 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Off-the-Shelves Large Multi-Modal Models do for Dynamic Scene Graph Generation?
Mar 20, 2025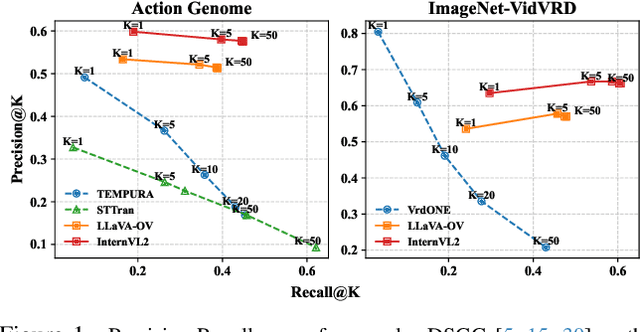
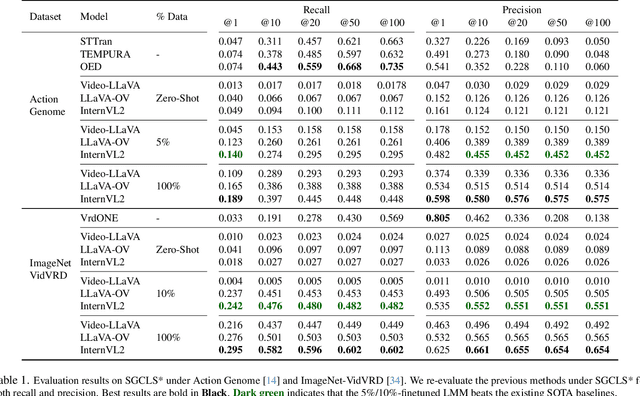

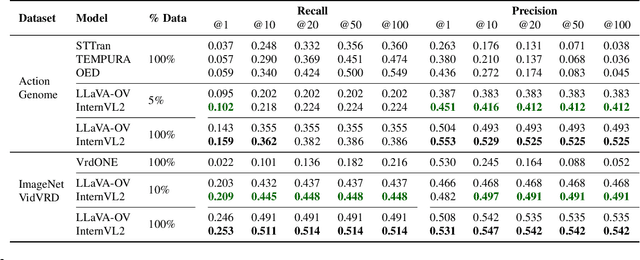
Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in computer vision. While existing approaches often focus on sophisticated architectural design and solely use recall during evaluation, we take a closer look at their predicted scene graphs and discover three critical issues with existing DSGG methods: severe precision-recall trade-off, lack of awareness on triplet importance, and inappropriate evaluation protocols. On the other hand, recent advances of Large Multimodal Models (LMMs) have shown great capabilities in video understanding, yet they have not been tested on fine-grained, frame-wise understanding tasks like DSGG. In this work, we conduct the first systematic analysis of Video LMMs for performing DSGG. Without relying on sophisticated architectural design, we show that LMMs with simple decoder-only structure can be turned into State-of-the-Art scene graph generators that effectively overcome the aforementioned issues, while requiring little finetuning (5-10% training data).
Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023



Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.