 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Off-the-Shelves Large Multi-Modal Models do for Dynamic Scene Graph Generation?
Mar 20, 2025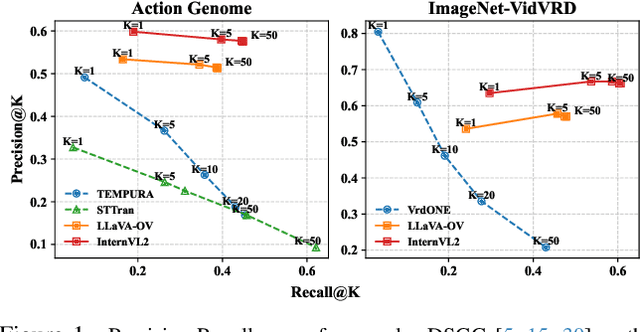
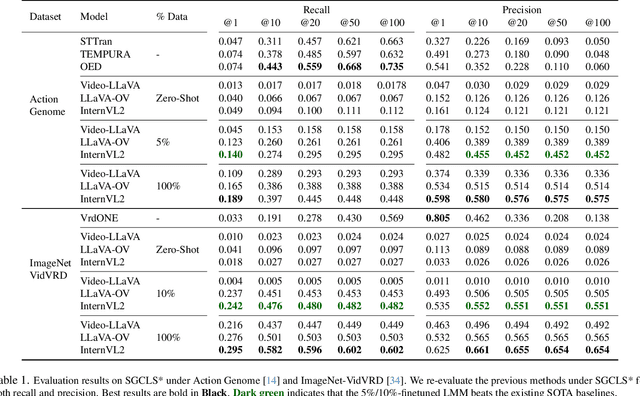

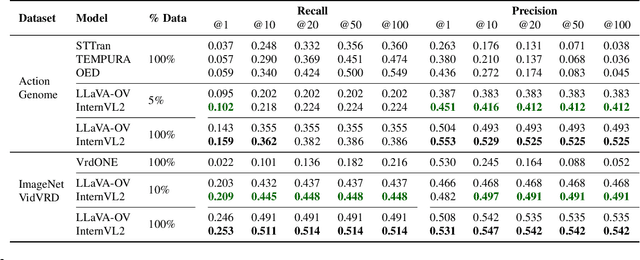
Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in computer vision. While existing approaches often focus on sophisticated architectural design and solely use recall during evaluation, we take a closer look at their predicted scene graphs and discover three critical issues with existing DSGG methods: severe precision-recall trade-off, lack of awareness on triplet importance, and inappropriate evaluation protocols. On the other hand, recent advances of Large Multimodal Models (LMMs) have shown great capabilities in video understanding, yet they have not been tested on fine-grained, frame-wise understanding tasks like DSGG. In this work, we conduct the first systematic analysis of Video LMMs for performing DSGG. Without relying on sophisticated architectural design, we show that LMMs with simple decoder-only structure can be turned into State-of-the-Art scene graph generators that effectively overcome the aforementioned issues, while requiring little finetuning (5-10% training data).
FSViewFusion: Few-Shots View Generation of Novel Objects
Mar 13, 2024



Novel view synthesis has observed tremendous developments since the arrival of NeRFs. However, Nerf models overfit on a single scene, lacking generalization to out of distribution objects. Recently, diffusion models have exhibited remarkable performance on introducing generalization in view synthesis. Inspired by these advancements, we explore the capabilities of a pretrained stable diffusion model for view synthesis without explicit 3D priors. Specifically, we base our method on a personalized text to image model, Dreambooth, given its strong ability to adapt to specific novel objects with a few shots. Our research reveals two interesting findings. First, we observe that Dreambooth can learn the high level concept of a view, compared to arguably more complex strategies which involve finetuning diffusions on large amounts of multi-view data. Second, we establish that the concept of a view can be disentangled and transferred to a novel object irrespective of the original object's identify from which the views are learnt. Motivated by this, we introduce a learning strategy, FSViewFusion, which inherits a specific view through only one image sample of a single scene, and transfers the knowledge to a novel object, learnt from few shots, using low rank adapters. Through extensive experiments we demonstrate that our method, albeit simple, is efficient in generating reliable view samples for in the wild images. Code and models will be released.
