a regularizer during training. We use these perturbations to train very deep models such as ResNets and show improvement in performance both on adversarial and original test data. Our experiments highlight the benefits of perturbing intermediate layer activations compared to perturbing only the inputs. The results on CIFAR-10 and CIFAR-100 datasets show the merits of the proposed adversarial training approach. Additional results on WideResNets show that our approach provides significant improvement in classification accuracy for a given base model, outperforming dropout and other base models of larger size.
Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation
Apr 01, 2018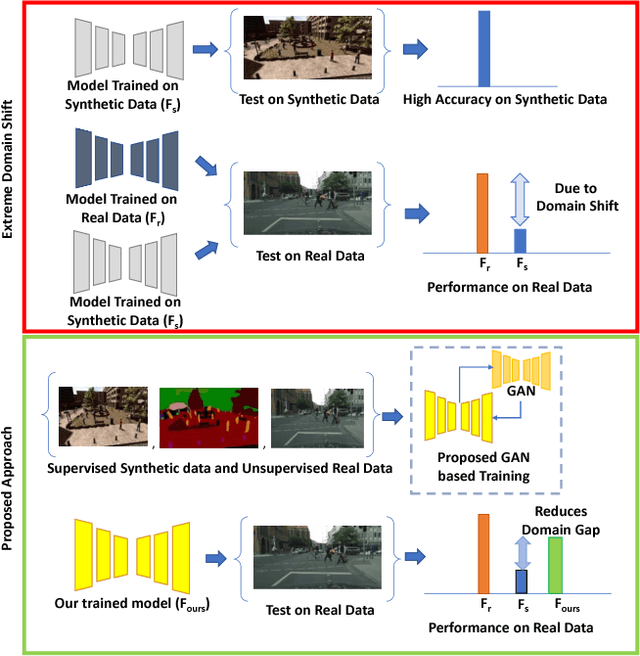

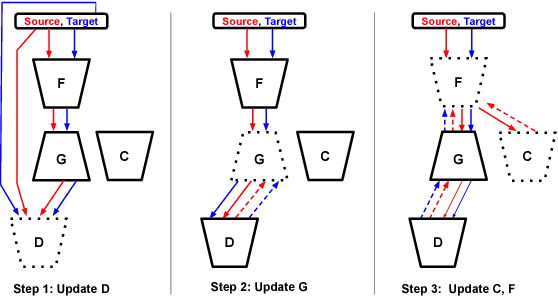
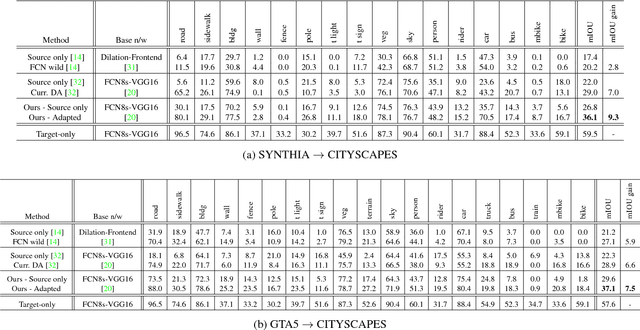
Visual Domain Adaptation is a problem of immense importance in computer vision. Previous approaches showcase the inability of even deep neural networks to learn informative representations across domain shift. This problem is more severe for tasks where acquiring hand labeled data is extremely hard and tedious. In this work, we focus on adapting the representations learned by segmentation networks across synthetic and real domains. Contrary to previous approaches that use a simple adversarial objective or superpixel information to aid the process, we propose an approach based on Generative Adversarial Networks (GANs) that brings the embeddings closer in the learned feature space. To showcase the generality and scalability of our approach, we show that we can achieve state of the art results on two challenging scenarios of synthetic to real domain adaptation. Additional exploratory experiments show that our approach: (1) generalizes to unseen domains and (2) results in improved alignment of source and target distributions.
Self corrective Perturbations for Semantic Segmentation and Classification
Aug 03, 2017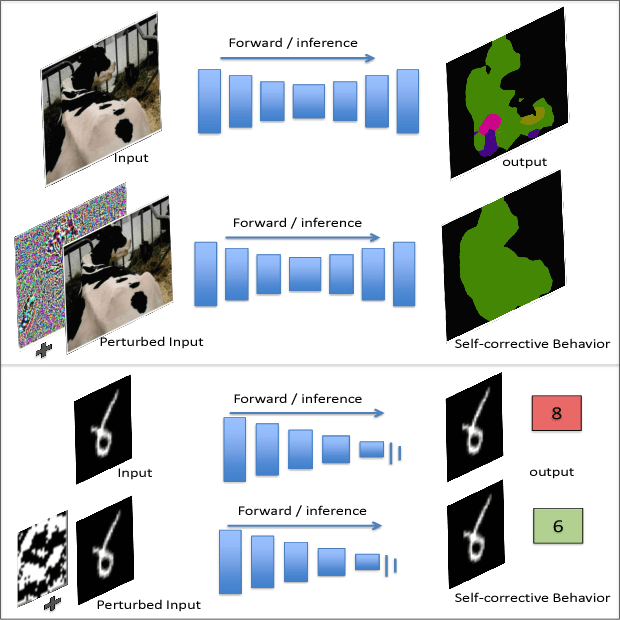

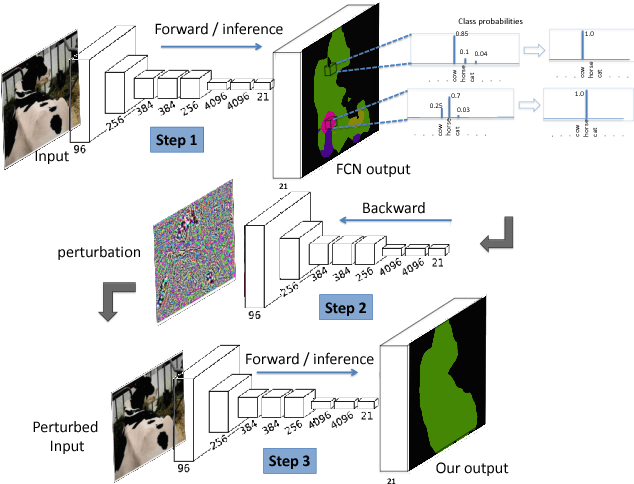

Convolutional Neural Networks have been a subject of great importance over the past decade and great strides have been made in their utility for producing state of the art performance in many computer vision problems. However, the behavior of deep networks is yet to be fully understood and is still an active area of research. In this work, we present an intriguing behavior: pre-trained CNNs can be made to improve their predictions by structurally perturbing the input. We observe that these perturbations - referred as Guided Perturbations - enable a trained network to improve its prediction performance without any learning or change in network weights. We perform various ablative experiments to understand how these perturbations affect the local context and feature representations. Furthermore, we demonstrate that this idea can improve performance of several existing approaches on semantic segmentation and scene labeling tasks on the PASCAL VOC dataset and supervised classification tasks on MNIST and CIFAR10 datasets.