Task-Agnostic Robust Representation Learning
Mar 15, 2022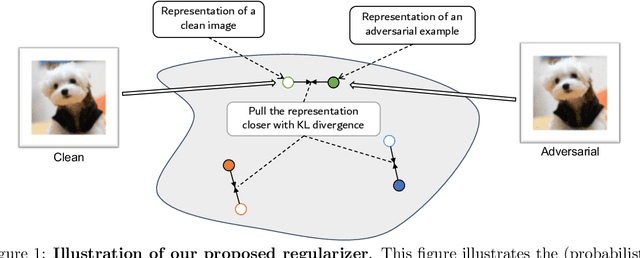
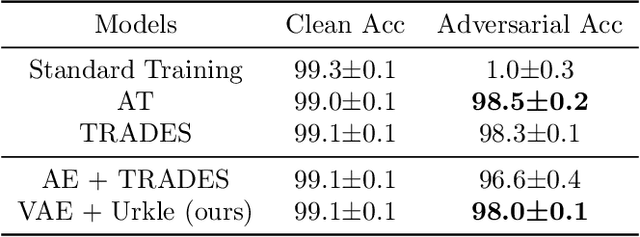

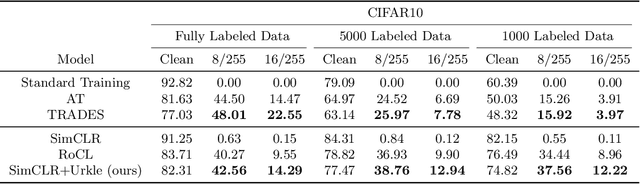
It has been reported that deep learning models are extremely vulnerable to small but intentionally chosen perturbations of its input. In particular, a deep network, despite its near-optimal accuracy on the clean images, often mis-classifies an image with a worst-case but humanly imperceptible perturbation (so-called adversarial examples). To tackle this problem, a great amount of research has been done to study the training procedure of a network to improve its robustness. However, most of the research so far has focused on the case of supervised learning. With the increasing popularity of self-supervised learning methods, it is also important to study and improve the robustness of their resulting representation on the downstream tasks. In this paper, we study the problem of robust representation learning with unlabeled data in a task-agnostic manner. Specifically, we first derive an upper bound on the adversarial loss of a prediction model (which is based on the learned representation) on any downstream task, using its loss on the clean data and a robustness regularizer. Moreover, the regularizer is task-independent, thus we propose to minimize it directly during the representation learning phase to make the downstream prediction model more robust. Extensive experiments show that our method achieves preferable adversarial performance compared to relevant baselines.
Regularizing deep networks using efficient layerwise adversarial training
May 29, 2018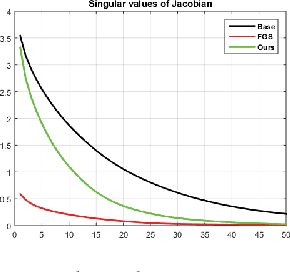
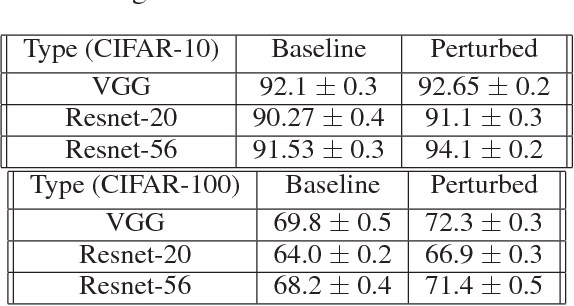
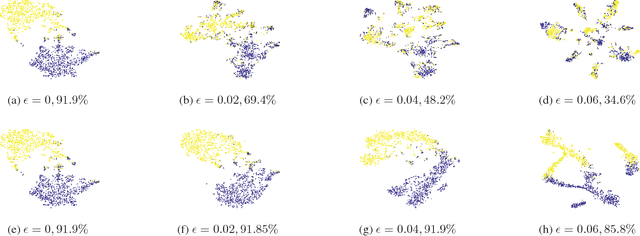
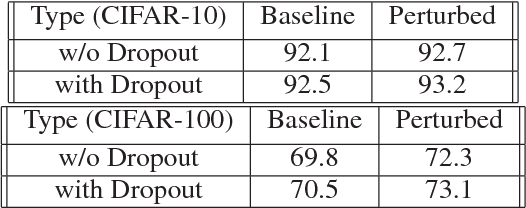
Adversarial training has been shown to regularize deep neural networks in addition to increasing their robustness to adversarial examples. However, its impact on very deep state of the art networks has not been fully investigated. In this paper, we present an efficient approach to perform adversarial training by perturbing intermediate layer activations and study the use of such perturbations as a regularizer during training. We use these perturbations to train very deep models such as ResNets and show improvement in performance both on adversarial and original test data. Our experiments highlight the benefits of perturbing intermediate layer activations compared to perturbing only the inputs. The results on CIFAR-10 and CIFAR-100 datasets show the merits of the proposed adversarial training approach. Additional results on WideResNets show that our approach provides significant improvement in classification accuracy for a given base model, outperforming dropout and other base models of larger size.
DCAN: Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation
Apr 16, 2018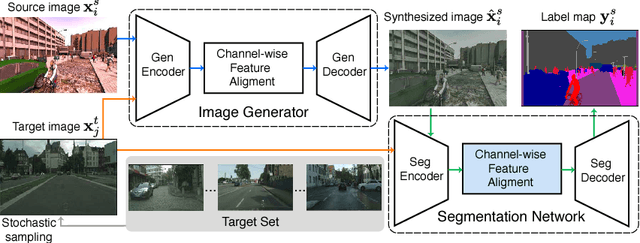



Harvesting dense pixel-level annotations to train deep neural networks for semantic segmentation is extremely expensive and unwieldy at scale. While learning from synthetic data where labels are readily available sounds promising, performance degrades significantly when testing on novel realistic data due to domain discrepancies. We present Dual Channel-wise Alignment Networks (DCAN), a simple yet effective approach to reduce domain shift at both pixel-level and feature-level. Exploring statistics in each channel of CNN feature maps, our framework performs channel-wise feature alignment, which preserves spatial structures and semantic information, in both an image generator and a segmentation network. In particular, given an image from the source domain and unlabeled samples from the target domain, the generator synthesizes new images on-the-fly to resemble samples from the target domain in appearance and the segmentation network further refines high-level features before predicting semantic maps, both of which leverage feature statistics of sampled images from the target domain. Unlike much recent and concurrent work relying on adversarial training, our framework is lightweight and easy to train. Extensive experiments on adapting models trained on synthetic segmentation benchmarks to real urban scenes demonstrate the effectiveness of the proposed framework.
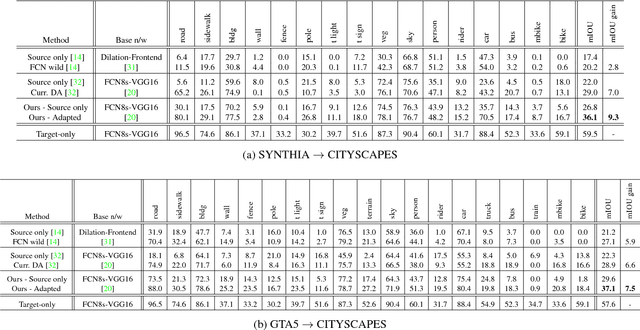
Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation
Apr 01, 2018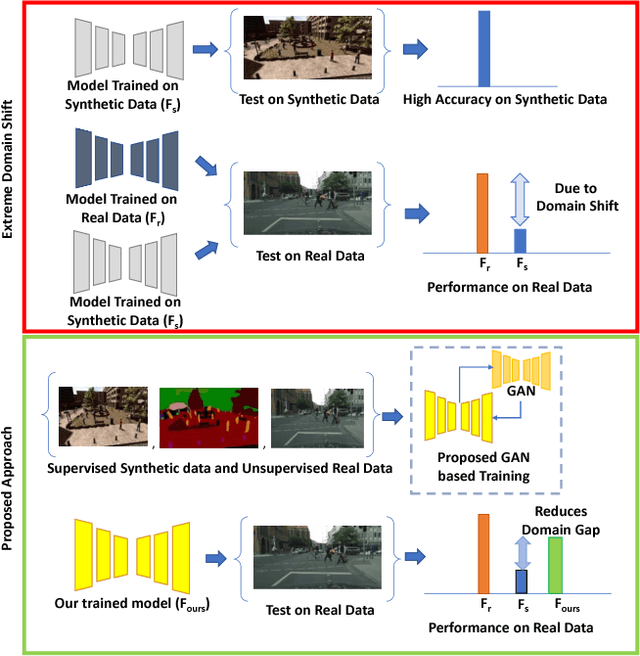

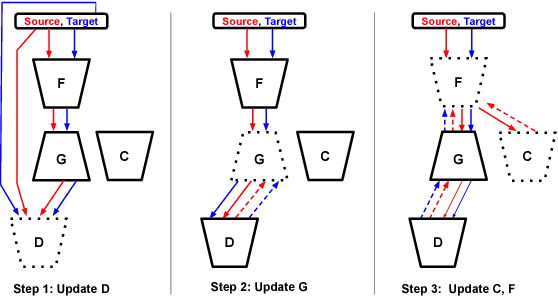
Visual Domain Adaptation is a problem of immense importance in computer vision. Previous approaches showcase the inability of even deep neural networks to learn informative representations across domain shift. This problem is more severe for tasks where acquiring hand labeled data is extremely hard and tedious. In this work, we focus on adapting the representations learned by segmentation networks across synthetic and real domains. Contrary to previous approaches that use a simple adversarial objective or superpixel information to aid the process, we propose an approach based on Generative Adversarial Networks (GANs) that brings the embeddings closer in the learned feature space. To showcase the generality and scalability of our approach, we show that we can achieve state of the art results on two challenging scenarios of synthetic to real domain adaptation. Additional exploratory experiments show that our approach: (1) generalizes to unseen domains and (2) results in improved alignment of source and target distributions.
Self corrective Perturbations for Semantic Segmentation and Classification
Aug 03, 2017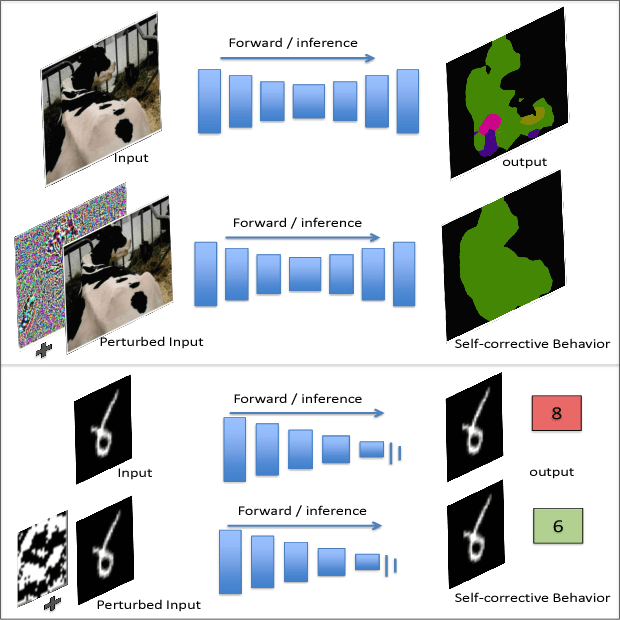

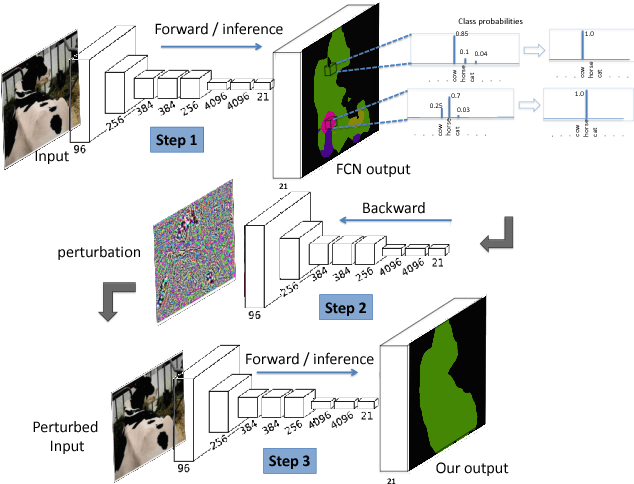

Convolutional Neural Networks have been a subject of great importance over the past decade and great strides have been made in their utility for producing state of the art performance in many computer vision problems. However, the behavior of deep networks is yet to be fully understood and is still an active area of research. In this work, we present an intriguing behavior: pre-trained CNNs can be made to improve their predictions by structurally perturbing the input. We observe that these perturbations - referred as Guided Perturbations - enable a trained network to improve its prediction performance without any learning or change in network weights. We perform various ablative experiments to understand how these perturbations affect the local context and feature representations. Furthermore, we demonstrate that this idea can improve performance of several existing approaches on semantic segmentation and scene labeling tasks on the PASCAL VOC dataset and supervised classification tasks on MNIST and CIFAR10 datasets.
A Reinforcement Learning Approach to the View Planning Problem
Nov 18, 2016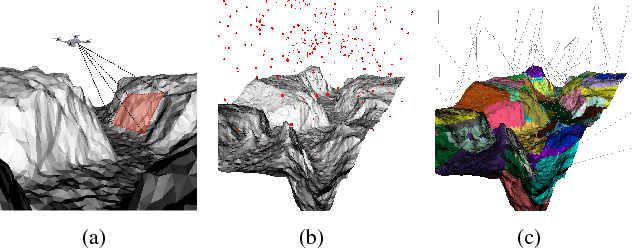
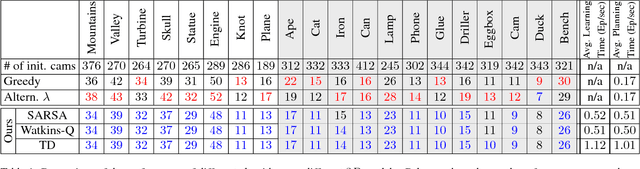

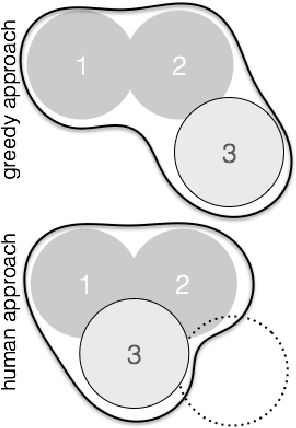
We present a Reinforcement Learning (RL) solution to the view planning problem (VPP), which generates a sequence of view points that are capable of sensing all accessible area of a given object represented as a 3D model. In doing so, the goal is to minimize the number of view points, making the VPP a class of set covering optimization problem (SCOP). The SCOP is NP-hard, and the inapproximability results tell us that the greedy algorithm provides the best approximation that runs in polynomial time. In order to find a solution that is better than the greedy algorithm, (i) we introduce a novel score function by exploiting the geometry of the 3D model, (ii) we model an intuitive human approach to VPP using this score function, and (iii) we cast VPP as a Markovian Decision Process (MDP), and solve the MDP in RL framework using well-known RL algorithms. In particular, we use SARSA, Watkins-Q and TD with function approximation to solve the MDP. We compare the results of our method with the baseline greedy algorithm in an extensive set of test objects, and show that we can out-perform the baseline in almost all cases.